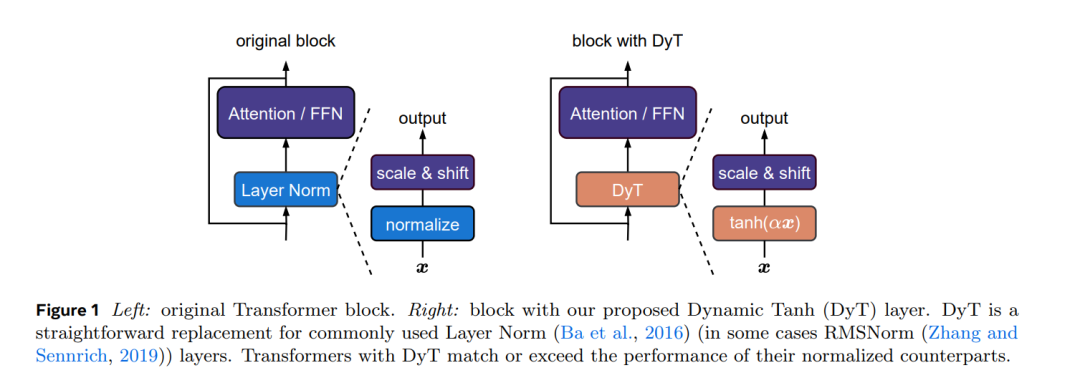
归一化层在现代神经网络中无处不在,长期以来被认为是不可或缺的。本研究表明,无需归一化的 Transformer 可以通过一种极其简单的技术实现相同甚至更好的性能。我们提出了一种称为动态 Tanh(DyT)的逐元素操作,即 DyT(x) = tanh(αx),作为 Transformer 中归一化层的替代方案。DyT 的灵感来源于观察到 Transformer 中的层归一化通常会产生类似 Tanh 的 S 形输入-输出映射。通过引入 DyT,无需归一化的 Transformer 能够匹配甚至超越使用归一化的模型性能,且大多数情况下无需超参数调优。我们在多种场景中验证了使用 DyT 的 Transformer 的有效性,包括识别与生成任务、监督与自监督学习,以及计算机视觉与语言模型。这些发现挑战了传统观点,即归一化层在现代神经网络中是必不可少的,并为深度网络中归一化层的作用提供了新的见解。https://arxiv.org/pdf/2503.106221 引言在过去的十年中,归一化层已经巩固了其作为现代神经网络最基本组件之一的地位。这一切可以追溯到 2015 年批量归一化(Batch Normalization)的发明(Ioffe 和 Szegedy,2015),它显著加快了视觉识别模型的收敛速度并提升了性能,随后迅速在几年内得到广泛应用。自那时起,针对不同网络架构或领域,许多归一化层的变体被提出(Ba 等,2016;Ulyanov 等,2016;Wu 和 He,2018;Zhang 和 Sennrich,2019)。如今,几乎所有现代网络都使用归一化层,其中层归一化(Layer Normalization,LN)(Ba 等,2016)是最受欢迎的之一,尤其是在主流的 Transformer 架构中(Vaswani 等,2017;Dosovitskiy 等,2020)。归一化层的广泛采用主要归功于其在优化中的实际益处(Santurkar 等,2018;Bjorck 等,2018)。除了能够实现更好的结果外,它们还有助于加速和稳定收敛。随着神经网络变得越来越宽和越来越深,这种必要性变得愈发关键(Brock 等,2021a;Huang 等,2023)。因此,归一化层被广泛认为是深度网络有效训练的关键,甚至可以说是不可或缺的。这一观点在近年来新架构的设计中得到了微妙印证:尽管许多研究尝试替换注意力或卷积层(Tolstikhin 等,2021;Gu 和 Dao,2023;Sun 等,2024;Feng 等,2024),但几乎总是保留了归一化层。本文通过为 Transformer 中的归一化层引入一种简单的替代方案,挑战了这一观点。我们的探索始于对层归一化(LN)行为的观察:LN 层将其输入映射到输出时,呈现出类似 Tanh 的 S 形曲线,既对输入激活值进行缩放,又抑制了极端值。受此启发,我们提出了一种称为动态 Tanh(DyT)的逐元素操作,定义为:DyT(x) = tanh(αx),其中 α 是一个可学习参数。该操作旨在通过 α 学习适当的缩放因子,并通过有界的 Tanh 函数抑制极端值,从而模拟 LN 的行为。值得注意的是,与归一化层不同,DyT 无需计算激活统计量即可实现这两种效果。使用 DyT 非常简单,如图 1 所示:我们直接在视觉和语言 Transformer 等架构中用 DyT 替换现有的归一化层。我们通过实验证明,使用 DyT 的模型能够在广泛的设置中稳定训练并实现较高的最终性能,且通常无需对原始架构的训练超参数进行调整。我们的工作挑战了“归一化层对于训练现代神经网络不可或缺”的观念,并为归一化层的特性提供了实证见解。此外,初步测量表明,DyT 提高了训练和推理速度,使其成为面向效率的网络设计的候选方案。