

在对大规模视频-语言模型(VLMs)进行预训练的过程中,尽管在各种下游视频-语言任务中展示了巨大的潜力,现有的VLMs仍可能存在一些常见的局限性,例如粗粒度的跨模态对齐、时间动态的欠建模以及视频-语言视图的脱节。在本研究中,我们针对这些问题提出了一种细粒度的结构时空对齐学习方法(即Finsta),以增强VLMs的表现。
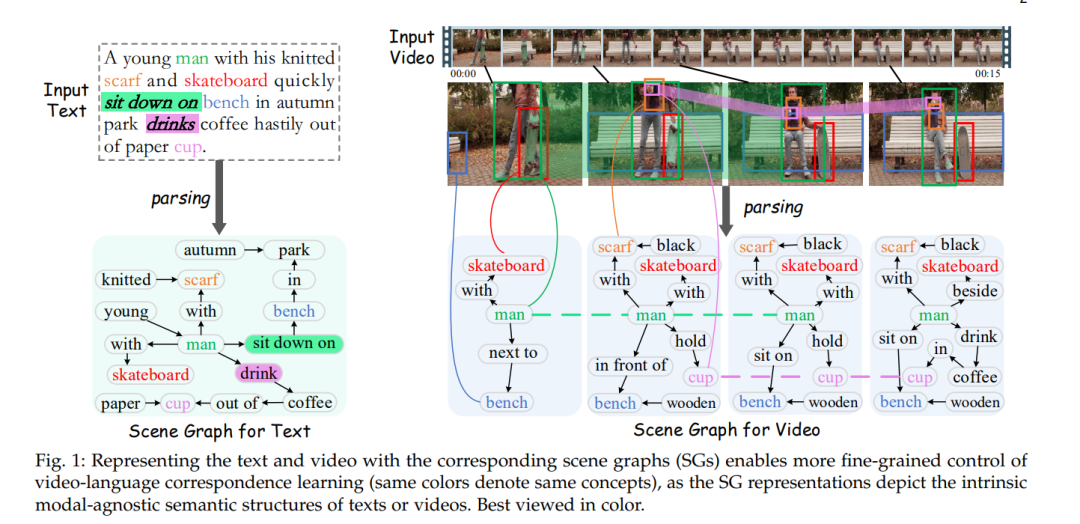
首先,我们使用细粒度的场景图(SG)结构来表示输入文本和视频,并将这两种模态统一到一个整体场景图(HSG)中,以桥接两种模态之间的差异。然后,我们构建了一个基于SG的框架,其中文本场景图(TSG)通过图Transformer进行编码,而视频动态场景图(DSG)和整体场景图(HSG)则通过一种新颖的循环图Transformer进行空间和时间特征传播。此外,我们还设计了一种时空高斯差分图Transformer,以增强对物体在空间和时间维度上变化的感知。
接下来,基于TSG和DSG的细粒度结构特征,我们分别进行以物体为中心的空间对齐和以谓词为中心的时间对齐,从而在空间性和时间性上增强视频-语言的基础。我们将该方法设计为一个即插即用的系统,可以集成到现有的经过良好训练的VLMs中以进一步增强表示能力,而无需从头开始训练或在下游应用中依赖场景图注释。
在6个代表性的视频-语言建模任务和12个数据集的标准和长视频场景中,Finsta在细调和零样本设置中持续改进了现有的13个高性能VLMs,并显著刷新了当前的最先进的终端任务性能。
https://www.zhuanzhi.ai/paper/221d21a6861c4635f618bc1cc84cfbd0
成为VIP会员查看完整内容
相关内容
Arxiv
32+阅读 · 2023年4月19日
Arxiv
151+阅读 · 2023年4月7日
Arxiv
60+阅读 · 2023年4月4日
Arxiv
103+阅读 · 2023年3月29日
相关主题
相关VIP内容
相关资讯
相关论文
Arxiv
32+阅读 · 2023年4月19日
Arxiv
151+阅读 · 2023年4月7日
Arxiv
60+阅读 · 2023年4月4日
Arxiv
103+阅读 · 2023年3月29日