IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)是计算机视觉领域的顶级国际会议,CCF A类会议。CVPR2025将于2025年6月11日至15日在美国田纳西州纳什维尔举办。CVPR 2025 共有13,008 份投稿,录用2878篇,录取率为 22.1%。

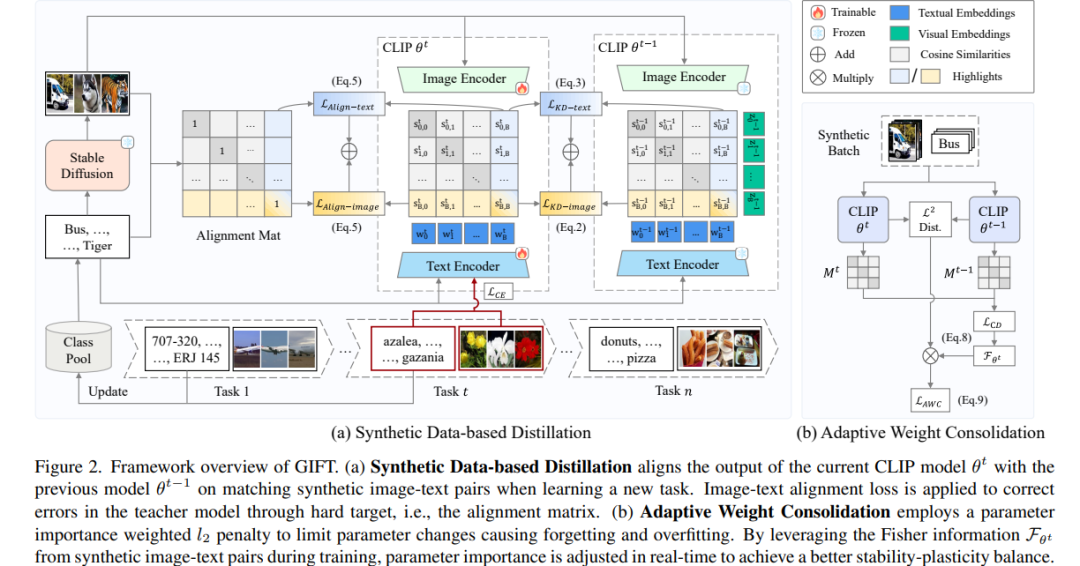
- 合成数据是持续视觉-语言模型的优雅礼物

- 《通过DPO缓解大型视觉-语言模型中的幻觉问题:策略内数据是关键》

幻觉问题仍然是大型视觉-语言模型(Large Vision-Language Models, LVLMs)面临的主要挑战。直接偏好优化(Direct Preference Optimization, DPO)作为一种解决幻觉问题的简单方法,近年来受到越来越多的关注。它通过从反映同一提示和图像下响应中幻觉严重程度的偏好对中直接学习,从而缓解幻觉问题。 然而,现有研究中不同的数据构建方法带来了显著的性能差异。我们发现了一个关键因素:结果在很大程度上取决于构建的数据是否与 DPO 的初始(参考)策略在策略内对齐。理论分析表明,从策略外数据中学习会受到更新策略与参考策略之间 KL 散度的阻碍。从数据集分布的角度,我们系统地总结了现有采用 DPO 解决幻觉问题的算法的固有缺陷。为了缓解这些问题,我们提出了策略内对齐(On-Policy Alignment, OPA)-DPO 框架,该框架独特地利用专家反馈来纠正幻觉响应,并以策略内方式对齐原始响应和专家修订的响应。值得注意的是,仅使用 4.8k 数据,OPA-DPO 在 LLaVA-1.5-7B 模型上实现了进一步的幻觉率降低:在 AMBER 基准上降低了 13.26%,在 Object-Hal 基准上降低了 5.39%,优于之前使用 16k 样本训练的最先进算法。我们的实现代码已开源:https://github.com/zhyang2226/OPA-DPO。 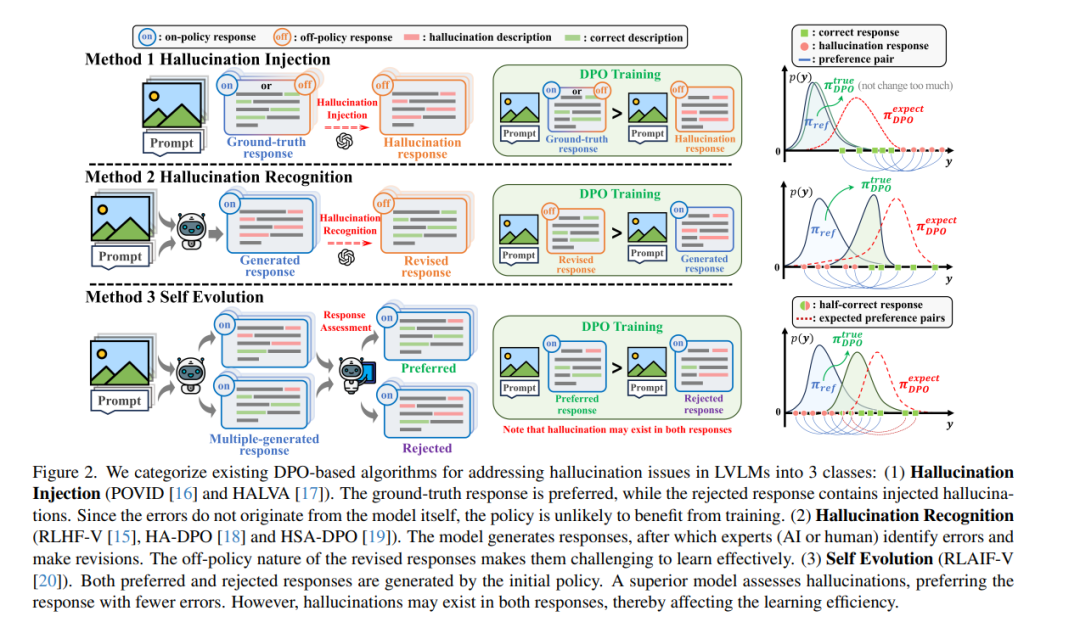

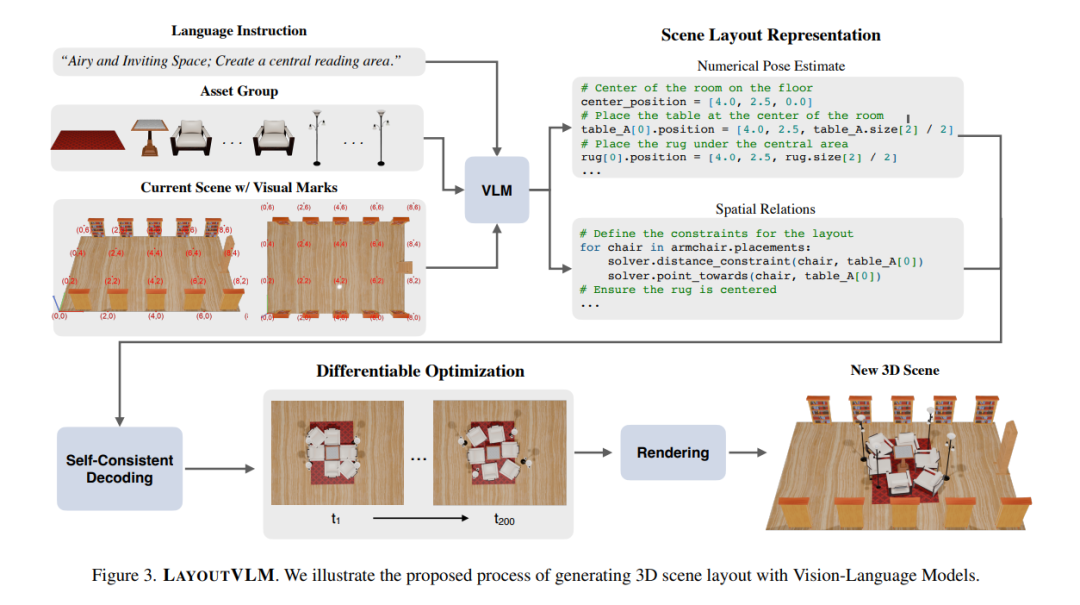
空间推理是人类认知的基本组成部分,使我们能够直观地理解和操作三维空间中的物体。尽管基础模型在某些基准测试中表现出色,但在根据开放式语言指令在空间中排列物体等 3D 推理任务上,尤其是在密集且物理受限的环境中,它们仍然面临挑战。我们提出了 LAYOUTVLM,这是一个利用视觉-语言模型(Vision-Language Models, VLMs)语义知识的框架和场景布局表示,并支持可微优化以确保物理合理性。LAYOUTVLM 使用 VLMs 从视觉标记的图像中生成两种相互增强的表示,并通过自洽的解码过程来改进 VLMs 的空间规划能力。实验表明,LAYOUTVLM 解决了现有基于 LLM 和约束方法的局限性,生成的 3D 布局在物理上更合理,并且更符合输入语言指令的语义意图。我们还证明,使用从现有场景数据集中提取的场景布局表示对 VLMs 进行微调,可以提高其推理性能。
- 《BiomedCoOp:为生物医学视觉-语言模型学习提示》

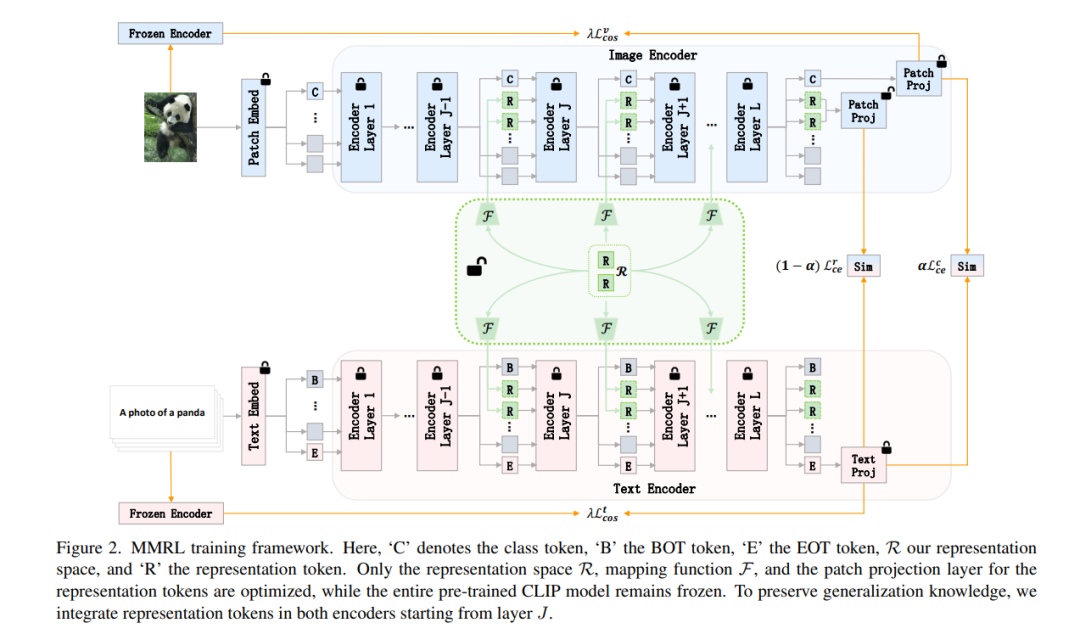
近年来,视觉-语言模型(Vision-Language Models, VLMs),如 CLIP,在视觉任务的自监督表示学习中取得了显著成功。然而,将 VLMs 有效适应下游应用仍然具有挑战性,因为其准确性通常依赖于耗时且需要专业知识的提示工程,而全模型微调则成本高昂。这一问题在生物医学图像中尤为突出,与自然图像不同,生物医学图像通常面临标注数据集有限、图像对比不直观以及视觉特征微妙等挑战。最近的提示学习技术,如上下文优化(Context Optimization, CoOp),旨在解决这些问题,但在泛化能力方面仍显不足。同时,针对生物医学图像分析的提示学习探索仍然非常有限。在本研究中,我们提出了 BiomedCoOp,一种新颖的提示学习框架,能够高效地适应 BiomedCLIP,以实现准确且高度泛化的少样本生物医学图像分类。我们的方法通过利用与大型语言模型(LLMs)的平均提示集合的语义一致性,以及基于统计的提示选择策略进行知识蒸馏,实现了有效的提示上下文学习。我们在 9 种模态和 10 个器官的 11 个医学数据集上对现有最先进方法进行了全面验证,结果表明我们的框架在准确性和泛化能力方面均取得了显著提升。代码已公开:https://github.com/HealthX-Lab/BiomedCoOp。