IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)是计算机视觉领域的顶级国际会议,CCF A类会议。CVPR2025将于2025年6月11日至15日在美国田纳西州纳什维尔举办。CVPR 2025 共有13,008 份投稿,录用2878篇,录取率为 22.1%。

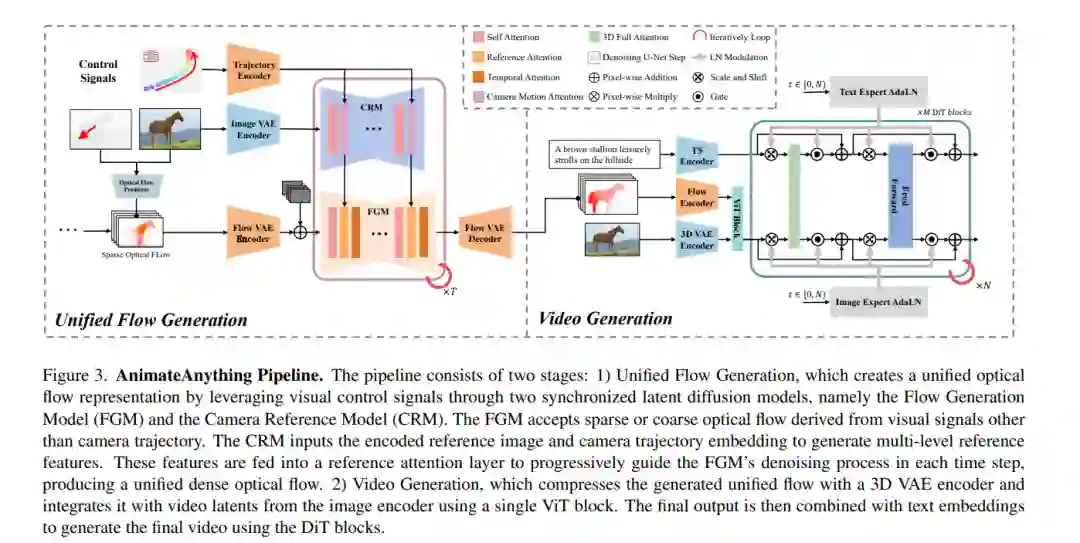
- AnimateAnything: 一致且可控的视频生成动画

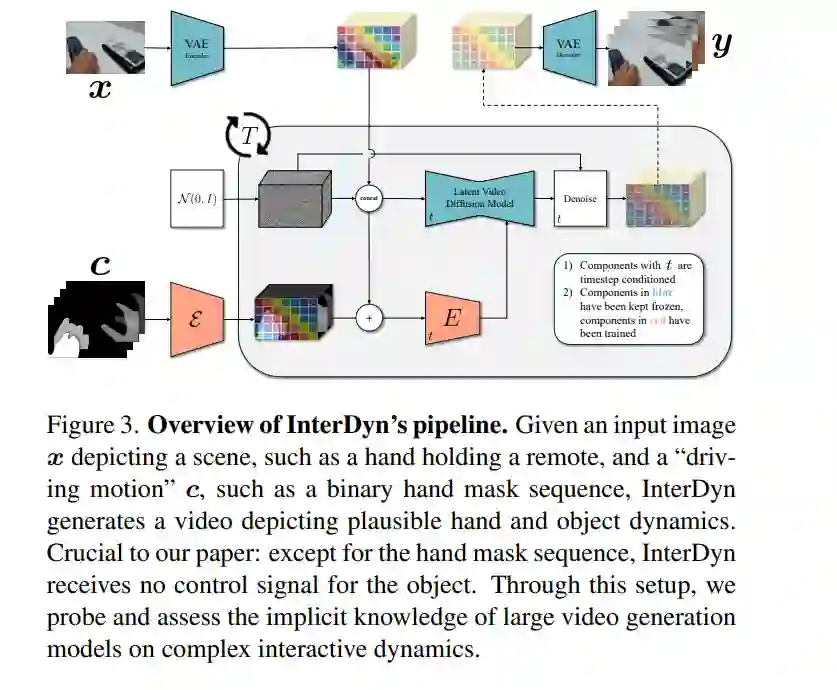
- InterDyn:基于视频扩散模型的可控交互式动态生成

预测交互物体的动态对于人类和智能系统都至关重要。然而,现有方法仅限于简化的实验场景,缺乏对复杂现实环境的泛化能力。近年来,生成模型的进展使得基于干预的状态转移预测成为可能,但这些方法通常只关注生成单一的未来状态,而忽略了由交互产生的连续动态过程。为填补这一空白,我们提出了 InterDyn,这是一种新颖的框架,能够在给定初始帧和编码驱动物体或运动者动作的控制信号的情况下,生成交互动态的视频。我们的核心观点是,大规模视频生成模型既可以作为神经渲染器,也可以作为隐式物理“模拟器”,因为它们已经从大规模视频数据中学习了交互动态。为了有效利用这一能力,我们引入了一种交互控制机制,将视频生成过程与驱动实体的运动相结合。定性实验表明,InterDyn 能够生成逼真且时间一致的复杂物体交互视频,同时能够泛化到未见过的物体。定量评估显示,InterDyn 在性能上优于专注于静态状态转移的基线方法。这项工作凸显了利用视频生成模型作为隐式物理引擎的潜力。代码和训练模型将发布于:https://interdyn.is.tue.mpg.de/。 https://arxiv.org/pdf/2412.11785
- WeGen:一种统一的多模态交互生成模型,支持聊天式创作
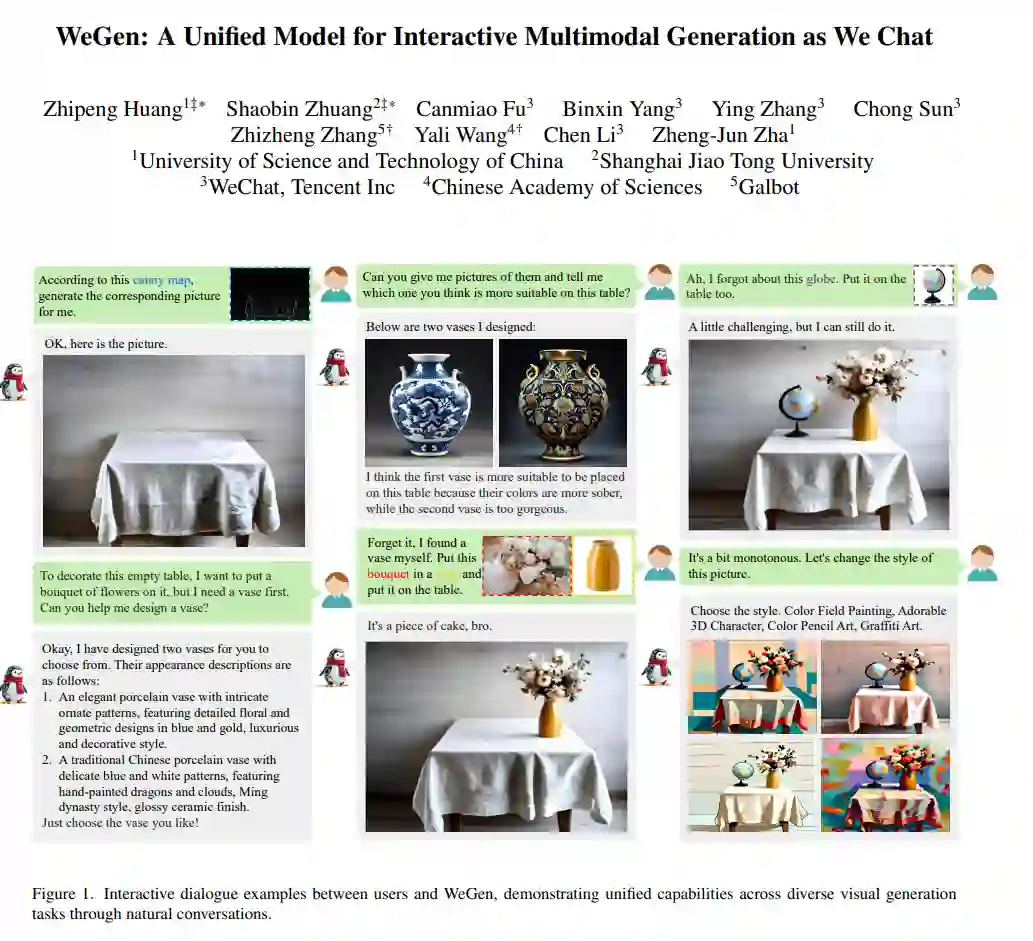
现有的多模态生成模型难以胜任合格的设计助手角色,因为它们通常在指令不够详细时难以生成富有想象力的输出,或者无法保持与提供参考内容的一致性。为此,我们提出了 WeGen,这是一种将多模态生成与理解统一起来,并促进它们在迭代生成中相互作用的模型。它能够为不够详细的指令生成具有高度创造性的多样化结果,并能够在与用户的聊天过程中逐步优化先前的生成结果,或根据指令整合参考内容中的特定部分。在此过程中,它能够保持用户已满意部分的一致性。为实现这一目标,我们构建了一个大规模数据集,该数据集从互联网视频中提取,包含丰富的物体动态信息,并通过先进的基础模型自动标注动态描述。这两种信息被交织成单一序列,使 WeGen 能够学习一致性感知生成,即在生成指定动态的同时,保持未指定内容与指令的一致性。此外,我们引入了一种提示自我重写机制,以增强生成多样性。大量实验证明了 WeGen 在统一多模态理解与生成方面的有效性,并展示了其在各种视觉生成基准测试中的最先进性能。这些结果也表明,WeGen 有潜力成为用户友好的设计助手。代码和模型将发布于:https://github.com/hzphzp/WeGen。 https://arxiv.org/pdf/2503.01115
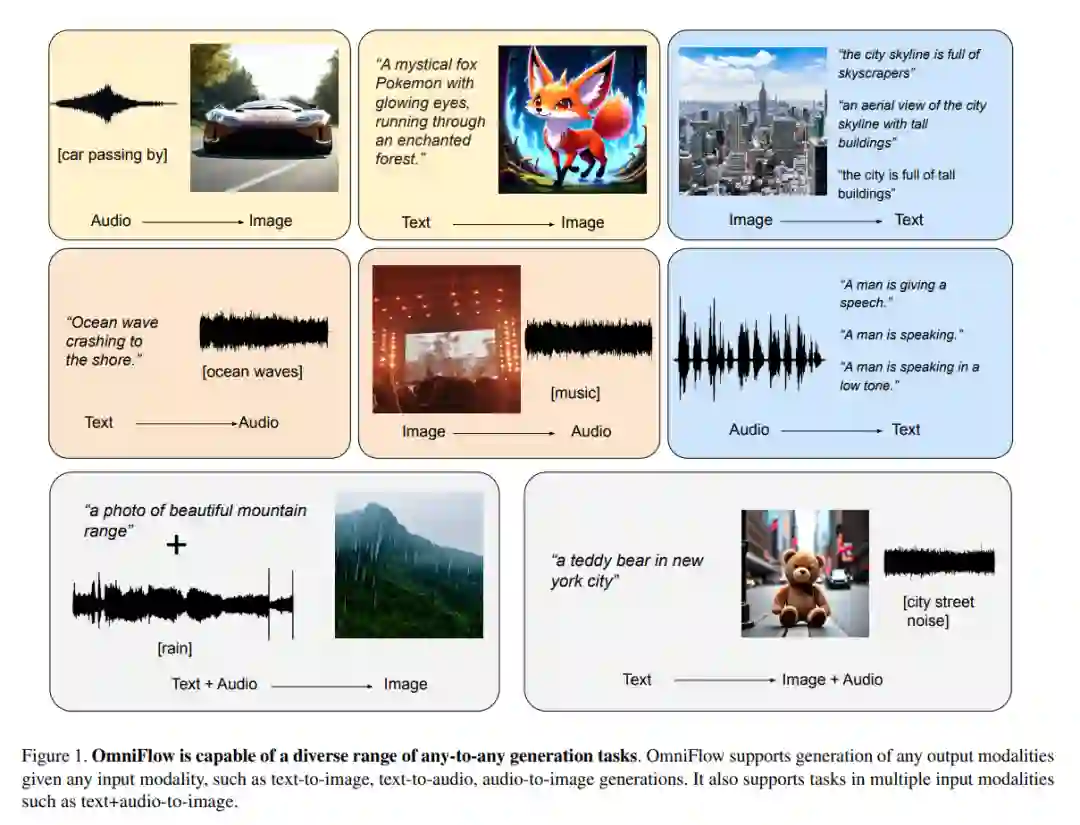
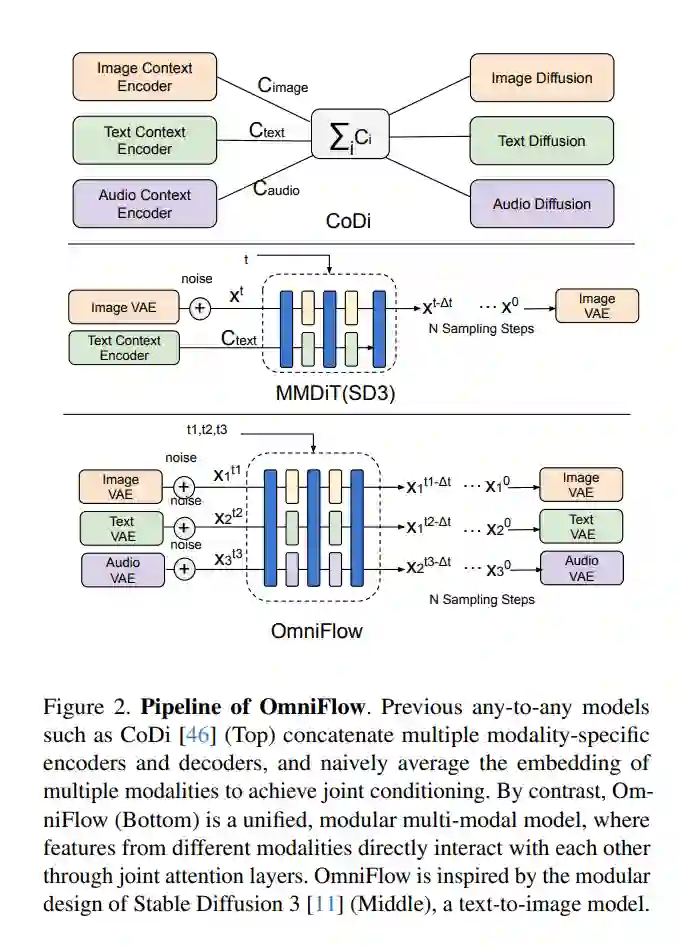
- OmniFlow:基于多模态修正流的任意到任意生成

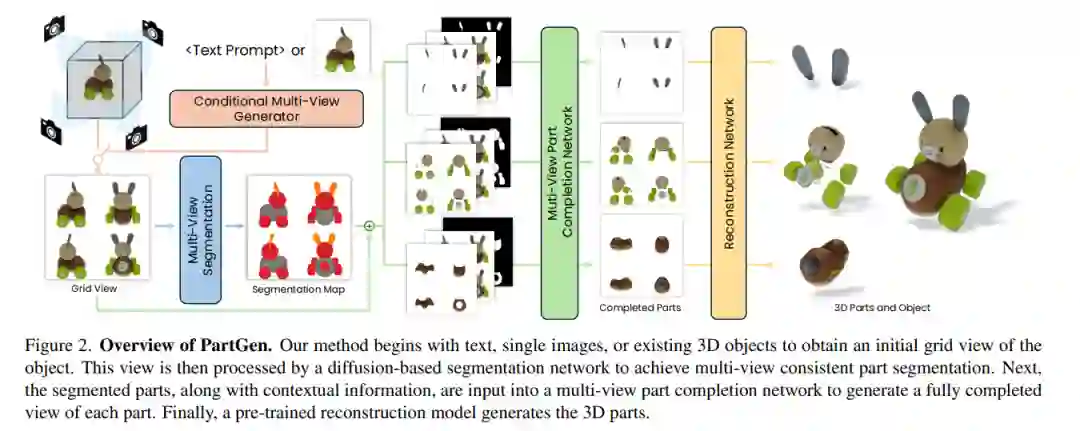
- PartGen:基于多视图扩散模型的零件级 3D 生成与重建

当前的文本或图像到 3D 生成器以及 3D 扫描仪已经能够生成具有高质量形状和纹理的 3D 资产。然而,这些资产通常由单一融合的表示形式(如隐式神经场、高斯混合或网格)组成,缺乏有用的结构。大多数应用和创意工作流程需要资产由多个可独立操作的有意义部分组成。为填补这一空白,我们提出了 PartGen,这是一种新颖的方法,能够从文本、图像或无结构的 3D 对象生成由有意义部分组成的 3D 对象。首先,给定生成或渲染的 3D 对象的多个视图,多视图扩散模型提取一组合理且视图一致的部分分割,将对象划分为多个部分。然后,第二个多视图扩散模型分别处理每个部分,填补遮挡区域,并将这些完整的视图输入到 3D 重建网络中进行重建。这一补全过程考虑了整个对象的上下文,以确保各部分能够紧密结合。生成式补全模型可以弥补因遮挡而缺失的信息;在极端情况下,它甚至可以根据输入的 3D 资产生成完全不可见的部分。我们在生成和真实的 3D 资产上评估了该方法,结果表明其在分割和部分提取任务上大幅优于基线方法。我们还展示了诸如 3D 部分编辑等下游应用。 https://arxiv.org/pdf/2412.18608