EEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)是计算机视觉领域的顶级国际会议,CCF A类会议。CVPR2025将于2025年6月11日至15日在美国田纳西州纳什维尔举办。CVPR 2025 共有13,008 份投稿,录用2878篇,录取率为 22.1%。最新几篇《可控生成》论文速度。![图片]()
- 多焦点条件潜在扩散用于人物图像合成
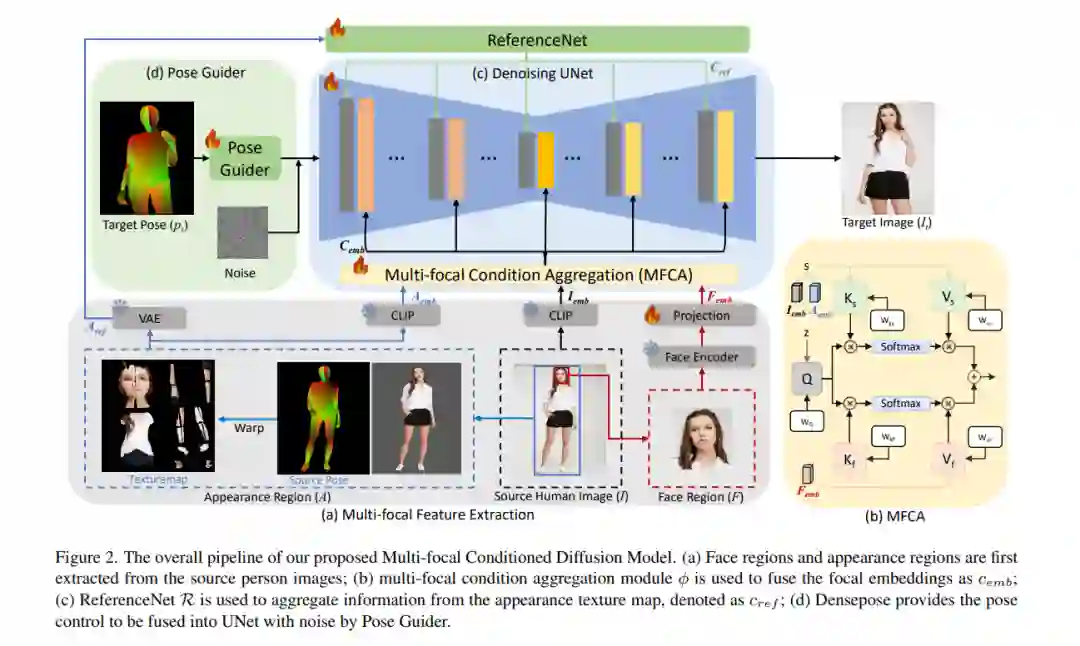
![]() 潜在扩散模型(LDM)在高分辨率图像生成中展现了强大的能力,并已广泛应用于姿态引导人物图像合成(PGPIS),取得了令人瞩目的成果。然而,LDM的压缩过程通常会导致细节的退化,尤其是在面部特征和服装纹理等敏感区域。在本文中,我们提出了一种多焦点条件潜在扩散(MCLD)方法,通过从这些敏感区域提取解耦的、姿态不变的特征来调节模型,从而解决这些局限性。我们的方法利用了一个多焦点条件聚合模块,有效整合了面部身份和纹理特定信息,增强了模型生成外观逼真且身份一致的图像的能力。我们的方法在DeepFashion数据集上展示了稳定的身份和外观生成能力,并由于其生成一致性,支持灵活的人物图像编辑。代码可在https://github.com/jqliu09/mcld 获取。
潜在扩散模型(LDM)在高分辨率图像生成中展现了强大的能力,并已广泛应用于姿态引导人物图像合成(PGPIS),取得了令人瞩目的成果。然而,LDM的压缩过程通常会导致细节的退化,尤其是在面部特征和服装纹理等敏感区域。在本文中,我们提出了一种多焦点条件潜在扩散(MCLD)方法,通过从这些敏感区域提取解耦的、姿态不变的特征来调节模型,从而解决这些局限性。我们的方法利用了一个多焦点条件聚合模块,有效整合了面部身份和纹理特定信息,增强了模型生成外观逼真且身份一致的图像的能力。我们的方法在DeepFashion数据集上展示了稳定的身份和外观生成能力,并由于其生成一致性,支持灵活的人物图像编辑。代码可在https://github.com/jqliu09/mcld 获取。
![]() 2. DriveGEN:通过无训练可控文本到图像扩散生成提升驾驶场景中三维检测的鲁棒性
2. DriveGEN:通过无训练可控文本到图像扩散生成提升驾驶场景中三维检测的鲁棒性
![]()
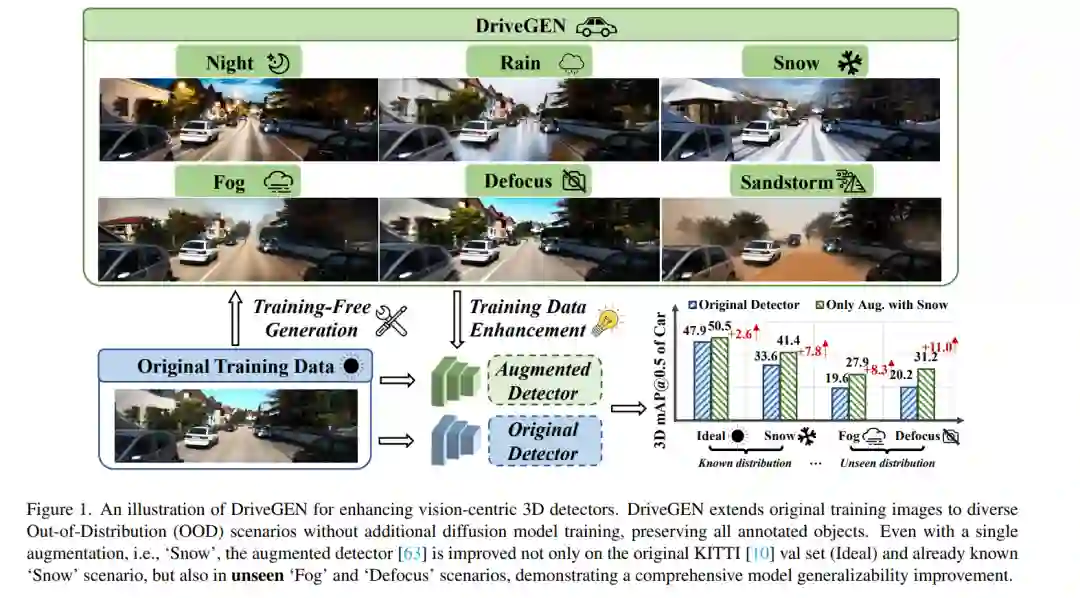
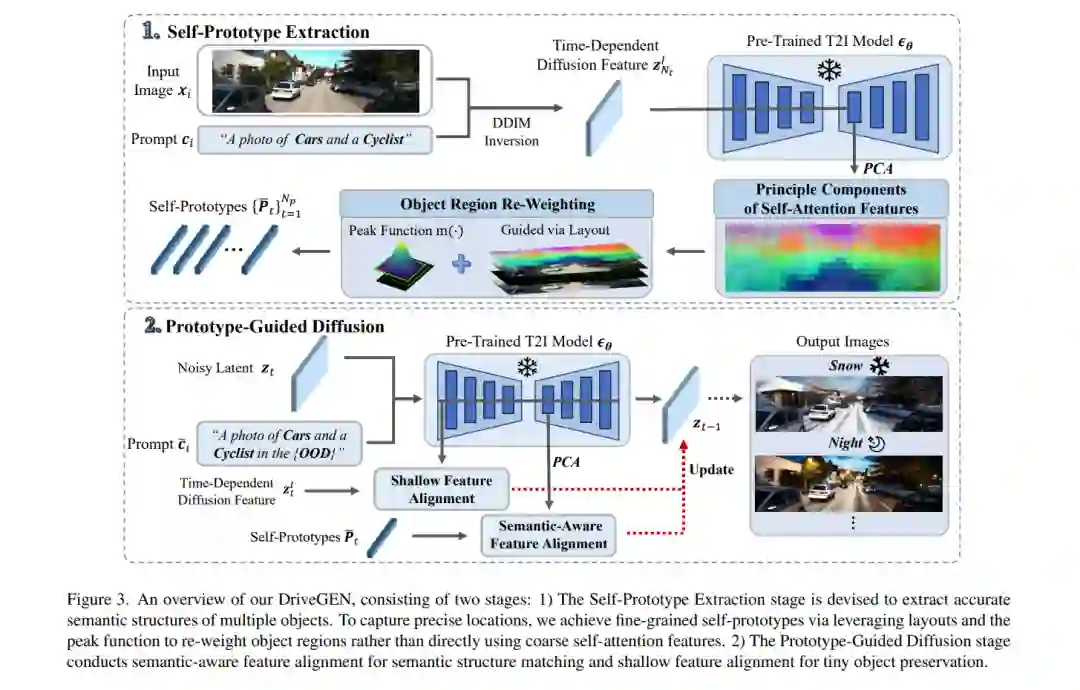
![]() 在自动驾驶中,以视觉为中心的三维检测旨在从图像中识别三维物体。然而,高昂的数据收集成本和多样化的现实场景限制了训练数据的规模。一旦训练数据和测试数据之间发生分布偏移,现有方法往往会面临性能下降的问题,即所谓的“分布外”(OOD)问题。为了解决这一问题,可控的文本到图像(T2I)扩散技术为训练数据增强提供了一种潜在的解决方案,它能够生成具有精确三维物体几何形状的多样化OOD场景。然而,现有的可控T2I方法受限于训练数据的规模,或难以保留所有标注的三维物体。在本文中,我们提出了DriveGEN,一种通过无训练可控文本到图像扩散生成来提升驾驶场景中三维检测器鲁棒性的方法。DriveGEN无需额外的扩散模型训练,能够在多样化的OOD生成中一致地保留具有精确三维几何形状的物体。该方法包含两个阶段:自原型提取:我们通过实验发现,自注意力特征具有语义感知能力,但需要精确的区域选择来提取三维物体。因此,我们通过布局提取精确的物体特征以捕捉三维物体几何形状,称为自原型。原型引导扩散:为了在各种OOD场景中保留物体,我们在去噪过程中执行语义感知特征对齐和浅层特征对齐。大量实验证明了DriveGEN在提升三维检测方面的有效性。代码可在Hongbin98/DriveGEN获取。
在自动驾驶中,以视觉为中心的三维检测旨在从图像中识别三维物体。然而,高昂的数据收集成本和多样化的现实场景限制了训练数据的规模。一旦训练数据和测试数据之间发生分布偏移,现有方法往往会面临性能下降的问题,即所谓的“分布外”(OOD)问题。为了解决这一问题,可控的文本到图像(T2I)扩散技术为训练数据增强提供了一种潜在的解决方案,它能够生成具有精确三维物体几何形状的多样化OOD场景。然而,现有的可控T2I方法受限于训练数据的规模,或难以保留所有标注的三维物体。在本文中,我们提出了DriveGEN,一种通过无训练可控文本到图像扩散生成来提升驾驶场景中三维检测器鲁棒性的方法。DriveGEN无需额外的扩散模型训练,能够在多样化的OOD生成中一致地保留具有精确三维几何形状的物体。该方法包含两个阶段:自原型提取:我们通过实验发现,自注意力特征具有语义感知能力,但需要精确的区域选择来提取三维物体。因此,我们通过布局提取精确的物体特征以捕捉三维物体几何形状,称为自原型。原型引导扩散:为了在各种OOD场景中保留物体,我们在去噪过程中执行语义感知特征对齐和浅层特征对齐。大量实验证明了DriveGEN在提升三维检测方面的有效性。代码可在Hongbin98/DriveGEN获取。
![]() 3. ArtFormer:多样化的三维关节物体的可控生成
3. ArtFormer:多样化的三维关节物体的可控生成
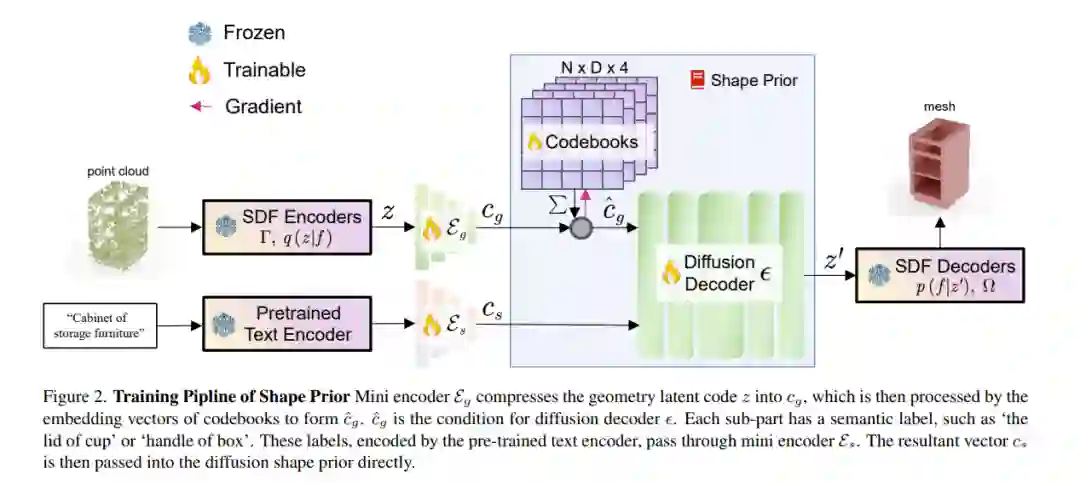
![]() 本文提出了一种新颖的三维关节物体建模和条件生成框架。现有方法通常受限于灵活性-质量之间的权衡,只能使用预定义的结构或从静态数据集中检索形状。为了解决这些挑战,我们将关节物体参数化为一个由令牌组成的树结构,并利用Transformer生成物体的高层几何代码及其运动学关系。随后,每个子部件的几何形状通过符号距离函数(SDF)形状先验进一步解码,从而促进高质量三维形状的合成。我们的方法能够生成具有高质量几何形状和不同部件数量的多样化物体。基于文本描述的条件生成综合实验证明了我们方法的有效性和灵活性。
本文提出了一种新颖的三维关节物体建模和条件生成框架。现有方法通常受限于灵活性-质量之间的权衡,只能使用预定义的结构或从静态数据集中检索形状。为了解决这些挑战,我们将关节物体参数化为一个由令牌组成的树结构,并利用Transformer生成物体的高层几何代码及其运动学关系。随后,每个子部件的几何形状通过符号距离函数(SDF)形状先验进一步解码,从而促进高质量三维形状的合成。我们的方法能够生成具有高质量几何形状和不同部件数量的多样化物体。基于文本描述的条件生成综合实验证明了我们方法的有效性和灵活性。![]() https://arxiv.org/pdf/2412.07237 4. 基于多模态控制的视频引导Foley音效生成
https://arxiv.org/pdf/2412.07237 4. 基于多模态控制的视频引导Foley音效生成
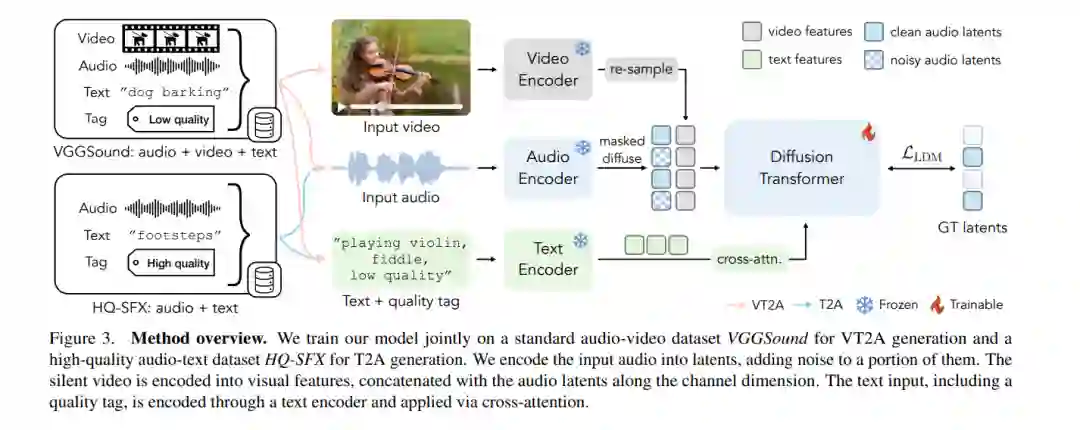
![]() 为视频生成音效通常需要创建与现实音源显著不同的艺术化音效,并在音效设计中提供灵活的控制。为了解决这一问题,我们提出了MultiFoley模型,该模型专为视频引导的音效生成设计,支持通过文本、音频和视频进行多模态条件控制。给定一个无声视频和文本提示,MultiFoley允许用户生成干净的音效(例如,滑板轮子旋转时没有风声)或更具想象力的音效(例如,将狮子的吼声变成猫的喵喵声)。MultiFoley还允许用户从音效库或部分视频中选择参考音频作为条件输入。我们模型的一个关键创新在于其联合训练了互联网视频数据集(音频质量较低)和专业音效录音,从而能够生成高质量、全带宽(48kHz)的音频。通过自动化评估和人类研究,我们证明了MultiFoley能够成功生成与多样化条件输入同步的高质量音效,并优于现有方法。请访问我们的项目页面查看视频结果:https://ificl.github.io/MultiFoley/
为视频生成音效通常需要创建与现实音源显著不同的艺术化音效,并在音效设计中提供灵活的控制。为了解决这一问题,我们提出了MultiFoley模型,该模型专为视频引导的音效生成设计,支持通过文本、音频和视频进行多模态条件控制。给定一个无声视频和文本提示,MultiFoley允许用户生成干净的音效(例如,滑板轮子旋转时没有风声)或更具想象力的音效(例如,将狮子的吼声变成猫的喵喵声)。MultiFoley还允许用户从音效库或部分视频中选择参考音频作为条件输入。我们模型的一个关键创新在于其联合训练了互联网视频数据集(音频质量较低)和专业音效录音,从而能够生成高质量、全带宽(48kHz)的音频。通过自动化评估和人类研究,我们证明了MultiFoley能够成功生成与多样化条件输入同步的高质量音效,并优于现有方法。请访问我们的项目页面查看视频结果:https://ificl.github.io/MultiFoley/
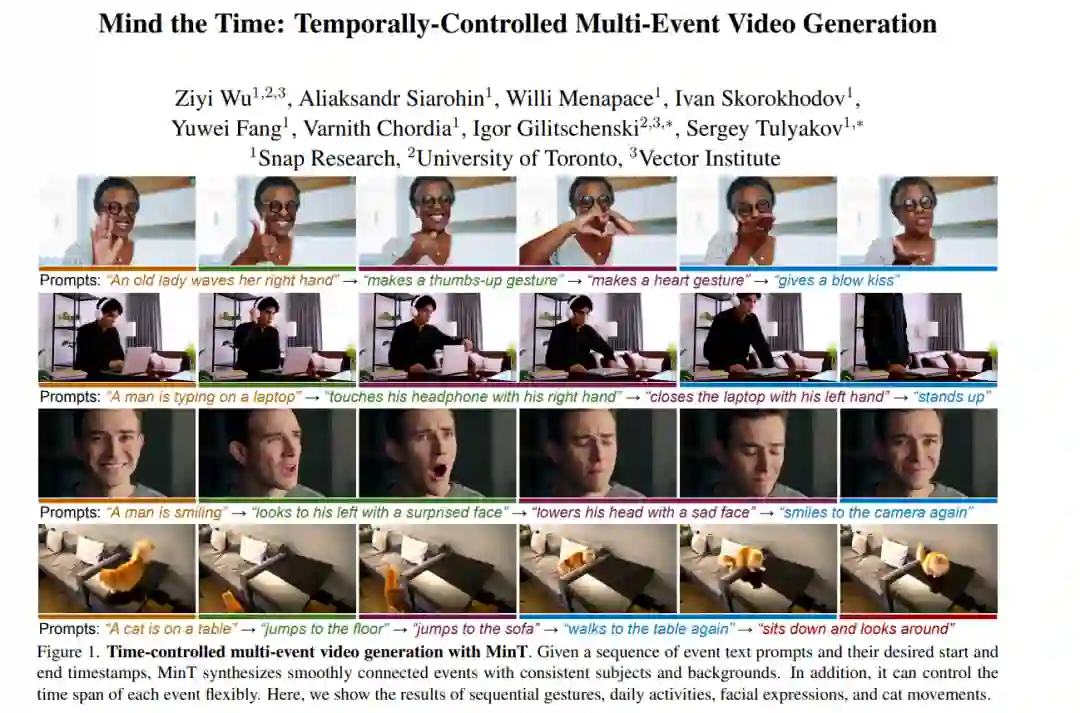
![]() https://arxiv.org/pdf/2411.176985. 注意时间:时间控制的多事件视频生成
https://arxiv.org/pdf/2411.176985. 注意时间:时间控制的多事件视频生成
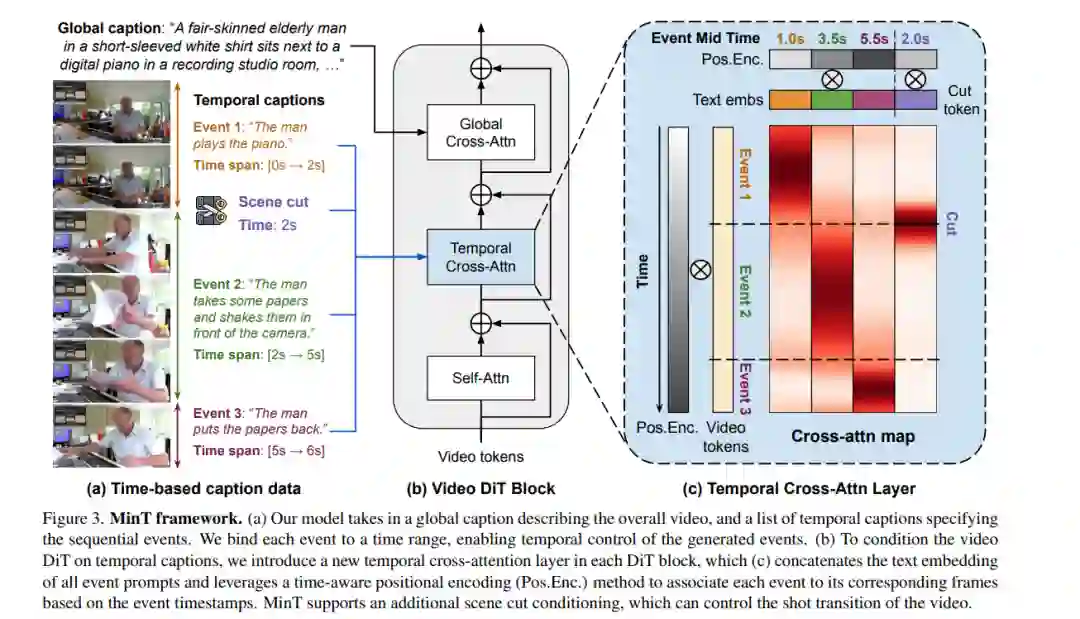
![]() 现实世界中的视频由一系列事件组成。现有的视频生成器依赖于单段文本作为输入,无法生成具有精确时间控制的事件序列。当需要生成由单一提示描述的多个事件时,这些方法往往会忽略某些事件或无法正确排列事件的顺序。为了解决这一局限性,我们提出了MinT,一种具有时间控制的多事件视频生成器。我们的关键见解是将每个事件绑定到生成视频的特定时间段,从而使模型能够一次专注于一个事件。为了实现事件描述与视频令牌之间的时间感知交互,我们设计了一种基于时间的位置编码方法,称为ReRoPE。这种编码有助于引导交叉注意力操作。通过在时间锚定数据上微调预训练的视频扩散Transformer,我们的方法能够生成事件连贯且平滑连接的视频。在文献中,我们的模型首次提供了对生成视频中事件时间安排的控制。大量实验表明,MinT在性能上大幅优于现有的商业和开源模型。更多结果和细节请访问我们的项目页面。
现实世界中的视频由一系列事件组成。现有的视频生成器依赖于单段文本作为输入,无法生成具有精确时间控制的事件序列。当需要生成由单一提示描述的多个事件时,这些方法往往会忽略某些事件或无法正确排列事件的顺序。为了解决这一局限性,我们提出了MinT,一种具有时间控制的多事件视频生成器。我们的关键见解是将每个事件绑定到生成视频的特定时间段,从而使模型能够一次专注于一个事件。为了实现事件描述与视频令牌之间的时间感知交互,我们设计了一种基于时间的位置编码方法,称为ReRoPE。这种编码有助于引导交叉注意力操作。通过在时间锚定数据上微调预训练的视频扩散Transformer,我们的方法能够生成事件连贯且平滑连接的视频。在文献中,我们的模型首次提供了对生成视频中事件时间安排的控制。大量实验表明,MinT在性能上大幅优于现有的商业和开源模型。更多结果和细节请访问我们的项目页面。![]()