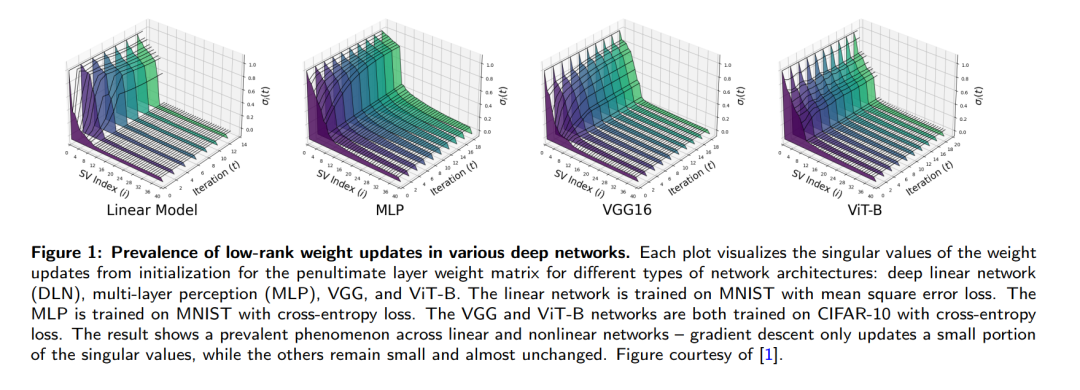
深度学习的兴起彻底改变了信号处理与机器学习领域的数据处理与预测范式,然而现代大规模深度模型的训练与部署所伴随的巨额计算需求——包括高昂的计算成本与能耗——构成了严峻挑战。最新研究发现深度网络中存在一个普遍现象:权重矩阵与学习表征在训练过程中会自发形成低秩结构。这些隐式的低维模式为提升大规模模型训练与微调效率提供了关键洞见。受此启发的实用技术(如低秩适配/LoRA和低秩训练)能在保持模型性能的同时显著降低计算成本。本文系统综述了深度学习低秩结构研究的最新进展,并揭示其数学基础:理论层面,我们提出理解深度网络低秩特性的两个互补视角:优化动态视角:梯度下降全过程产生的低秩结构涌现隐式正则视角:收敛时诱导低秩结构的正则化效应应用层面,研究梯度下降的低秩学习动力学不仅为理解LoRA在大模型微调中的有效性奠定数学基础,更启发了参数高效的低秩训练策略;而隐式低秩正则效应则解释了从Dropout到掩码自监督学习等各类掩码训练方法在深度神经网络中的成功机制。本综述旨在为研究者提供关于大规模深度学习模型训练与适配中低秩结构的系统认知,既阐明低秩方法的理论基础与实践价值,也指明未来研究的突破方向。关键词:深度学习;低秩适配;低秩训练;掩码训练;高效计算;学习动力学
https://www.zhuanzhi.ai/paper/552b9e6fb84caa95370676214fdbbab0

1 引言
深度学习与大规模计算技术的出现,彻底革新了信号处理与机器学习领域的数据处理、解析与预测范式。然而,现代深度学习模型的训练与部署需要消耗巨额计算资源,引发了关于训练成本过高、GPU短缺以及未来能源消耗激增的担忧。与传统信号处理方法相比,我们对深度学习运作机理的理论认知仍显不足。典型例证是:根据信号处理与统计推断的经典理论,参数估计所需的数据样本量应与模型参数量相当或更大,才能保证学习过程的准确性与样本效率。但当前最先进的深度学习模型却普遍存在参数量远超可用样本量的反常规现象。在深度学习数学原理的研究中,过去十年的多项工作发现:训练过程中会自发涌现低维结构——即使没有显式约束,神经网络权重矩阵与层间表征(如特定网络层的输出)往往呈现近似低秩特性。这种隐式的低维结构部分源于深度网络训练方法的隐式偏置,这为解释"为何深度学习能用少于模型参数量的样本取得良好效果"提供了线索。受此启发,研究者开始系统探索利用低秩结构来高效训练与微调大规模深度学习模型。例如:低秩适配(LoRA)[2]:通过向权重矩阵添加低秩分解的增量更新,以极低计算内存成本实现模型微调。该方法因在大语言模型(LLM)、视觉-语言模型和图像生成模型中的卓越表现而备受关注。低秩训练:基于LoRA的成功实践,研究者进一步将权重矩阵显式分解为低秩因子进行训练后压缩,或直接从头训练低秩模型。例如DeepSeek-V3模型[3]通过在多头注意力机制中采用查询矩阵的低秩分解,在显著压缩模型规模的同时获得了优异的语言生成效果。本文旨在梳理该领域的最新进展,并阐明其数学基础。我们将从两个互补视角解析深度学习的低秩结构:优化动态中的结构(第3节):证明特定优化算法在迭代过程中始终维持低秩特性,可利用该特性全程降低计算成本(图1示意)目标函数的隐式正则(第4节):揭示即使目标函数未显式施加正则化,最终解仍具有低秩约束。通过建立目标函数与正则化目标的等价性,表征算法收敛时的结构特性(图2示意)全文组织:第2节回顾简化模型下低秩学习动力学的数学基础;第3.1节分析深度线性网络训练动态中的低秩结构;第3.2节据此解读LoRA方法及其变体;第3.3节综述近期低秩训练方法;第4节讨论训练算法收敛时的低秩结构;第5节总结开放性问题。