
多变量时间序列的异常检测是许多领域的一个重要问题。系统的日益复杂和数据量的爆炸性增长使其自动化变得至关重要。基于深度学习的方法在检测方面显示出良好的效果,但由于其长时间的训练和有限的鲁棒性,并不能满足工业需求。为了满足工业需求,本论文提出了一种新的无监督方法,用于多变量时间序列的异常检测,称为USAD,基于自动编码器架构和对抗性训练。该方法符合工业界对鲁棒性和训练速度的要求,同时在检测方面达到了最先进的性能。然而,深度神经网络方法在从数据中提取特征的能力方面受到限制,因为它们只依赖局部信息。因此,为了提高这些方法的性能,本论文提出了一种引入非局部信息的特征工程策略。这一策略在不增加训练时间的情况下提高了基于神经网络的方法的性能。鉴于近年来深度学习方法在多变量时间序列异常检测中的良好表现,研究人员在他们的基准中忽略了所有其他方法,导致所提出的方法的复杂性在目前的出版物中爆炸性增长。这种缺乏与文献中更常规的方法的比较,不允许断言基准中报告的进展不是虚幻的,这种不断增加的复杂性是必要的。为了解决这个问题,本论文提出对多变量时间序列中的16种异常检测方法进行比较,这些方法分为三类。传统方法、机器学习方法和基于深度神经网络的方法。本研究表明,没有证据表明深度神经网络是解决这一问题的必要条件。
关键词:异常检测,时间序列,多变量,深度学习,非监督性

第1章 简介
1.1 背景和动机
由于数据的大量产生,时间序列及其分析正变得越来越重要。时间序列被用于大量的领域,如工业控制系统[2]、金融[3]和医疗保健[4]。
时间序列分析包括从按时间顺序排列的点中提取信息,即时间序列,它可以有多种用途。最常见的是观察一个变量的历史,以便进行预测。这涉及到根据以前观察到的变量值来预测其未来值。另一个常见的目的是发现时间序列之间的关联性。这允许了解系统中不同变量之间的相互作用。许多其他目标解释了时间序列分析的普及,如寻找趋势、周期、季节性变化或检测异常行为。
检测意外行为或不符合预期行为的模式是一门活跃的研究学科,称为时间序列中的异常检测[5]。异常检测是一个重要的领域。它包括检测罕见的事件,或者更普遍的,与大多数数据不同的反常的观察。这些罕见事件可以是各种类型的,它们存在于多个不同的领域(欺诈性金融交易、医疗问题或网络入侵)。检测这些罕见事件是许多领域的一个主要问题。例如,到2020年,检测银行交易欺诈可以为全球节省320亿美元[6]。因此,对于行业来说,能够检测其系统中的异常情况是至关重要的。
本论文关注异常检测这一关键任务。具体来说,它专注于时间序列异常检测方法的一个子集,即无监督检测。与监督检测不同,无监督检测方法不需要与数据样本相关的标签。这样做的目的是为了检测与以前观察到的数据不同的行为[7]。最后,本论文关注多变量时间序列,因为它是最通用的背景,因为单变量时间序列只是2.1.1节中介绍的m=1的多变量背景的一个特例。
在过去的十年中,人们对深度神经网络(DNNs)的热情越来越高[8],这要归功于它们在潜在的大体积和大维度的复杂数据中推断高阶相关的能力[9, 10]。时间序列中的异常检测也没有逃过这一趋势。基于DNN的方法旨在学习多变量时间序列的深度潜在表征,以推断出一个变量模型,然后用于对未见数据的异常分级。越来越多地使用DNN架构的理由在于,需要学习多变量数据的时间演化中潜在的复杂数据模式。因此,出现了许多方法,主要是基于递归神经网络来捕捉时间信息[11, 12, 13]。然而,这些方法以牺牲其训练速度为代价获得良好的结果。事实上,这些方法都没有在其性能标准中考虑到训练时间。这就是为什么有必要开发在异常检测方面具有与技术水平相当的性能的方法,同时偏重于允许快速和节能的训练的架构。
与任何机器学习方法一样,深度学习方法的性能与提取的特征的质量相关[14]。增强时间序列数据的特征工程通常是通过将外部但相关的信息作为一个额外的变量带到时间序列中来完成。然而,这需要关于测量过程的领域知识。机器学习方法的另一个策略是在时间序列上创建局部特征,如移动平均线或局部最大和最小值。这两种策略,由于是手工操作,效率不高,耗时长,而且需要很高的领域知识专长[15]。从理论上讲,鉴于DNN已被证明具有自动学习局部特征的能力,从而解决了更多传统统计和机器学习方法的局限性,DNN已成为一种有希望的替代方案。尽管它们具有学习这种局部特征的能力,但事实证明,特征工程可以加速和提高DNN的学习性能[16],DNN学习的特征的一个内在限制是它们只依赖局部信息。然而,目前文献中还没有成熟的方法来解决时间序列的这个问题。
由于DNN在多个领域表现出良好的性能[9, 10, 17, 18],近年来,基于DNN的多变量时间序列异常检测方法蓬勃发展(表1.1)。然而,这些工作已经远离了与更传统的方法,即机器学习[19]和传统/统计方法(如[1, 2, 13])的比较,同时提出了方法上的进步和基于DNN方法的改进性能。这种趋势鼓励社区开发更复杂的模型,以提高基于DNN的方法的性能,但没有任何理论或经验证据表明这些模型优于文献中更成熟的方法体系。
基于DNN的模型训练起来很复杂,涉及大量的参数估计,需要大量的训练样本和计算资源。此外,随着更大的模型不断被开发,它们的复杂性也在不断增加。相反,传统的模型更简单、更轻便、更容易解释,而且往往更能适应现实世界应用的限制。因此,关键是要确定基于DNN的方法所带来的复杂性是否是为获得性能而付出的必要代价,或者近年来报告的进展是虚幻的[20],应该优先使用传统方法。由于缺乏涵盖所有方法系列的一般性比较,无法回答这个问题,阻碍了基于DNN的方法在实际应用中的转化和使用。目前,文献中还没有关于这种特性的完整基准。
表1.1: 2018年至2021年同行评议的基于深度学习的多变量时间序列异常检测方法
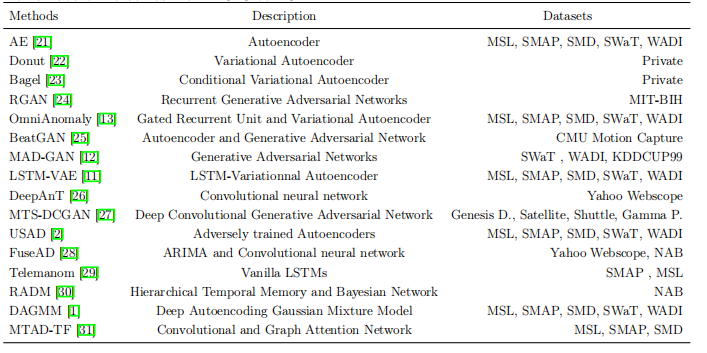
1.2 贡献
本论文是CIFRE(Convention Industrielle de Formation par la Recherche)的论文,是Orange和EURECOM的合作。Orange是一家法国电信公司。它在全球拥有近2.7亿客户。因此,本论文的贡献和开发的方法是为了融入Orange的工业环境中。本论文的所有贡献如下。
-
一种快速而稳定的方法,称为多变量时间序列的无监督异常检测(USAD),基于对抗性训练的自动编码器。其自动编码器结构使其能够进行无监督学习。使用对抗性训练和它的结构使它能够在提供快速训练的同时隔离异常现象。
-
在使用DNN进行异常检测的情况下,一种新的特征工程策略来增强时间序列数据。其目标是双重的。首先,将单变量时间序列转化为多变量时间序列以提高DNN的性能。第二,使用一种特征工程策略,将非本地信息引入时间序列,这是DNN无法学习的。这是通过使用一个叫做Matrix-Profile的数据结构作为一个通用的非琐碎特征来实现的。矩阵文件允许提取与时间序列的子序列之间的相似性相对应的非本地特征。与每个单独的方法相比,性能显示该方法在不增加计算时间的情况下实现了更好的性能。
-
对包括USAD在内的16种传统的、基于机器学习的和基于深度神经网络的方法在五个开放的真实世界数据集上的异常检测性能的研究。对这16种方法中每一种的性能分析和比较表明,没有哪一种方法的性能优于其他方法。当数据集包含上下文异常或数据集较大时,深层神经网络似乎表现得更好,而传统技术在数据集较小时表现得更好。因此,不可能说深度神经网络优于以前的方法,社区应该重新将这三类方法纳入多变量时间序列基准的异常检测中。
1.3 论文结构
本节对以下各章的内容进行了总结:
-
第二章主要分为两部分。第一部分介绍了时间序列和它们的特征。第二部分专门讨论时间序列中的异常检测,并介绍了分为三个主要类别的方法的技术现状。传统的、机器学习的和深度学习的方法。
-
第三章介绍了一种由不良训练的自动编码器架构组成的多变量时间序列的无监督异常检测方法,并展示了该方法在五个真实世界的开放数据集以及Orange的专有数据上的性能。
-
第四章介绍了一种特征工程策略,通过引入非局部信息将单变量时间序列转化为多变量时间序列,并表明这种策略解决了深度神经网络的局限性,并证明了这种组合在不增加计算时间的情况下优于每种方法。
-
第五章质疑是否需要主要基于深度神经网络的更复杂的方法来进行多变量时间序列的异常检测,并提出对属于第二章中提出的三类的16种方法进行研究。性能分析表明,这三类方法中没有一种方法优于其他方法。并讨论了基于深度神经网络的方法在多变量时间序列异常检测基准中可能出现的性能错觉。
-
最后,第六章总结了这项工作的主要贡献,并提出了对这项研究可能继续进行的一些想法。
1.4 著作
本论文是在已发表文章的基础上进行的研究。本论文中出现的部分内容曾在以下论文中发表过:
-
Julien Audibert, Pietro Michiardi, Frédéric Guyard, Sébastien Marti, and Maria A. Zuluaga. USAD:多变量时间序列上的非监督性异常检测。在第26届ACM SIGKDD知识发现与数据挖掘国际会议(KDD '20)论文集中。
-
Julien Audibert, Frédéric Guyard, Sébastien Marti, and Maria A. Zuluaga. 从单变量到多变量的时间序列异常检测与非本地信息。在ECML PKDD 2021的第六届高级分析和时态数据学习研讨会上。
-
Julien Audibert, Pietro Michiardi, Frédéric Guyard, Sébastien Marti, and Maria A. Zuluaga. 论深度神经网络对多变量时间序列异常检测的好处,正在模式识别2021年评审中。
1.5 参与挑战
本论文开发的部分方法参加了KDDCUP2021的 "多数据集时间序列异常检测 "挑战赛。参与的方法在565名参赛者中获得了第16名。


