

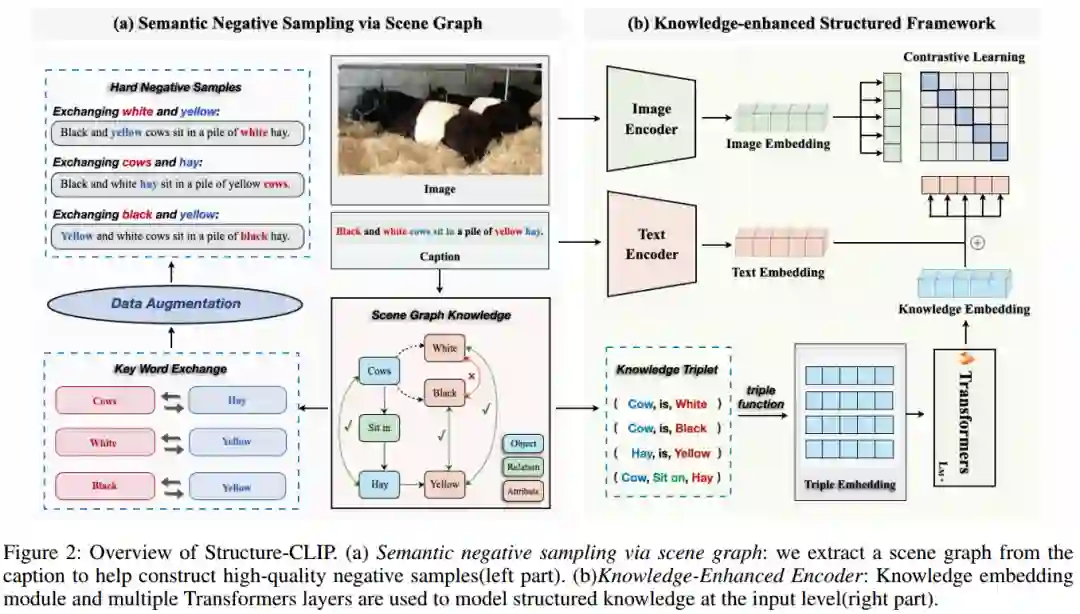
大规模视觉语言预训练在多模态理解和生成任务中取得了显著的效果。然而,现有的方法在需要结构化表示(即对象、属性和关系的表示)的图像-文本匹配任务上通常表现不佳。如图1 (a)所示,模型无法区分“宇航员骑马”和“马骑宇航员”。这是因为它们在学习多模态场景中的表示时未能充分利用结构化知识。在本文中,作者提出了一个端到端框架Structure-CLIP,它集成了场景图知识(Scene Graph Knowledge, SGK)来增强多模态结构化表示。首先,作者使用场景图来指导语义负样例的构建,并提出了一种知识增强编码器(KEE),利用SGK作为输入进一步增强结构化表示。为了验证所提出框架的有效性,作者使用上述方法预训练模型,并在下游任务上进行实验。实验结果表明,Structure-CLIP在VG-Attribution和VG-Relation数据集上达到了最先进的SOTA性能,分别比多模态SOTA模型高出12.5%和4.1%。同时,MSCOCO结果表明,Structure-CLIP在保持一般表征能力的同时,显著增强了结构化表征。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日
相关主题
相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日