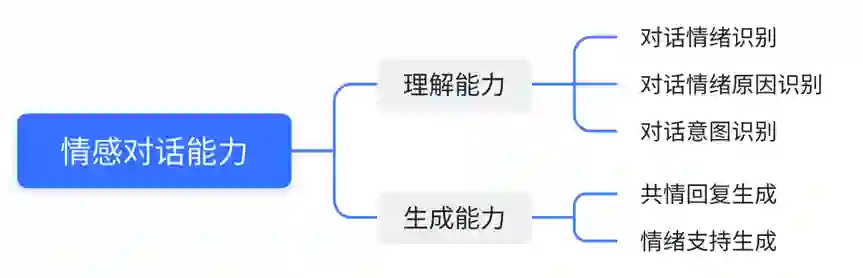
揭秘ChatGPT情感对话能力
原创作者:赵伟翔,赵妍妍,陆鑫,王世龙,童彦澎,秦兵
转 载须标注出处:哈工大SCIR
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|

|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|

人工评价结果
|
|
|
|
||
|
ChatGPT |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|

|
|
|
|
||
|
ChatGPT |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
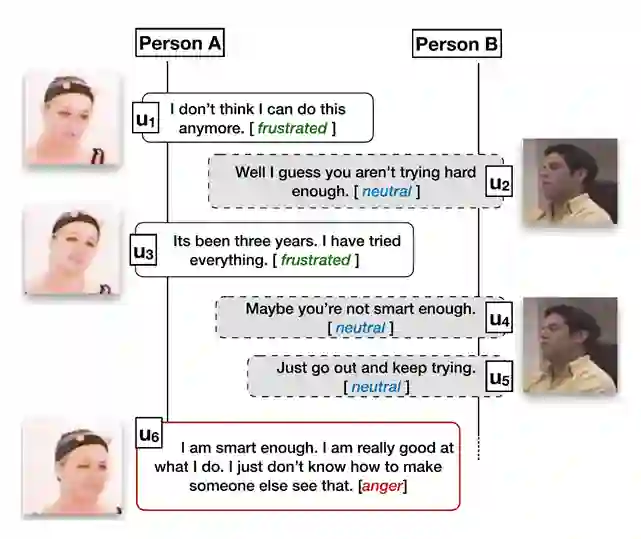
--- A:Anything else , sir ? &question B:That's all for now . How much do I owe you ? &question A:That'll be fifty-five dollars and twenty cents .&inform B:Can't you make it a little cheaper ? &directive A:Oh , no , sir . We already gave you a discount on each item .&commissive B:OK . I understand . Thank you .&inform --- Note: Annotations should be output in the format shown in the example without changing the content of the original text. Please annotate the following dialogue for me: --- <insert-dialogue-here> |
|
|
|
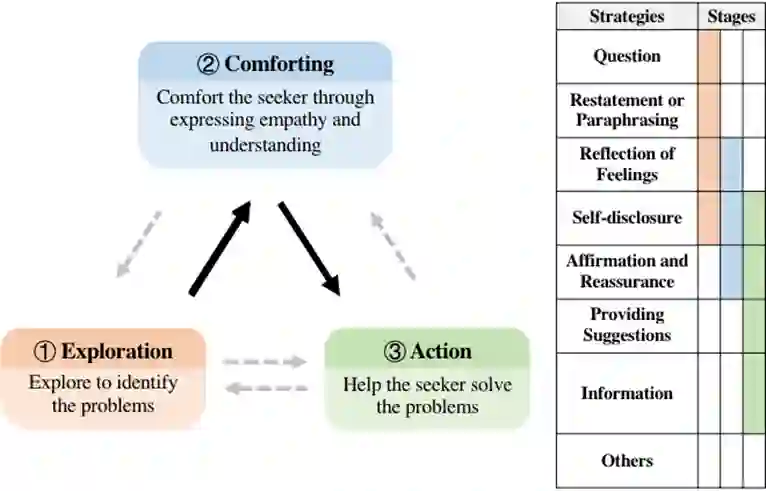
1.Question 2.Restatement or Paraphrasing 3.Reflection of feelings 4.Self-disclosure 5.Affirmation and Reassurance 6.Providing Suggestions 7.Information 8.Others I will provide an example of a conversation, which is as follows: [Conversation Example 1] Now, generate one concise (no more than 30 words), relevant and emotionally supportive response for the following conversation : [Conversation Context] |
本期责任编辑:赵妍妍
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复或发消息“ChatGPT” 就可以获取《ChatGPT专知资料大合集》专知下载链接



登录查看更多
相关内容
Arxiv
85+阅读 · 2023年3月21日


相关VIP内容
相关资讯