

摘要——从视觉观测中重建四维空间智能长期以来一直是计算机视觉领域中的核心难题之一,并具有广泛的现实应用场景。这些应用涵盖从电影等娱乐领域(侧重于基础视觉要素的重建)到具身智能(强调交互建模与物理现实性)。得益于三维表示和深度学习架构的迅猛发展,该研究方向迅速演进,已远超以往综述的覆盖范围。此外,现有综述往往缺乏对四维场景重建中层次结构的系统分析。为填补这一空白,本文提出一种新的视角,将现有方法按照五个逐级递进的四维空间智能层级进行组织: (1) 第一层级:低层三维属性的重建(如深度、姿态和点云图); (2) 第二层级:三维场景组成要素的重建(如物体、人类、结构体); (3) 第三层级:四维动态场景的重建; (4) 第四层级:场景组件之间交互的建模; (5) 第五层级:物理规律与约束的融合建模。 本文最后讨论了各层级所面临的关键挑战,并指出了迈向更高层次四维空间智能的潜在研究方向。为了追踪该领域的最新进展,我们维护了一个实时更新的项目页面: https://github.com/yukangcao/Awesome-4D-Spatial-Intelligence。 关键词——四维空间智能、低层线索、场景重建、动态建模、交互建模、物理建模、视频
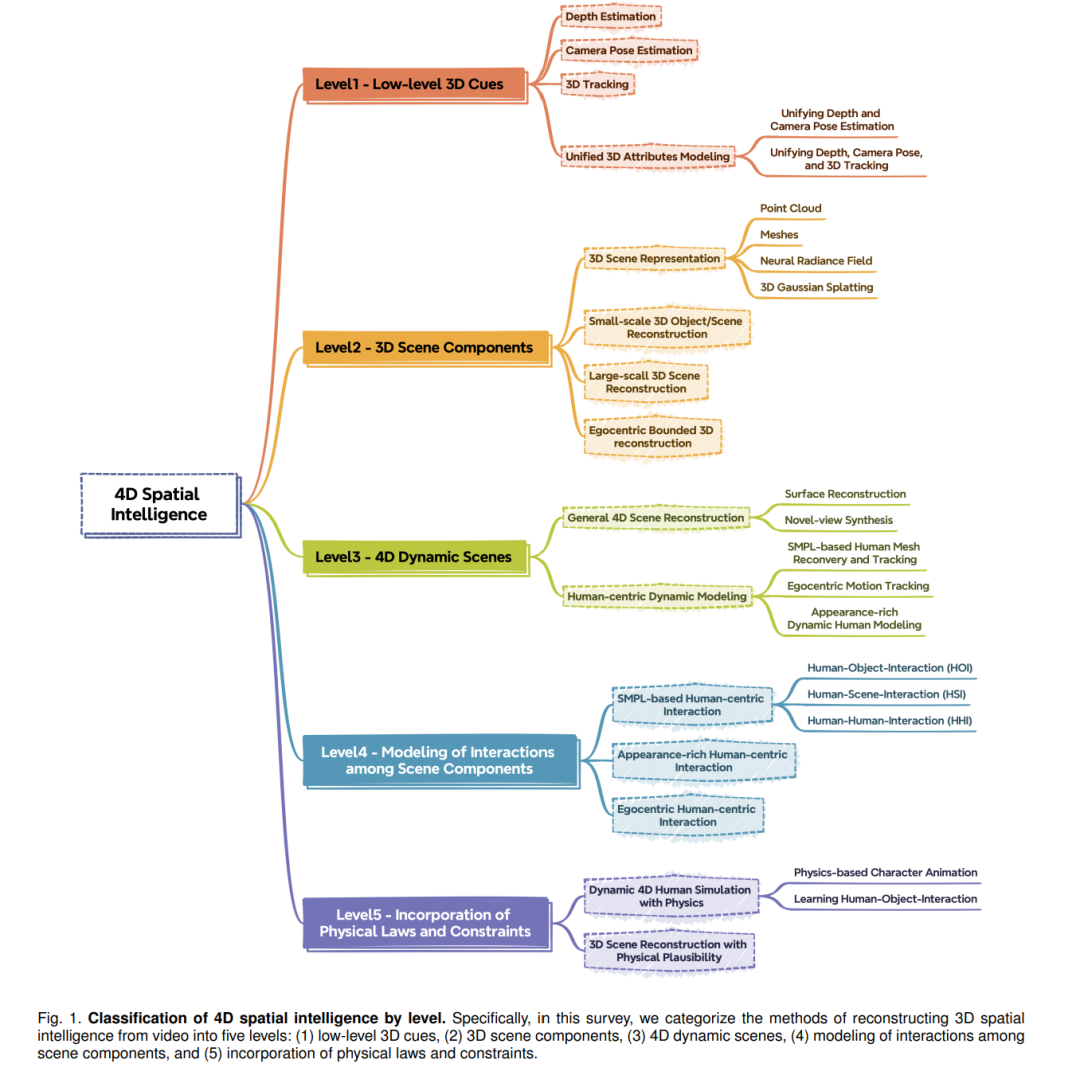
1 引言
利用机器学习或深度学习技术自动重建四维空间智能,长期以来一直是计算机视觉领域中的关键难题。通过同时捕捉静态构型与随时间变化的动态过程,四维空间智能能够提供对空间环境的全面表示与理解,将三维几何结构与其时间演化整合在一起。该研究方向因其广泛的应用场景而受到高度关注,包括视频游戏 [1]、电影 [2] 和沉浸式体验(如 AR/VR)[3], [4],其中高保真度的四维场景是实现真实用户体验的基础。 除了这些侧重于四维空间智能基本组成部分的应用场景——如深度、相机姿态、点云图、三维跟踪等低层线索,以及场景组成要素和动态之外,空间智能还在推动具身智能(Embodied AI)[5], [6], [7] 和世界模型(World Models)[8] 的发展中发挥着核心作用。这些后者的任务更加注重场景中各组成部分之间的交互以及重建环境的物理合理性。 近年来,四维空间智能的重建技术取得了飞速进展。已有若干综述工作 [9], [10] 从不同角度提供了有价值的视角,并总结了该领域中持续存在的挑战。例如,[11]–[13] 综述了通过深度立体匹配获取低层场景信息的最新进展;[14]–[16] 系统梳理了三维场景重建方面的研究,涵盖多种输入模态和多样的三维表示方式;[9], [10] 则从核心架构出发对动态四维场景重建方法进行了分类。 然而,随着新型三维表示方法的提出 [17]–[19]、高质量视频生成技术的发展 [20]–[22]、以及更高效重建模型的出现,该领域已取得显著进展。尽管如此,现有综述尚未系统分析动态四维场景的不同组成层级,也未深入探讨各层级的发展现状与关键挑战,导致人们对四维空间智能的理解仍存在碎片化倾向,容易忽略其中的关键组成部分。因此,亟需一份全面、系统、与时俱进的综述来将四维空间智能划分为不同层级,梳理最新进展,并描绘该研究领域不断演化的全貌。 基于这一紧迫需求,本文将现有的四维空间智能重建方法划分为以下五个层级,并分别对其最新进展进行系统梳理: * 第一层级:低层三维线索的重建。
该层级聚焦于深度、相机姿态、点云图和三维跟踪等基础三维线索的重建,这些要素构成了三维场景的基本结构。传统上,这一任务常被划分为多个子领域,如关键点检测 [23]–[25] 与匹配 [26]–[29]、鲁棒估计 [28], [30]、SfM(结构自运动)[31]–[34]、BA(Bundle Adjustment)[35]–[38]、以及稠密多视图立体重建(MVS)[39]–[43]。近期方法如 DUSt3R [44] 及其系列扩展 [45]–[48] 致力于联合求解上述子任务,实现更协同的一体化推理。而 VGGT [54] 则在 Transformer 架构 [49]–[53] 的基础上,提出了一个端到端系统,能在数秒内高效估计这些低层三维线索。 * 第二层级:三维场景组成要素的重建。
在第一层级的基础上,第二层级进一步重建场景中的独立要素,如人类、物体和建筑等。虽然某些方法涉及要素间的组合与空间布局,但通常不对它们之间的交互进行建模或约束。近期方法结合了 NeRF [55]、3D Gaussians [56] 和 Mesh 表示(如 DMTET [18] 和 FlexiCube [57])等创新型三维表示方式,提升了重建细节的真实性、渲染效率以及整体结构一致性,为照片级真实感场景重建和沉浸式虚拟体验奠定基础。 * 第三层级:四维动态场景的重建。
本层级引入场景动态,是实现“子弹时间”式四维空间体验和沉浸式视觉内容的关键步骤。现有方法主要分为两类:一类方法 [58]–[62] 先重建一个静态的标准辐射场,再通过学习得到的时序变形建模动态过程;另一类方法 [63]–[69] 则将时间作为额外参数直接编码进三维表示,实现连续动态建模。 * 第四层级:场景组件之间交互的建模。
该层级标志着空间智能研究进入更成熟阶段,着眼于不同场景组成部分之间的交互建模。考虑到人类通常是交互的核心主体,早期工作 [70]–[74] 主要聚焦于捕捉人类与可操控物体的动作。随着三维表示的进步,近期方法 [75]–[80] 可更精确地重建人类与物体外观,而人-场景交互建模 [81]–[85] 也逐渐成为研究热点,为构建完整世界模型提供基础支撑。 * 第五层级:物理规律与约束的融合建模。
尽管第四层级能够建模场景组件之间的交互,但通常忽略了如重力、摩擦力、压力等底层物理规律。因此,在如具身智能 [5]–[7] 等任务中,这类方法常难以支持机器人在现实世界中模仿视频中的动作与交互。第五层级的系统旨在通过引入物理可行性约束来弥补上述不足。近期研究 [86]–[88] 借助如 IsaacGym [89] 等平台及强化学习方法 [90]–[92],展示了从视频中直接学习并复现类人技能的能力,标志着向物理一致性空间智能迈出重要一步。此外,对一般三维物体(如变形、碰撞与动力学)和物理场景的建模 [93]–[95] 也成为活跃研究方向,进一步拓展了第五层级的适用范围。
综述范围: 本文主要聚焦于从视频输入中进行四维场景重建的方法,具体围绕上述五个层级梳理关键技术进展与代表性工作。所选论文大多来自计算机视觉与图形学的顶级会议和期刊,并补充了部分 2025 年发布的 arXiv 预印本。我们的选择标准强调与本综述主题的相关性,旨在提供该领域近期快速进展的全面概览。 本综述不涵盖纯三维生成方法 [96]–[98] 及基于生成式视频扩散模型 [20]–[22] 的四维生成方法 [99]–[104],因为它们通常只生成单一类型输入,与四维重建关系较弱。此外,我们也未深入探讨各类三维表示方法,相关读者可参考已有的综述文献 [10], [15], [105]–[110]。 组织结构: 图 1 展示了四维空间智能各层级的整体概览。接下来的章节中,我们按照从视频输入重建五个关键层级的流程,构建一个系统的研究分类体系:第 2 节介绍低层三维线索,第 3 节讨论三维场景要素,第 4 节聚焦动态场景建模,第 5 节涉及场景交互,第 6 节探讨物理规律建模。最后在第 7 节中,我们将对当前方法进行批判性反思,指出各层级仍面临的开放挑战,并展望超越现有五层级的四维空间智能未来发展方向。