

蛋白质溶解度的预测对于天然蛋白质的基础研究至关重要,但对于工程或设计的蛋白质的生产和研究也越来越重要,因为工程性能的实验确认取决于生产的能力。因此,对蛋白质溶解度的准确预测是蛋白质工程师广泛寻求的。在这里,我们提出了一种新的方法,使用极端梯度提升(XGBoost)算法,通过各种数据源,包括预测的溶剂/可及性、二级结构等,来预测蛋白质的溶解度。我们的模型使用一个标准的保留测试集实现了高水平的性能,总体准确率为72%,是基于序列的机器学习模型中最高的。关键的是,我们的系统还产生了对预测很重要的特征信息,利用可解释的人工智能来提供局部和全局的解释器。利用这些信息,我们发现某些单肽、二肽和三肽与溶解度密切相关,蛋白质的无序性、相对溶剂可及性和某些二级结构的频率等指标也是如此,这些指标都是来自其他预测模型的。重要的是,在我们的模型的图形用户界面中,我们利用局部解释来帮助告知预测背后的推理,并建议修改。我们的模型的准确性和可解释性应该允许快速预测蛋白质的溶解度,特别是对于没有可靠结构信息的蛋白质和蛋白质家族。这将极大地提高我们通过机器学习指导的方法和其他蛋白质工程策略来实验生产和研究蛋白质的能力。
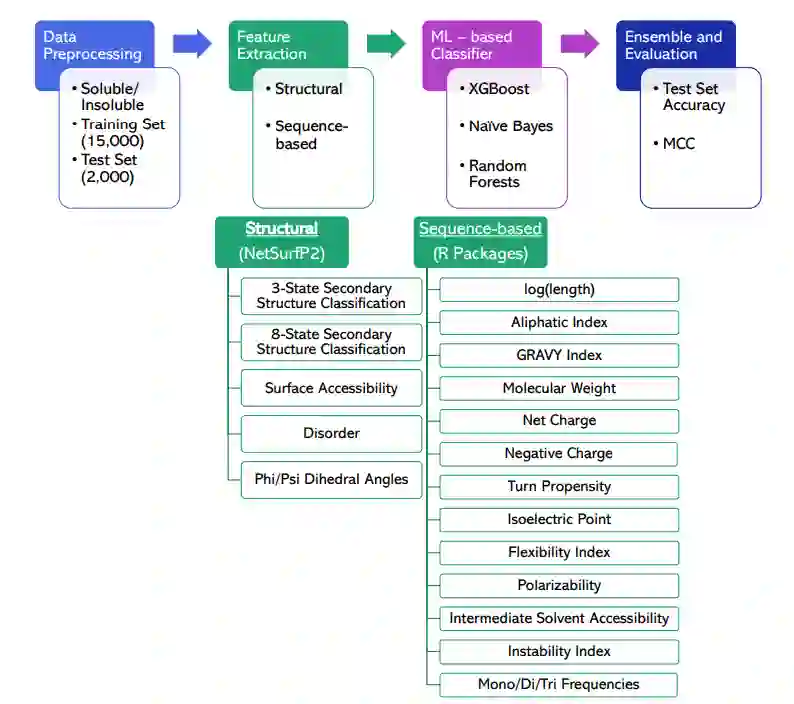
图2. 数据集和模型开发流程图。来自Rawi等人的序列数据被缩减为15000个训练集,并在测试集中保留了2000个序列。获得了基于结构和序列的特征,包括NetSurfP-2.0和各种R软件包的输出。XGBoost、RF和Naïve Bayes模型在汇编的数据集上进行了训练,在整个训练过程中通过交叉验证确定了准确性,最后在保留的(n=2000)Chang等人的测试集上进行了评估。

成为VIP会员查看完整内容
相关内容

Arxiv
0+阅读 · 2022年11月30日

相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年11月30日