

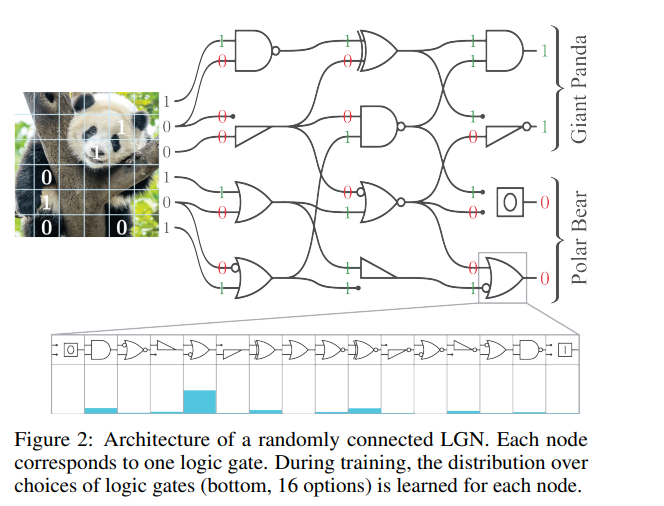
随着机器学习模型推理成本的增加,对快速且高效推理的模型需求日益增长。最近,有一种方法通过可微松弛直接学习逻辑门网络。逻辑门网络的推理速度比传统神经网络方法更快,因为它们的推理仅需使用诸如NAND、OR和XOR等逻辑门操作,而这些操作是当前硬件的基本构件,能够高效执行。我们基于这一想法,进行了扩展,加入了深度逻辑门树卷积、逻辑OR池化和残差初始化。这使得逻辑门网络的规模扩展提高了一个数量级以上,并利用了卷积的范式。在CIFAR-10数据集上,我们仅使用6100万个逻辑门达到了86.29%的准确率,性能超过了最新最优(SOTA)方法,同时模型大小缩小了29倍。
成为VIP会员查看完整内容
相关内容
Arxiv
1+阅读 · 2024年12月23日
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日
相关主题

相关VIP内容
相关资讯
相关论文
Arxiv
1+阅读 · 2024年12月23日
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日