
© 作者|汤昕宇 机构|中国人民大学研究方向|自然语言处理、大语言模型 随着大语言模型的发展,其在执行许多自然语言处理任务上取得了巨大的成功。但是,大语言模型对于提示是非常敏感的,提示中微小的变化都会导致大语言模型在执行任务时产生巨大的性能波动。因此,许多工作对大语言模型的提示进行了研究。本文主要从增强的提示方法,提示的自动优化和关于提示的分析三个方面,调研了大语言模型提示的最新进展。
增强的提示方法
尽管基本的CoT提示策略在复杂推理任务中展示出了强大的能力,但它仍然面临着一些问题,比如推理过程存在错误和不稳定等。因此,一系列的研究通过增强的提示方法激发大语言模型的能力,从而完成更通用的任务。 Explanation Selection Using Unlabeled Data for Chain-of-Thought Prompting
**作者:**Xi Ye, Greg Durrett https://arxiv.org/abs/2302.04813
这篇论文讨论了如何优化大语言模型的解释式提示,以提高其在文本推理任务上的表现。 作者提出了一种新颖的两阶段框架,以黑盒方式优化这些解释式提示。首先,为每个提示中的样例生成多种候选解释,并使用两个指标:对数似然和新例子上的准确性来评估这些解释。然后,通过评估这些组合对来寻找最有效的解释组合。文章证明了这种方法在各种文本推理任务上,包括问答、数学推理和自然语言推理中,能够提高提示的有效性。 此外,这篇工作还强调了他们评估的指标的有效性,有助于识别和优先考虑效果最好的解释组合,从而优化所需的计算资源。
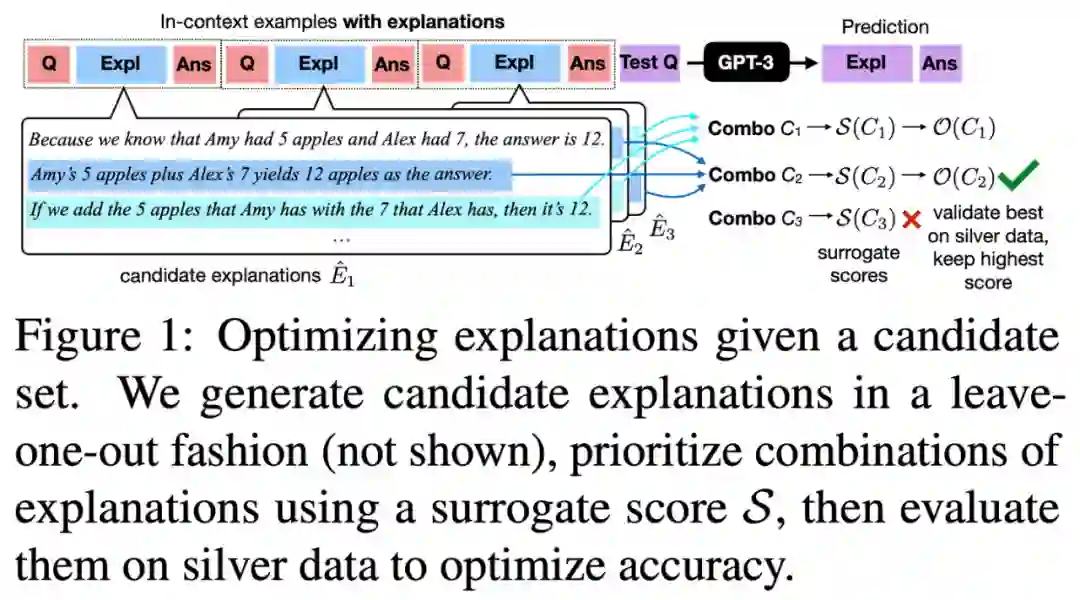
Explanation Selection Using Unlabeled Data for Chain-of-Thought Prompting CoF-CoT: Enhancing Large Language Models with Coarse-to-Fine Chain-of-Thought Prompting for Multi-domain NLU Tasks
**作者:**Hoang H. Nguyen, Ye Liu, Chenwei Zhang, Tao Zhang, Philip S. Yu https://arxiv.org/abs/2310.14623 尽管思维链的方法在推理任务中颇受欢迎,但其在自然语言理解任务中的潜力尚未被充分挖掘。 本文受到大语言模型进行多步推理的启发,提出了从粗到细的思维链(CoF-CoT)方法,该方法将自然语言理解任务分解为多个推理步骤,用基于语义的抽象意义表示结构化知识作为中间步骤,以捕捉话语的细微差别和多样结构,以便大语言模型获取并利用关键概念以从不同的粒度解决任务。
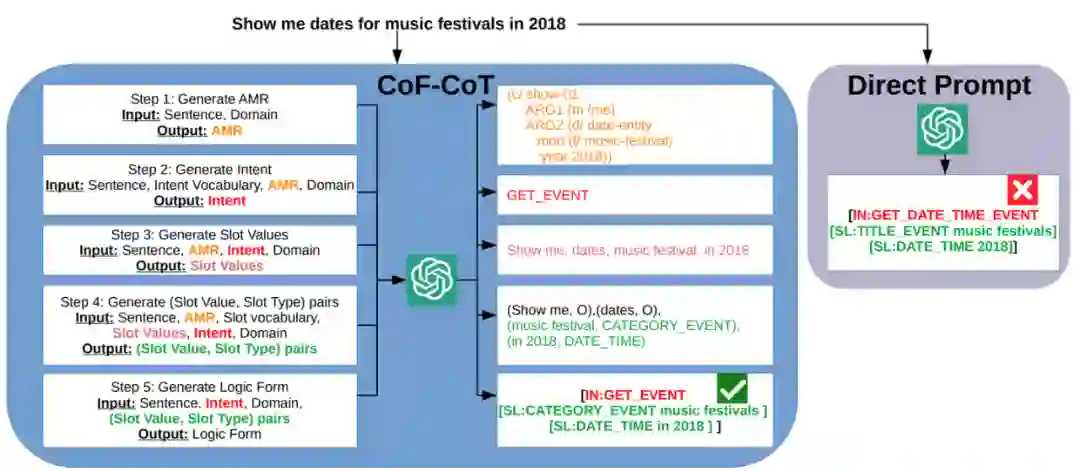
CoF-CoT Chain of Code: Reasoning with a Language Model-Augmented Code Emulator
**作者:**Chengshu Li, Jacky Liang, Andy Zeng, Xinyun Chen, Karol Hausman, Dorsa Sadigh, Sergey Levine, Li Fei-Fei, Fei Xia, Brian Ichter https://arxiv.org/abs/2312.04474 代码提供了构建复杂程序和进行精确计算的通用语法结构,当与代码解释器配对时,大语言模型可以利用编写代码的能力来改进思维链推理。因此,代码可以帮助语言模型更好地进行推理,特别是在涉及逻辑和语义混合的任务中。 本文提出了代码链(Chain of Code),旨在提升语言模型在处理逻辑、算术以及语义任务时的推理能力。利用大语言模型将语义子任务格式转化为灵活的伪代码,解释器可以明确捕捉到未定义的行为,并将其交给大语言模型来模拟执行。实验表明,“代码链”在各种基准测试中都超越了“思维链”(Chain of Thought)和其他基线方法;在BIG-Bench Hard测试中,“代码链”达到了84%的准确率,比“思维链”高出12%。

Chain of Code Tree Prompting: Efficient Task Adaptation without Fine-Tuning
**作者:**John X. Morris, Chandan Singh, Alexander M. Rush, Jianfeng Gao, Yuntian Deng https://arxiv.org/abs/2310.14034 尽管提示是让语言模型适应新任务的常用方法,但在较小的语言模型中,相比于基于梯度的微调方法,这种方法在准确度上通常较低。 针对这一挑战,本文提出了一种“树形提示(Tree Prompting)”的方法。这种方法建立了一个决策树状的提示系统,将多个语言模型调用串联起来,协同完成特定任务。在推理阶段,每一次对语言模型的调用都依靠决策树来高效地确定,基于前一次调用的结果进行决定。实验结果表明,在各种分类任务的数据集上,树形提示不仅提升了准确性,而且与微调方法相比更具有竞争力。
Tree Prompting Everything of Thoughts: Defying the Law of Penrose Triangle for Thought Generation
**作者:**Ruomeng Ding, Chaoyun Zhang, Lu Wang, Yong Xu, Minghua Ma, Wei Zhang, Si Qin, Saravan Rajmohan, Qingwei Lin, Dongmei Zhang https://arxiv.org/abs/2311.04254 有效的思维设计需要考虑三个关键方面:性能、效率和灵活性。然而,现有的思维设计最多只能体现这三个属性中的两个。为了突破现有思维范式的“彭罗斯三角形定律”局限,本文引入了一种创新的思维提示方法,称为“Everything of Thought”(XoT)。 XoT运用了预训练的强化学习和蒙特卡洛树搜索,将外部领域知识整合进思维中,从而增强大语言模型的能力,并使其能够高效地泛化到未见过的问题。通过利用蒙特卡罗搜索和大语言模型的协作思维修正框架,这种方法可以自主地产生高质量的全面认知映射,并且只需最少的大语言模型的交互。此外,XoT赋予了大语言模型进行无约束思维的能力,为具有多重解决方案的问题提供灵活的认知映射。实验表明,XoT在包括24点游戏、8数码、口袋魔方等多个具有挑战性的多解决方案问题上超过了现有方法。
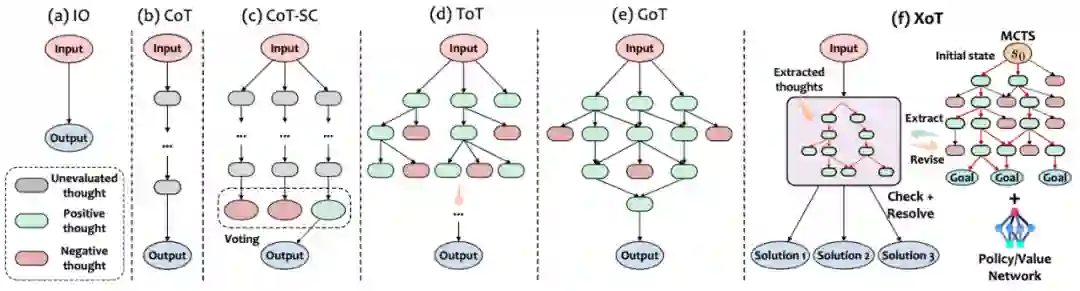
XoT
提示优化方法
提示是利用大语言模型解决各种任务的主要方法。由于提示的质量在很大程度上会影响大语言模型在特定任务中的表现,因此出现了一系列研究,旨在通过手动创建或自动优化来生成适当的任务提示。虽然手动创建任务提示更直观,但这个过程非常耗时,更重要的是,模型对精心设计的提示非常敏感——不恰当的提示将导致任务表现不佳。因此,一系列的研究自动优化离散提示,以激发大语言模型解决特定任务的能力。 Prompt Optimization via Adversarial In-Context Learning
**作者:**Xuan Long Do, Yiran Zhao, Hannah Brown, Yuxi Xie, James Xu Zhao, Nancy F. Chen, Kenji Kawaguchi, Michael Qizhe Xie, Junxian He https://arxiv.org/abs/2312.02614 adv-ICL方法借鉴了对抗生成网络的思想,通过采用三个不同的大语言模型,分别作为生成器、辨别器和提示修改器来优化提示。在这个对抗性学习框架中,生成器和鉴别器之间进行类似于传统对抗性学习的双边游戏,其中生成器尝试生成足够逼真的输出以欺骗鉴别器。 具体来说,在每一轮中,首先给定包含一个任务指令和几个样例的输入,生成器产生一个输出。然后,辨别器的任务是将生成器的输入输出对分类为模型生成的数据还是真实数据。基于辨别器的损失,提示修改器会提出对生成器和辨别器提示的编辑,选择最能改善对抗性损失的文本修改方法以优化提示。实验表明,adv-ICL在11个生成和分类任务上取得了显著的提升,包括总结、算术推理、机器翻译、数据到文本生成,以及MMLU和Big-Bench Hard基准测试。
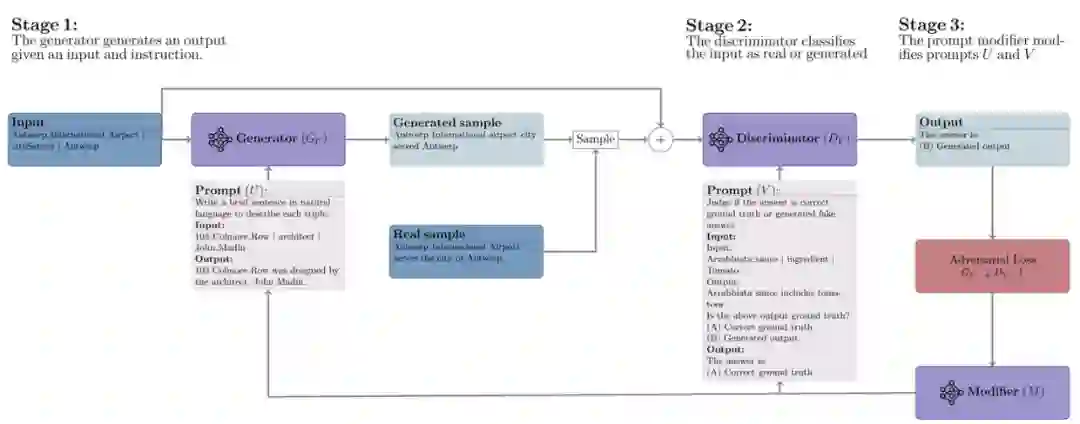
adv-ICL Black-Box Prompt Optimization: Aligning Large Language Models without Model Training
**作者:**Jiale Cheng, Xiao Liu, Kehan Zheng, Pei Ke, Hongning Wang, Yuxiao Dong, Jie Tang, Minlie Huang https://arxiv.org/abs/2311.04155 虽然大语言模型在多种任务中展现了令人印象深刻的成功,但这些模型往往与人类的意图不完全对齐。为了使大语言模型更好地遵循用户指令,现有的方法主要集中在对模型进行额外的训练上。然而,额外训练大语言模型通常计算开销很大;并且,黑盒模型往往无法进行用户需求的训练。 本文提出了BPO的方法,从不同的视角——通过优化用户的提示,来适应大语言模型的输入理解,从而在不更新大语言模型参数的情况下实现用户意图。实验表明,通过BPO对齐的大语言模型在性能上可以胜过使用PPO和DPO对齐的相同模型,并且将BPO与PPO或DPO结合,还可以带来额外的性能提升。
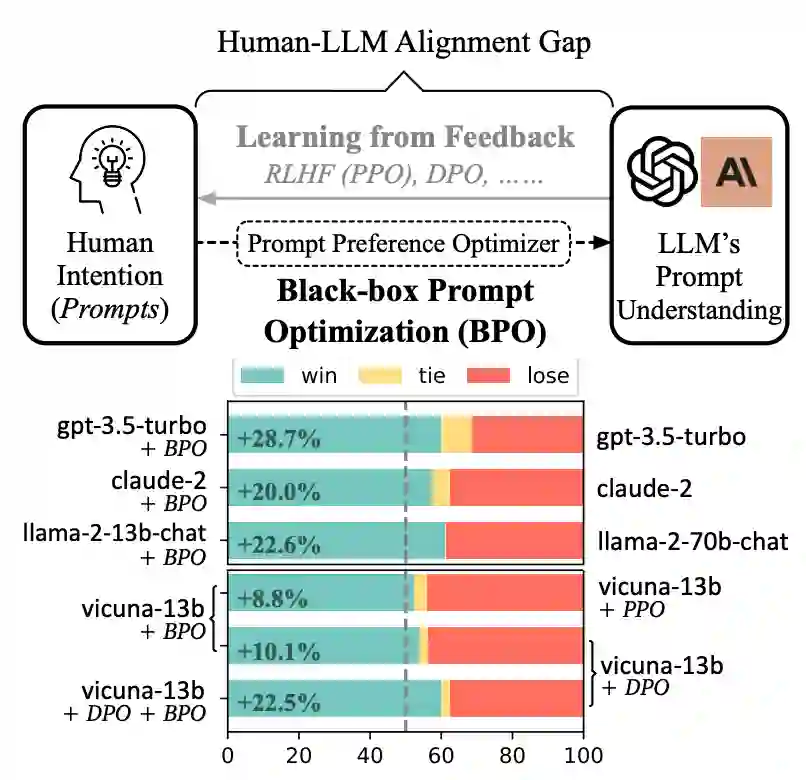
BPO Robust Prompt Optimization for Large Language Models Against Distribution Shifts
**作者:**Moxin Li, Wenjie Wang, Fuli Feng, Yixin Cao, Jizhi Zhang, Tat-Seng Chua https://arxiv.org/abs/2305.13954 大语言模型在多种自然语言处理任务中展现了显著的能力。然而,它们的效果高度依赖于任务的提示。本文发现,虽然自动的提示优化技术使用带标注的任务数据能带来性能上的提升,但这些自动提示优化的技术容易受到分布偏移的影响,这在实际应用场景中是很常见的。基于此,本文提出了一个新问题,针对分布变化对大语言模型进行稳定的提示优化,这要求在具有标签的源数据上优化的提示同时能够泛化到未标记的目标数据上。 为了解决这个问题,本文提出了一种名为“泛化提示优化”(Generalized Prompt Optimization)的框架,将来自目标组的未标记数据纳入提示优化中。广泛的实验结果表明,本文提出的框架在未标注的目标数据上有显著的性能提升,并且在源数据上保持了性能。这表明该方法在在面对分布变化时,展现出处理真实世界数据时的有效性和鲁棒性。
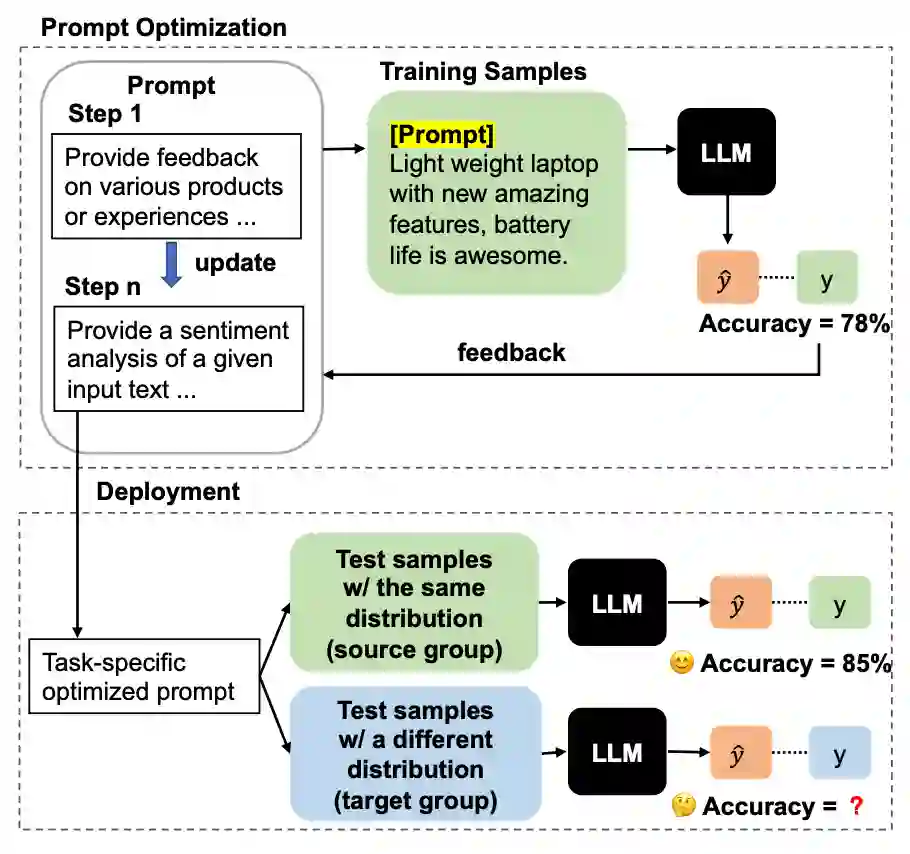
Robust Prompt Optimization InstOptima: Evolutionary Multi-objective Instruction Optimization via Large Language Model-based Instruction Operators
**作者:**Heng Yang, Ke Li https://arxiv.org/abs/2310.17630 在大语言模型中,基于指令的语言建模受到了显著的关注。然而,指令工程的效率仍然较低,最近的研究集中在自动化生成指令上,但它们主要旨在提高性能,而没有考虑影响指令质量的其他重要目标,例如指令长度和困惑度。 因此,本文提出了一种新颖的方法(InstOptima),将指令生成视为一个进化的多目标优化问题。与基于文本编辑的方法不同,本文的方法利用大语言模型来模拟指令操作,包括变异和交叉。此外,本文的方法还为这些操作引入了一个目标引导机制,允许大语言模型理解目标并提高生成指令的质量。实验结果证明了InstOptima在自动化生成指令和提升指令质量方面的有效性。
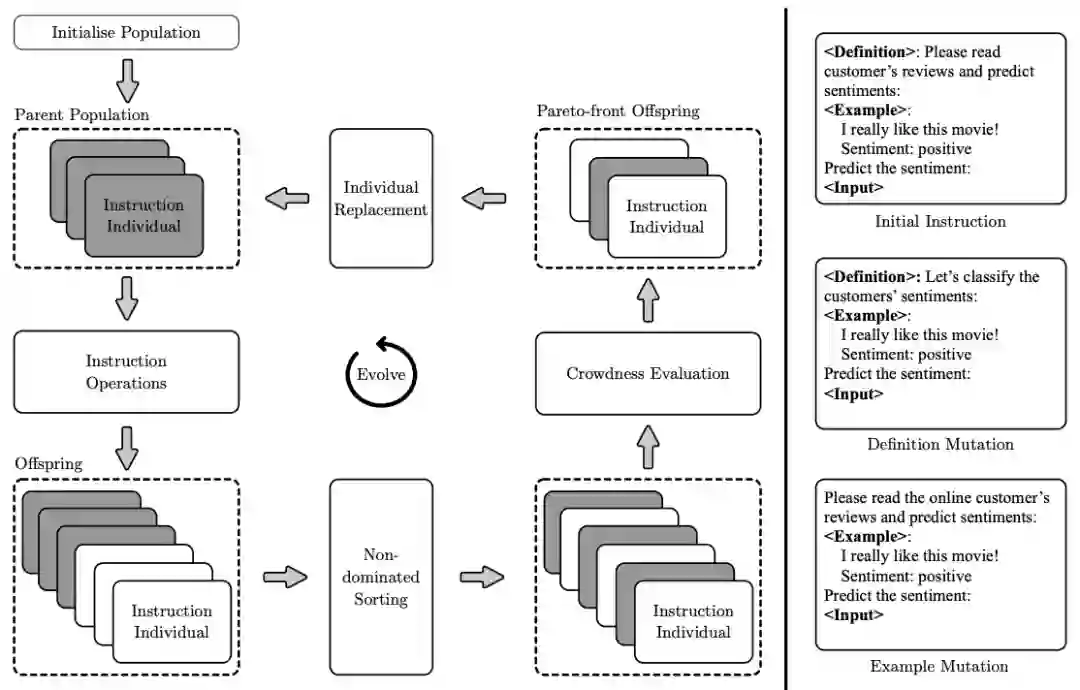
InstOptima
关于提示的分析
How are Prompts Different in Terms of Sensitivity?
**作者:**Sheng Lu, Hendrik Schuff, Iryna Gurevych https://arxiv.org/abs/2311.07230 上下文学习(ICL)已成为十分受欢迎的学习范式之一。尽管目前有越来越多的工作关注于提示工程,但在比较不同模型和任务提示效果的方面,缺乏系统性地分析。因此,本文提出了一种基于函数敏感性的全面提示分析。 本文的分析揭示了敏感性是模型性能的一种无监督代理指标,它与准确度呈现出强烈的负相关关系。本文使用基于梯度的显著性分数展示了不同提示如何影响输入对输出的相关性,从而产生不同水平的敏感性。此外,本文引入了一种基于敏感性感知的解码方式,将敏感性估计作为惩罚项纳入标准的贪婪解码中。实验表明,这种方法在输入信息稀缺时十分有效。
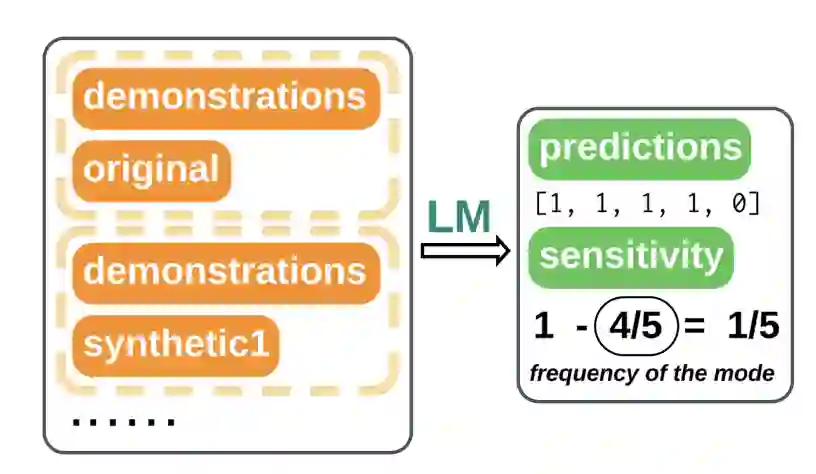
How are Prompts Different in Terms of Sensitivity? The language of prompting: What linguistic properties make a prompt successful?
**作者:**Alina Leidinger, Robert van Rooij, Ekaterina Shutova https://arxiv.org/abs/2311.01967 尽管大语言模型的表现高度依赖于提示的选择,目前仍缺乏对于提示的语言属性如何与任务表现相关联的系统性分析。 在这项工作中,文章研究了不同大小、预训练和指令调优过的大语言模型,在语义上等价但在语言结构上有所不同的提示上的表现。本文着重考察了诸如语气、时态、情感等语法属性,以及通过同义词使用引入的词汇-语义变化。研究结果与普遍的假设相悖,大语言模型在低困惑度的提示上达到最优表现,这些提示反映了预训练或指令调优数据中使用的语言。提示在不同数据集或模型之间的可迁移性较差,且性能通常不能通过困惑度、词频、歧义性或提示长度来解释。