八千字长文深度解读,迁移学习在强化学习中的应用及最新进展
机器之心原创
迁移学习通过将源任务学习到的经验应用到目标任务,从而让目标任务的训练更灵活高效,也更贴近现实情况——往往要解决的目标问题可能很难直接学习,因为训练数据不足或者无法直接与环境交互难以获得训练数据。因此将迁移学习应用到强化学习中,势必能帮助强化学习更好地落地到实际问题。本文将从迁移学习、强化学习中的迁移学习、强化学习中的迁移技术最新进展三个部分向大家分享。
Part 1 迁移学习
一、迁移学习是什么?
机器学习技术在许多领域取得了重大成功,但是,许多机器学习方法只有在训练数据和测试数据在相同的特征空间中或具有相同分布的假设下才能很好地发挥作用。当分布发生变化时,大多数统计模型需要使用新收集的训练数据重建模型。在许多实际应用中,重新收集所需的训练数据并重建模型的代价是非常昂贵的,在这种情况下,我们需要在任务域之间进行知识迁移 (Knowledge Transfer) 或迁移学习 (Transfer Learning),避免高代价的数据标注工作。
比如说,我们在一个感兴趣的领域中有一个分类任务,但我们只在另一个感兴趣的领域中有足够的训练数据,其中后者的数据可能在不同的特征空间中或遵循不同的数据分布,我们希望能够从后者中将知识进行迁移从而帮助完成前者的任务。现实生活中就有许多迁移学习的例子,比如说,掌握 C++语言有助于快速上手 Java、Python 等。人们可以聪明地应用以前学到的知识来更快更有效地解决新的问题,这就是一种迁移学习。
迁移学习的定义[1] 如下:给定一个源域 Ds 和学习任务 Ts,一个目标域 Dt 和学习任务 Tt,迁移学习致力于通过使用源域 Ds 和源任务 Ts 中的知识,帮助提升目标域 Dt 中的目标预测函数 f_T() 的学习,其中 Ds≠Dt,或者 Ts≠Tt。
二、迁移学习的三个主要研究问题
在迁移学习中主要研究以下三个问题:
迁移什么
如何迁移
何时迁移
「迁移什么」指的是跨域或跨任务迁移哪一部分知识。一些知识可能是特定于单个域或任务的,而一些知识可能在不同域之间是相同的,通过迁移知识的选择可以帮助提高目标域或任务的性能。目前,迁移学习的内容主要可分为四类:实例迁移、特征表示迁移、参数迁移、关系知识迁移。
在发现可以迁移的知识之后,需要开发学习算法来迁移知识,这就是「如何迁移」的问题。
而「何时迁移」指的是在什么情况下可以进行迁移,在哪些情况下不应该迁移。在某些情况下,当源域和目标域彼此不相关时,强行进行迁移可能会失败。而在最坏的情况下,它甚至可能损害目标域的学习表现,这种情况通常被称为负迁移。当前有关「迁移什么」和「如何迁移」的大多数迁移学习工作都暗含源域和目标域彼此相关这一假设。但是,如何避免负迁移仍旧是迁移学习领域受关注的问题。
三、迁移学习方法划分
根据迁移学习的定义,表 1 中总结了传统机器学习与各种迁移学习设置之间的关系,其中根据源域和目标域与任务之间的不同情况,将迁移学习分为三个类别:
归纳式迁移学习(Inductive Transfer Learning)
无监督迁移学习(Unsupervised Transfer Learning)
-
直推式迁移学习(Transductive Transfer Learning)

1. 在归纳式迁移学习设置中,无论源域和目标域是否相同,目标任务都与源任务不同。算法利用来自源域的归纳偏差帮助改进目标任务。根据源域中数据的不同情况,归纳式迁移学习进一步分为两种情况:
1)源域中有很多带标签的数据。在这种情况下,归纳式迁移学习设置类似于多任务学习设置。但是,归纳式迁移学习设置仅旨在通过迁移源任务中的知识来实现目标任务中的高性能,而多任务学习则尝试同时学习目标任务和源任务;
2)源域中没有标签数据。在这种情况下,归纳迁移学习设置类似于自学习。在自学习设置中,源域和目标域之间的标签空间可能不同,这意味着不能直接使用源域的信息。
2. 在无监督迁移学习设置中,与归纳迁移学习设置类似,目标任务不同于源任务,但与源任务有关。然而,无监督的迁移学习侧重于解决目标域中的无监督的学习任务,例如聚类,降维和密度估计。在这种情况下,源域和目标域中都没有可用的标签数据。
3. 在直推式迁移学习设置中,源任务和目标任务是相同的,而源域和目标域是不同的。在这种情况下,目标域中没有可用的标签数据,而源域中有许多可用的标签数据。另外,根据源域和目标域之间的不同情况,我们可以进一步将直推式学习设置分为两种情况:
1)源域和目标域之间的特征空间不同;
2)源域和目标域之间的特征空间相同,但输入数据的边际概率分布不同。
Part 2 强化学习中的迁移学习
一、描述强化学习中的迁移问题
强化学习是一种根据环境反馈进行学习的技术。强化学习 agent 辨别自身所处的状态 (state),按照某种策略决定动作(action),并根据环境提供的奖赏来调整策略,直至达到最优。马尔可夫决策 MDP(Markov Decision Process)是强化学习任务的标准描述,我们定义一个任务 M,用四元组< S , A , T, R>表示,其中 S 是状态空间,A 是动作空间,T 是状态转移概率,R 是奖赏函数。state-action 空间 S×A 定义了任务的域,状态转移概率 T 和奖赏函数 R 定义了任务的目标。当强化学习的状态动作空间 S×A 很大时,为了寻找最优策略,搜索过程非常耗时。此外,学习近似最优解所需的样本数量在实际问题中往往令人望而却步。无论是基于值的方法还是基于策略的方法,只要问题稍稍变动,之前的学习结果就会失效,而重新训练的代价巨大。因此,研究者们针对强化学习中的迁移学习展开了研究,希望能够将知识从源任务迁移到目标任务以改善性能。
二、对强化学习中的迁移进行分类

表 2:RL 中迁移学习的三个维度。每个迁移解决方案都是为特定设置设计的,传输某种形式的知识,追求某一目标。
关于强化学习中的迁移研究已经有很多,这些研究涉及到许多不同的迁移问题。由于在处理这一复杂而具有挑战性的问题时采用的方法和思路大不相同,因此通常很难清晰地了解 RL 的当前最新技术。在 [2] 中,Lazaric A 从主要的迁移设置,迁移的知识种类以及迁移目标这三个方面,对强化学习中的迁移进行分类,如表 2 所示。
设定(setting):
根据源任务数量和与目标域之间的差异,强化学习中的迁移设定如图1所示,有以下三种:
1)从单一源任务到目标任务的固定域迁移。任务域由其状态-动作空间 S×A 决定,而任务的具体结构和目标由状态转移模型 T 和奖励函数 R 决定。RL 中迁移学习的早期研究大多任务域是固定的且只涉及两个任务:一个源任务和一个目标任务。
2)跨多个源任务到目标任务的固定域迁移。在这种情况下,任务共享相同的域,迁移算法将以从一组源任务中收集到的知识作为输入,并使用它来改进在目标任务中的表现。
3)源任务和目标任务不同域迁移。在该设置中,任务有不同的状态-动作空间,无论是在数量上还是范围上。在这种情况下,大多数迁移方法都着重于如何定义源状态-动作变量和目标变量之间的映射,以便获得有效的知识迁移。
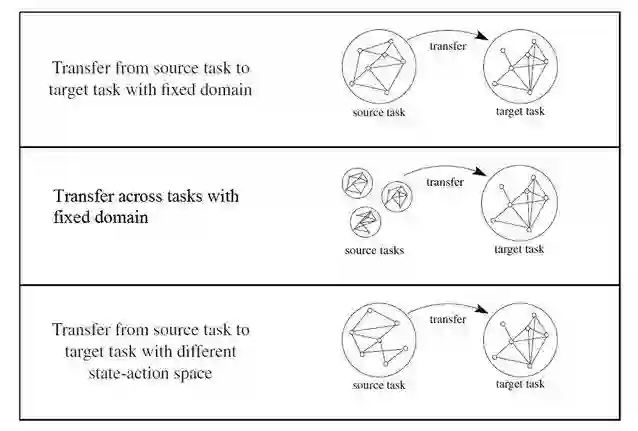
图1: 根据源任务数量和与目标任务的任务域差异而定义的三种主要的迁移设定 (图修改自 [2])
知识 (Knowledge):
1. 实例迁移 (Instance Transfer)。RL 算法依赖于从与 MDP 的直接交互中收集的一组样本来为手头的任务构建解决方案。这组样本可以用于在基于模型的方法中估计 MDP 模型,或者在无模型方法中构建值函数或策略的近似。最简单的迁移算法收集来自不同源任务的样本,并将其重用于目标任务的学习。
2. 特征迁移(Representation Transfer)。每种 RL 算法对于任务和解决方案都使用特定的表示,如神经网络,或一组近似最优值函数的基函数。在不同任务的学习过程中,迁移算法通常会改变任务和解的表示形式以进行目标任务的学习。
3. 参数迁移(Parameter Transfer)。RL 算法有大量参数定义了初始化和算法行为。一些迁移方法根据源任务改变和调整算法参数。例如,如果某些状态-动作对中的动作值在所有源任务中都非常相似,则可以据此将目标任务的 Q-table 初始化,从而加快学习过程。初始解决方案 (策略或值函数) 通常被用来在只有一个源任务的迁移设置中初始化算法。
目标 (Objective):
1. 学习速度的提升。学习算法的复杂性通常由实现所需性能所需的样本数量来衡量。在实践中,可以使用时间与阈值,面积比,有限样本分析等来衡量学习速度的提升。通过设置阈值,并测量单任务和迁移算法需要多少经验 (如样本、片段、迭代) 来达到这个阈值,以判定迁移效果。面积比度量方法通过考虑迁移学习前后学习曲线下的区域进行度量。
2. 初始(JumpStart)提升。通过从源任务进行迁移,看 agent 在目标任务中的初始性能的提升来衡量迁移学习的效果。学习过程通常从假设空间中的随机或任意的假设开始。根据环境的定义,所有的任务都来自同一个分布Ω。
3. 渐进(Asymptotic)提升。在大多数实际感兴趣的问题中,最优值函数或策略的完美近似是不可能的。使用函数逼近技术,近似值越精确,收敛性越好。近似的准确率严格依赖于用于表示解决方案的假设空间的结构。该目标就是看迁移学习后,Agent 最终表现的提升。
Part 3 强化学习中的迁移应用最新进展
笔者整理了部分结合强化学习与迁移学习的最新技术研究,速览如下:
《Transfer Learning For Related Reinforcement Learning Tasks Via Image-to-Image Translation(ICLR-2019)》
中文名:通过图像到图像翻译的相关强化学习任务的转移学习
论文链接:https://arxiv.org/abs/1806.07377
代码链接:http://github.com/ShaniGam/RL-GAN
论文速览:尽管深度 RL 在从原始像素中学习控制策略取得了巨大的成功,但是结果模型泛化能力太差。作者使用 Atari Breakout 游戏 (打砖块游戏),证明了训练后的 agent 难以应对小的视觉变化(比如说在背景上增加矩形图案作干扰,或者在背景上添加一些对角线,人类可以轻松适应这些小的变化,如图 2)。
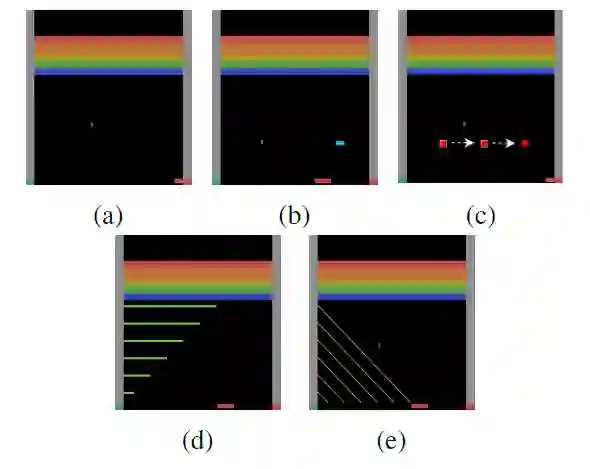
图 2 :(a) 为原始版本的打砖块游戏,其余为在背景上添加了一些小的视觉变化。(b) 添加固定蓝色矩形干扰,(c) 红色矩形在三个固定位置闪现 (d) 绿色线条干扰 (e) 对角线干扰。
作者使用常见的迁移学习策略——微调,来应对这些视觉上的改变却遭遇了惨败。甚至从某种程度上来说,从头开始对 agent 进行训练比对经过训练的 agent 进行微调还要更快。因此,作者建议通过添加专用组件来改善迁移学习,该组件的目标是学习在已知域和新域之间进行映射。作者提议将视觉迁移和动态迁移分开,agent 尝试从新域到旧域进行类比:观察新域中的一组状态(图像)后,代理可以学习将其映射到源域中相似熟悉的状态,并根据其源域策略对映射状态采取行动。
更具体地来说,给定具有训练参数θ的训练策略π(a|s;θ) 提出针对源域状态 s∈S 的动作 a,希望从目标域状态 t∈T 学习映射函数 G:T→S 这样,通过应用策略π(a|G(t));θ) 与环境 T 进行交互。也就是寻求一个映射函数 G,该函数允许在与目标环境 T 交互时重用为源环境 S 学习的相同策略πθ。由于源域项目和目标域项目都是图像,因此通过从 S 和 T 收集图像集并使用 Unaligned GAN 直观地映射它们之间的图像来启发式学习函数 G。作者将通过π(a|G(t));θ) 与环境相互作用获得的分数用于 GAN 模型选择和停止标准。
作者使用 unaligned GAN 创建映射,以将目标任务中的图像转换为源任务中的相应图像。这种映射使得能够在 Breakout 游戏的各种变体之间以及 Road Fighter 游戏的不同级别之间进行迁移。结果显示,学习此映射比重新训练更有效。作者给出了本文方法在两种游戏上的可视化效果,图 3 给出 Breakout 上的可视化动图。
此外,这篇论文的 review 也非常有意思,值得一看:https://openreview.net/forum?id=rkxjnjA5KQ

图 3:Breakout 游戏上的可视化动图。视频来源 https://www.youtube.com/watch?v=4mnkzYyXMn4&feature=youtu.be
《Transfer in Deep Reinforcement Learning using Knowledge Graphs》
中文名:使用知识图谱的深度强化学习中的迁移
论文链接:https://arxiv.org/pdf/1908.06556.pdf
论文速览:文字类冒险游戏是一种玩家必须通过文本描述来了解世界,通过相应的文本描述来声明下一步动作的游戏(有点像大家比较熟知的橙光小游戏)。教 agent 玩文字类冒险游戏是一项具有挑战性的任务,学习它的控制策略需要大量的探索。主要原因是大多数深度强化学习算法都是在没有真实先验的情况下针对任务进行训练的,从本质上来说,agent 必须从与环境的交互中了解关于游戏的一切。然而文字类冒险游戏充分利用了常识知识(比如斧头可以用来砍木头)和一些类型主题(在恐怖题材的游戏中,棺材里可能会有吸血鬼等等),游戏本身就是个谜,因此也导致了训练效率低下。
知识图是一个有向图,由一组语义三元组(主体,关系,对象)构成。在本文中,作者探索使用知识图和相关的神经嵌入作为域知识迁移的表示形式,以训练文字类冒险游戏的强化学习 agent,从而减少训练时间并提高所学习控制策略的质量。作者在 KG-DQN 的基础上展开他们的工作,探索知识图和网络参数的迁移。从静态文本资源中提取出 graph,并使用它向 agent 提供特定领域的词汇,对象能力等知识。agent 也能访问游戏解析器接收到的所有 action,通过提取解析器接收到的一系列模板(用 OBJ 标记替代 action 中的 object 或者名词短语),将 OBJ 标记更换为游戏给定词汇中可能的 object 即可。DQN 网络由两个独立的神经网络构成,分别编码 state 和 action,由最终的 state-action 对的 Q 值作为两个网络之间交互的结果,使用贝尔曼方程更新。
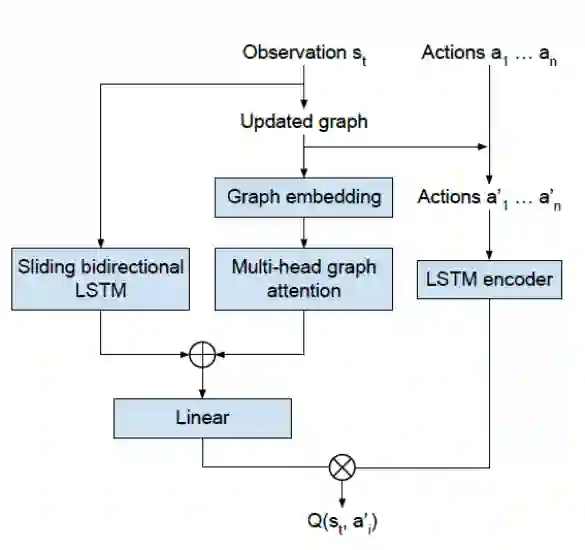
将知识图从静态文本资源迁移到 DQN 中的问题作者称之为播种,KG-DQN 使用知识图作为状态表示,并对动作空间进行精简,图 X 是随着时间的推移,通过 agent 的探索而建立起来的,当 agent 首次开始游戏时,这个图是空的,因此在 action 精简过程中帮助不大。而从另一个来源种子化知识图,比如同一故事类型的文本冒险游戏,就可以给 agent 一个强的先验。
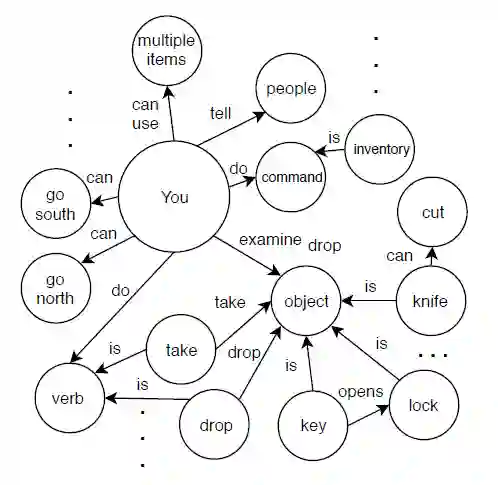
图 6 :播种知识图示意。
此外,作者证明了可以使用 DQN 网络参数权重有效地迁移知识,或者通过使用问答系统对网络的各个部分进行预训练,也可以将参数从源迁移到目标游戏。这样 agent 整体训练速度更快(包括对源任务进行预训练和训练所需的情节数量),并且与未使用这些技术的 agent 相比,其收敛性能提高了 80%。作者的方法在多种计算机生成的和人工创作的游戏中进行了测试,这些游戏的域和复杂性各不相同,通过实验作者得出结论,知识图通过为 agent 提供不同游戏的状态和动作空间之间的更明确且可解释的映射,从而使他们能够在深度强化学习 agent 中进行迁移。
《Transfer of Temporal Logic Formulas in Reinforcement Learning(IJCAI-2019)》
中文名:强化学习中时序逻辑的迁移
论文链接:https://arxiv.org/pdf/1909.04256.pdf
论文速览:将高层次知识从源任务迁移到目标任务是加快强化学习的有效方法。例如,命题逻辑和一阶逻辑已被用作这种知识的表示。作者将事件时序至关重要的那些任务称为时序任务(temporal tasks),通过逻辑可迁移性的概念具体化时序任务之间的相似性,并开发不同但相似的时序任务之间的迁移学习方法。作者首先提出一种推理技术,以从两个 RL 任务收集的标记轨迹中,按顺序析取正态形式提取度量间隔时序逻辑(MITL)公式。如果通过此推断确定了逻辑可迁移性,作者为从这两个任务推断出的 MITL 公式的每个顺序合取子式构造一个定时自动机。作者在扩展状态下执行 RL,其中包括源任务定时自动机的位置和时钟评估。然后,作者根据两个任务在定时自动机的相应组件(时钟,位置等)之间建立映射,并根据已建立的映射来迁移扩展的 Q 函数。最后,作者从迁移的扩展 Q 函数开始,对目标任务的扩展状态执行 RL。两个案例研究中的结果表明,根据源任务和目标任务的相似程度,通过在扩展状态空间中执行 RL,可以将目标任务的采样效率提高一个数量级。
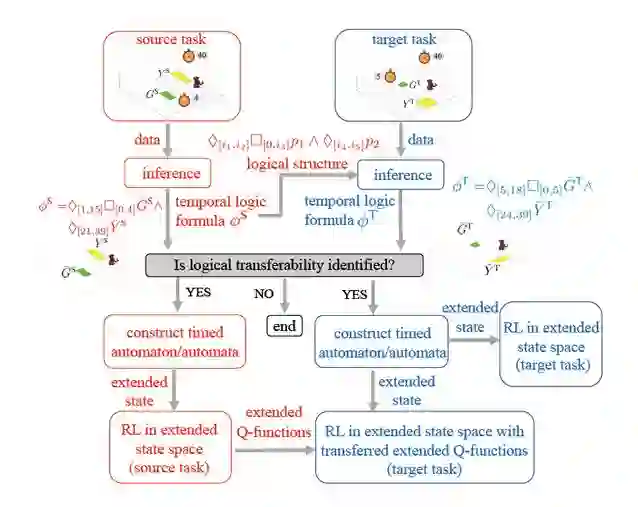
图 7:基于时序逻辑迁移的迁移学习方法工作流程图。
《Value Function Transfer for Deep Multi-Agent Reinforcement Learning Based on N-Step Returns (IJCAI-2019)》
中文名:基于 N 步返回的深度多智能体强化学习的值函数迁移
论文链接:https://www.ijcai.org/proceedings/2019/0065.pdf
论文速览:许多现实世界的问题,如机器人控制,足球比赛,都被建模为稀疏交互多 agent 系统。在具有稀疏交互的多 agent 系统中重用单 agent 知识可以极大地加速多 agent 学习过程。先前的工作依赖于互模拟度量(bisimulation metric)来定义马尔可夫决策过程(MDP)的相似性以控制知识迁移。但是,互模拟度量的计算成本很高,并且不适用于高维状态空间问题。在这项工作中,作者提出了一种基于新型 MDP 相似性概念的可扩展的迁移学习方法。首先根据 MDP 的 N 步返回值(NSR)定义 MDP 相似度。然后,作者提出了两种基于深度神经网络的知识迁移方法:直接值函数迁移和基于 NSR 的值函数迁移。作者在基于图像的网格世界,MPE 和《吃豆人》游戏中进行实验。结果表明,所提出的方法可以显著加速多 agent 强化学习,同时具有更好的渐近性能。
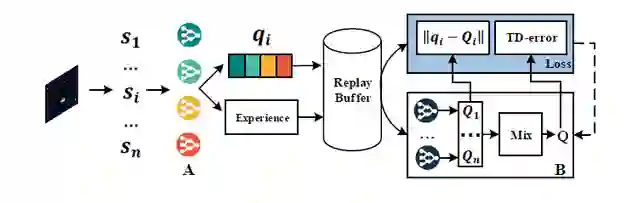
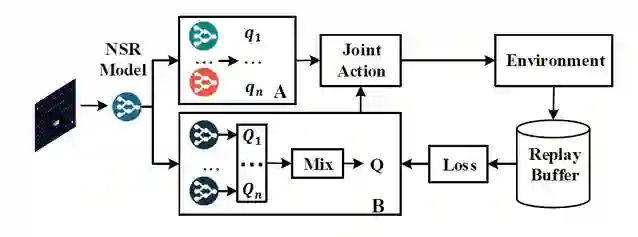
《Importance Weighted Transfer of Samples in Reinforcement Learning (ICML-2018)》
中文名:强化学习中样本的重要性权重迁移
论文链接:https://arxiv.org/pdf/1805.10886.pdf
论文速览:作者考虑从一组源任务中收集强化学习(RL)中的经验样本(即元组<s,a,s',r>)的迁移,以改善给定目标任务中的学习过程。大多数相关方法都集中于选择最相关的源样本来解决目标任务,但随后使用所有迁移的样本没有再考虑任务模型之间的差异。在本文中,作者提出了一种基于模型的技术,该技术可以自动估计每个源样本求解目标任务的相关性(重要性权重)。在所提出的方法中,所有样本都通过批强化学习算法迁移并用于解决目标任务,但是它们对学习过程的贡献与它们的重要性权重成正比。通过扩展监督学习文献中提供的重要性加权结果,作者对提出的批 RL 算法进行了有限样本分析。此外,作者将提出的算法与最新方法进行了经验比较,表明即使在某些源任务与目标任务明显不同的情况下,该算法也能获得更好的学习性能,并且对负迁移具有非常强的鲁棒性。
《StarCraft Micromanagement with Reinforcement Learning and Curriculum Transfer Learning》
中文名:强化学习和课程迁移学习进行星际争霸微操
论文链接:https://arxiv.org/pdf/1804.00810.pdf
机器之心解读:https://www.jiqizhixin.com/articles/2018-04-06-4
论文速览:实时策略游戏已成为游戏人工智能的重要领域。本文提出了一种强化学习和课程迁移学习方法,以控制星际争霸微操中的多个单元。作者定义了一种有效的状态表示形式,该表示形式可以消除游戏环境中大型状态空间所引起的复杂性。然后提出了一种参数共享的多 agent 梯度 Sarsa(λ)(PS-MAGDS)算法来训练单元。单元之间共享学习策略,以鼓励合作行为。
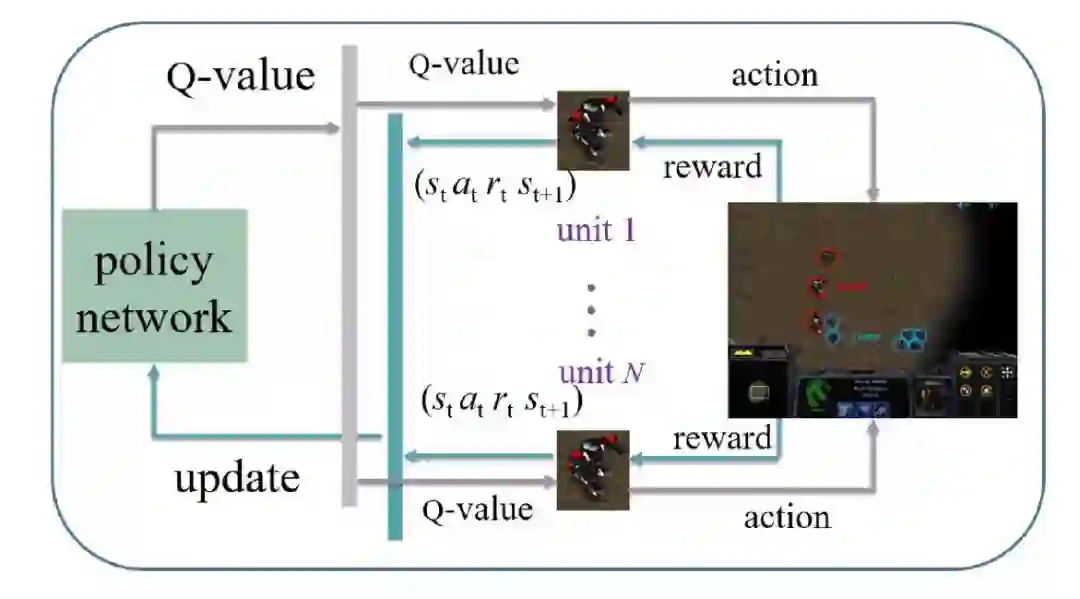
作者使用神经网络作为函数逼近器来估算动作-值函数,并提出奖赏函数以帮助部队平衡其行动和进攻。另外,使用迁移学习方法将模型扩展到更困难的场景,可以加快训练过程并提高学习性能。在小规模场景中,部队成功学习了如何以 100%的获胜率与内置 AI 战斗并击败它。在大型方案中,课程迁移学习方法用于逐步训练一组单元,并且在目标方案中显示出优于某些 baseline 方法的性能。通过强化学习和课程迁移学习,训练的单元能够在《星际争霸》微管理场景中学习适当的策略。
作者介绍
罗赛男,西安电子科技大学计算机科学与技术学院研究生,研究方向为网络空间安全与机器学习,关注前沿技术,热爱文字分享,希望能够与大家一起学习,共同进步,ღ( ´・ᴗ・` ) 比心!
参考文献:
Pan S J, Yang Q. A survey on transfer learning[J]. IEEE Transactions on knowledge and data engineering, 2009, 22(10): 1345-1359.——本文 Part 1 主要参考
Lazaric A. Transfer in reinforcement learning: a framework and a survey[M]//Reinforcement Learning. Springer, Berlin, Heidelberg, 2012: 143-173.——本文 Part 2 主要参考
Taylor M E, Stone P. Transfer learning for reinforcement learning domains: A survey[J]. Journal of Machine Learning Research, 2009, 10(Jul): 1633-1685.——本文 Part 2 主要参考
-
迁移学习各个领域的最新论文 list 集,强推 :https://github.com/jindongwang/transferlearning/blob/master/doc/awesome_paper.md
-
《综合实践指南:迁移学习及在深度学习中的应用》 -
机器之心曾推出一篇来自清华大学的关于深度迁移学习综述的解读文章《综述论文:四大类深度迁移学习》,这篇综述定义了深度迁移学习并回顾了目前关于深度迁移学习的研究工作,感兴趣的朋友可以去看看。



