

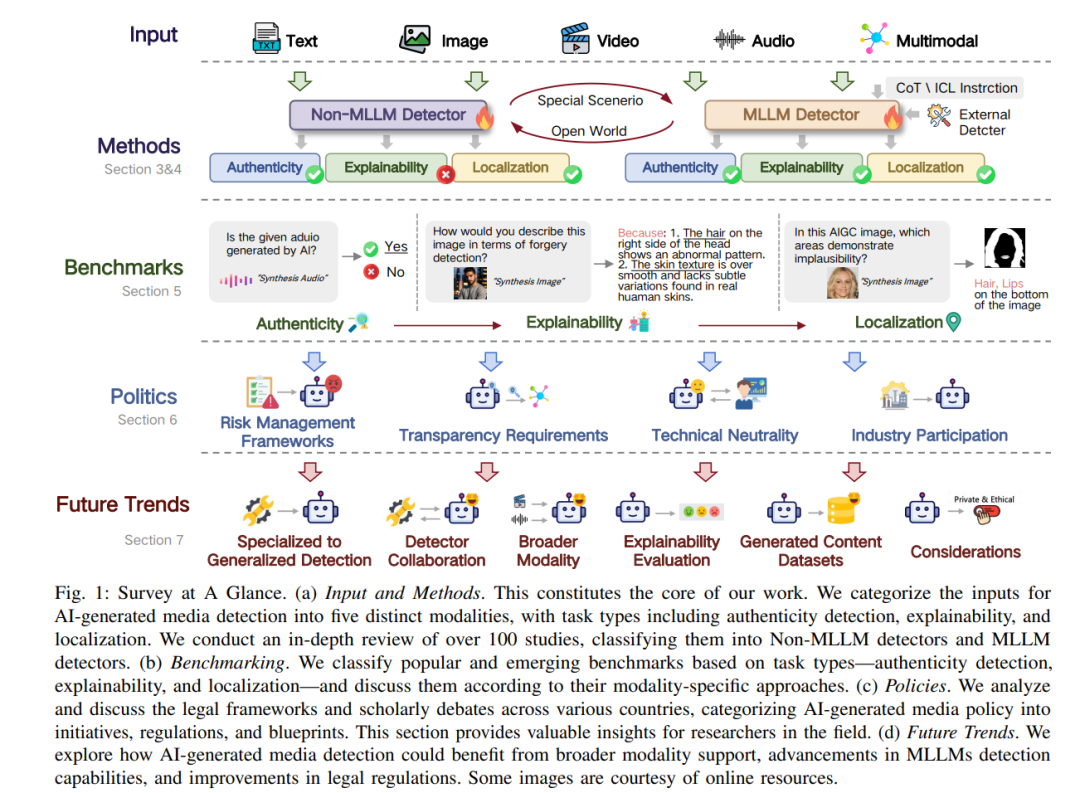
摘要—AI生成的媒体的迅猛发展对信息真实性和社会信任提出了重大挑战,因此对可靠的检测方法需求日益增加。检测AI生成媒体的方法随着多模态大语言模型(MLLMs)的发展而迅速演变。目前的检测方法可分为两大类:非MLLM方法和基于MLLM的方法。前者利用深度学习技术驱动的高精度、领域特定检测器,而后者则采用基于MLLM的通用检测器,集成了真实性验证、可解释性和定位能力。尽管该领域取得了显著进展,但关于从领域特定到通用检测方法转变的全面综述仍然存在文献空白。本文通过提供对这两种方法的系统评审来填补这一空白,从单模态和多模态的角度进行分析。我们对这两类方法进行了详细的比较分析,探讨了它们在方法论上的相似性和差异性。通过这一分析,我们探索了潜在的混合方法,并识别了伪造检测中的关键挑战,为未来的研究提供了方向。此外,随着MLLM在检测任务中的日益普及,伦理和安全问题已成为全球关注的关键问题。我们审视了不同司法管辖区内关于生成性AI(GenAI)的监管环境,提供了对该领域研究人员和从业者的宝贵见解。 关键词—AI生成媒体检测,MLLM,深度学习,文献综述
成为VIP会员查看完整内容
相关内容

Arxiv
36+阅读 · 2023年4月19日
Arxiv
190+阅读 · 2023年4月7日
Arxiv
134+阅读 · 2023年3月29日
Arxiv
20+阅读 · 2023年3月21日
相关VIP内容
相关资讯
相关论文
Arxiv
36+阅读 · 2023年4月19日
Arxiv
190+阅读 · 2023年4月7日
Arxiv
134+阅读 · 2023年3月29日
Arxiv
20+阅读 · 2023年3月21日