

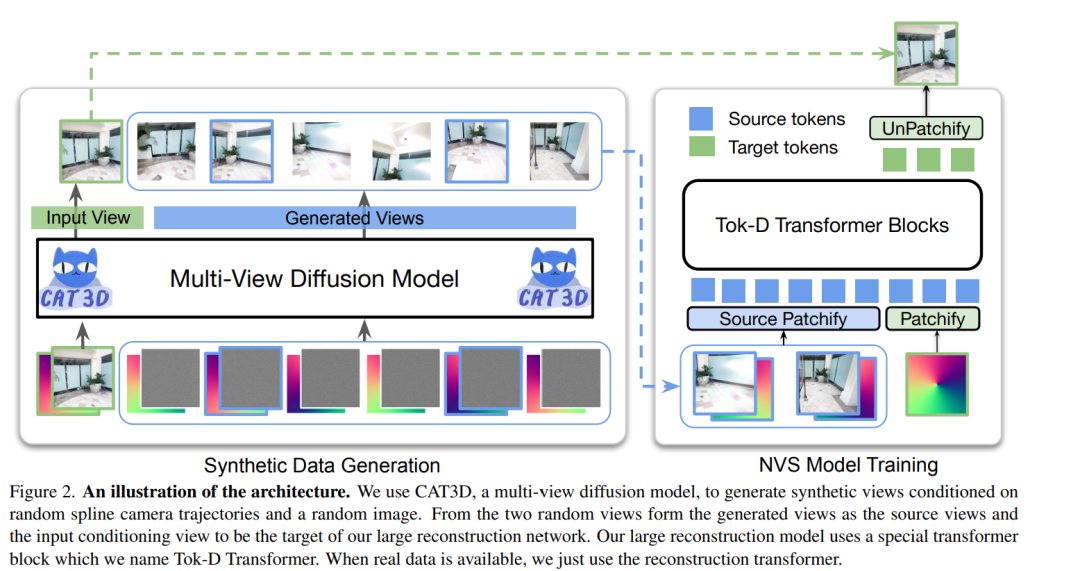
大型基于 Transformer 的模型在从稀疏输入视角生成具有良好泛化能力的新视角合成(NVS)方面取得了显著进展,这些模型能够在无需测试时优化的情况下生成新颖的视角。然而,它们仍然受限于公开可用场景数据集的多样性不足,导致大多数真实世界(in-the-wild)场景呈现分布外问题。为了解决这一局限,我们引入了由扩散模型生成的合成训练数据,从而提升了在未见领域中的泛化能力。虽然合成数据带来了可扩展性,但我们发现数据生成过程中引入的伪影成为影响重建质量的关键瓶颈。为此,我们在 Transformer 架构中提出了一种 token 解耦 过程,以增强特征分离并确保更有效的学习。这一改进不仅在重建质量上优于标准 Transformer,而且使得基于合成数据的可扩展训练成为可能。最终,我们的方法在数据内与跨数据集的评估中均优于现有模型,在多个基准上实现了最新的性能,同时显著降低了计算成本。
成为VIP会员查看完整内容
相关内容
Arxiv
218+阅读 · 2023年4月7日
Arxiv
20+阅读 · 2023年3月21日
相关主题

相关VIP内容
相关资讯
相关论文
Arxiv
218+阅读 · 2023年4月7日
Arxiv
20+阅读 · 2023年3月21日