
大规模文本到图像扩散模型,如DALL-E 2,Imagen和Stable Diffusion,在文本到图像生成任务上取得了相当大的成功。然而,它们仅提供有限的灵活性和可控性,仅通过文本进行条件控制,对最终用户来说有所不足。为了提高这种自由度,我们需要更好地调整生成过程的方法。本演讲将讨论一些最有前景和有效的方法,用于控制文本到图像扩散模型。这些方法将包括训练时和推断时技术的混合应用。








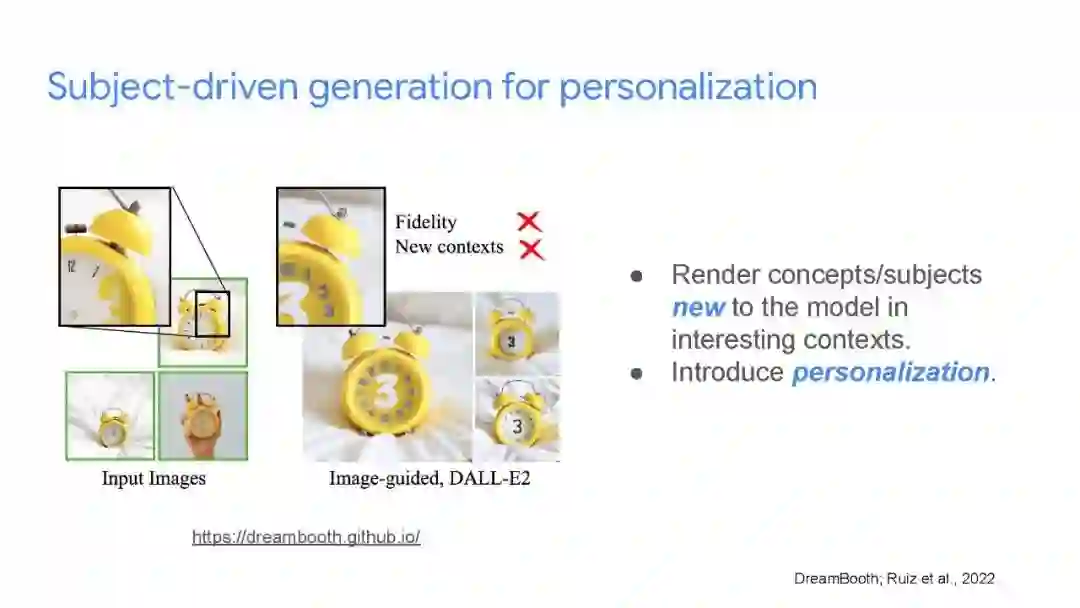
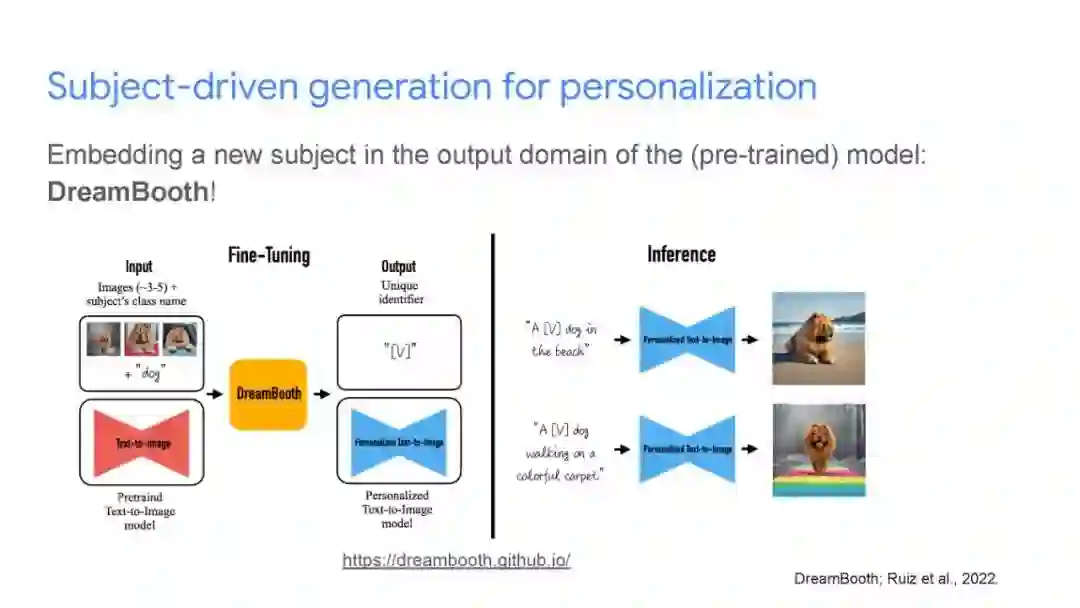
成为VIP会员查看完整内容
相关内容
专知会员服务
26+阅读 · 2022年3月1日
专知会员服务
33+阅读 · 2020年2月29日
【ICDAR2019教程】模式识别和文档图像中基于图的方法,Graph-based Methods in Pattern Recognition and Document Image Analysis
专知会员服务
30+阅读 · 2019年9月20日
Arxiv
42+阅读 · 2023年4月19日
Arxiv
225+阅读 · 2023年4月7日

相关VIP内容
专知会员服务
26+阅读 · 2022年3月1日
专知会员服务
33+阅读 · 2020年2月29日
【ICDAR2019教程】模式识别和文档图像中基于图的方法,Graph-based Methods in Pattern Recognition and Document Image Analysis
专知会员服务
30+阅读 · 2019年9月20日
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
225+阅读 · 2023年4月7日