

1. 引言
大语言模型(LLMs)(OpenAI et al., 2024; Touvron et al., 2023a,b; Dubey et al., 2024; Lozhkov et al., 2024; Liu et al., 2024a) 通过在文本生成、语言理解等多项任务上提供前所未有的性能,彻底革新了自然语言处理。然而,这些模型的卓越能力伴随着显著的计算和内存需求,这在资源有限或高并发场景中的部署带来了巨大的挑战。为应对这些挑战,低比特量化作为提升LLM效率和可部署性的关键方法,逐渐成为焦点。低比特量化涉及减少张量的比特宽度,从而有效减少 LLM 的内存占用和计算需求。通过使用低比特整数/二进制表示对 LLM 的权重、激活值和梯度进行压缩,量化可以在保持可接受精度的前提下,显著加速推理和训练,并减少存储需求。这种效率对于在资源受限的设备上实现先进的 LLM 至关重要,从而扩大其适用性。本文旨在提供一份关于大语言模型(LLM)低比特量化的全面综述,涵盖与低比特 LLM 相关的基本概念、系统实现和算法方法。与传统模型相比,LLM 作为基础模型的代表性范式,通常具有大量的参数,这给有效的量化带来了独特的挑战。图1中展示了大语言模型的低比特量化基本原理。第2节介绍 LLM 的低比特量化基础,包括低比特数据格式和特定于 LLM 的量化粒度。第3节回顾了支持低比特 LLM 在各种硬件平台上运行的系统和框架。接着,在第4和第5节中,我们对低比特量化技术在高效训练和推理中的应用进行分类。对于训练部分,我们讨论了低比特训练和 LLM 微调的方法。对于推理部分,我们通过量化感知训练和训练后量化区分 LLM 量化方法。量化感知训练通常用于低比特设置(如二进制量化),而训练后量化则更常见于现有研究中,因为它是一种资源高效的流程。为了更清晰的理解,我们首先介绍了用于减少离群值影响的等效变换技术和用于减轻量化误差的权重补偿技术。然后讨论了混合精度、结合其他压缩方法的量化技术以及新形式量化方法。此外,我们还总结了集成这些算法的工具包,以支持精确的低比特 LLM 开发。最后,第6节探讨了未来的趋势和方向,讨论了新兴的研究领域、潜在的突破以及新技术对 LLM 量化的影响。我们的综述详细描述了低比特 LLM 的基本原理,并全面概述了通过低比特量化加速训练和推理的系统实现及算法策略,以保持和提高量化后的精度。我们相信这份综述能为 LLM 量化的发展提供宝贵的见解和推动力。
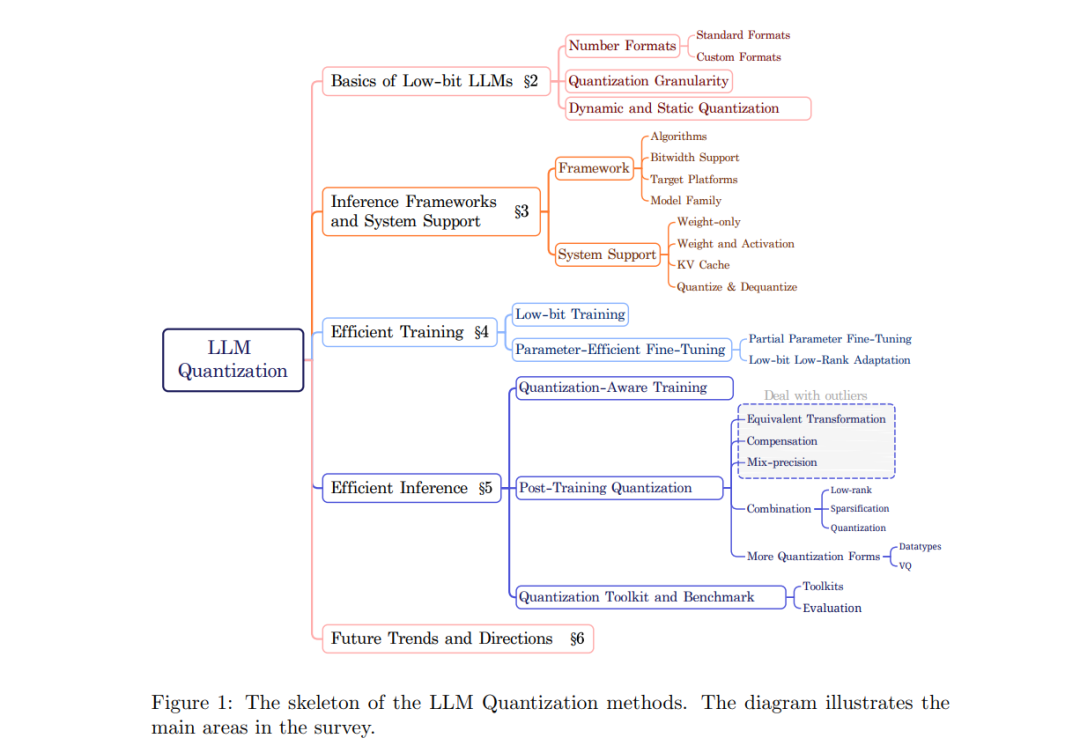
2. 低比特大语言模型的基础
在本节中,我们从三个方面介绍量化和低比特大语言模型(LLMs)的基本原理: 1. 低比特数值格式:为了处理 LLM 中的离群值,低比特浮点数首先被应用于量化中,许多自定义的数据格式也被设计用于解决离群值的问题。然而,整数格式仍然是主流。 1. 量化粒度:为了提高量化 LLM 的性能,更细粒度的量化能够保留更多信息,并产生更好的结果。但粗粒度的量化占用的存储更少,且在推理时效率更高。 1. 动态或静态量化:动态量化不需要校准,因为量化参数是在运行时计算的,这使得量化模型的准备过程更为简单。相比之下,静态量化需要预先校准量化参数,但它提供了更快的推理性能。
3. 框架与系统支持
自大语言模型(LLM)问世以来的短短几年间,已经涌现出许多支持 LLM 易用性的框架。我们在本节中选取了一些与量化相关的知名代表性框架和工具,按照以下类别进行总结和介绍:(1) 量化推理框架,它提供了全面的库和 API,以便快速开发和部署 LLM 应用;(2) 量化的系统支持,支持量化方法的底层核心功能。接下来,我们将重点讨论各种框架和库中 LLM 的量化支持。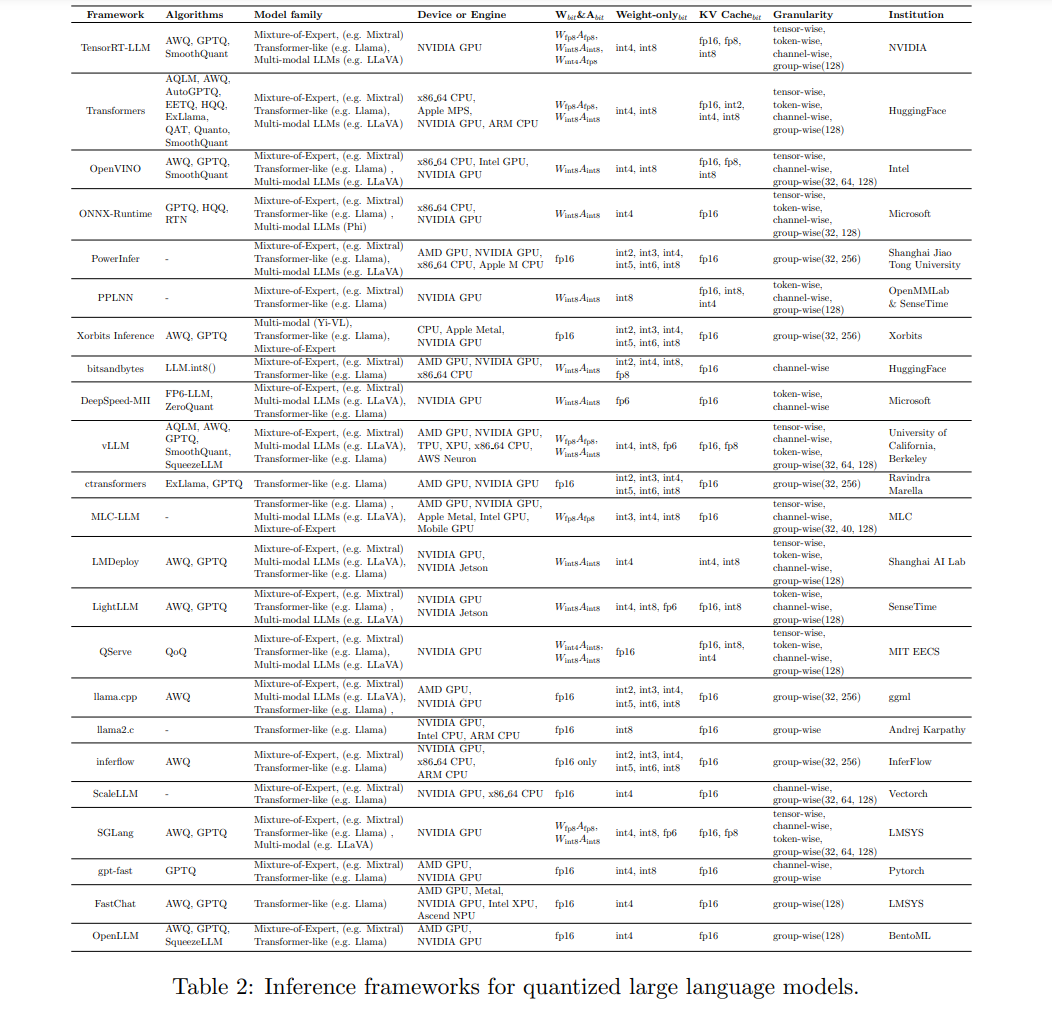
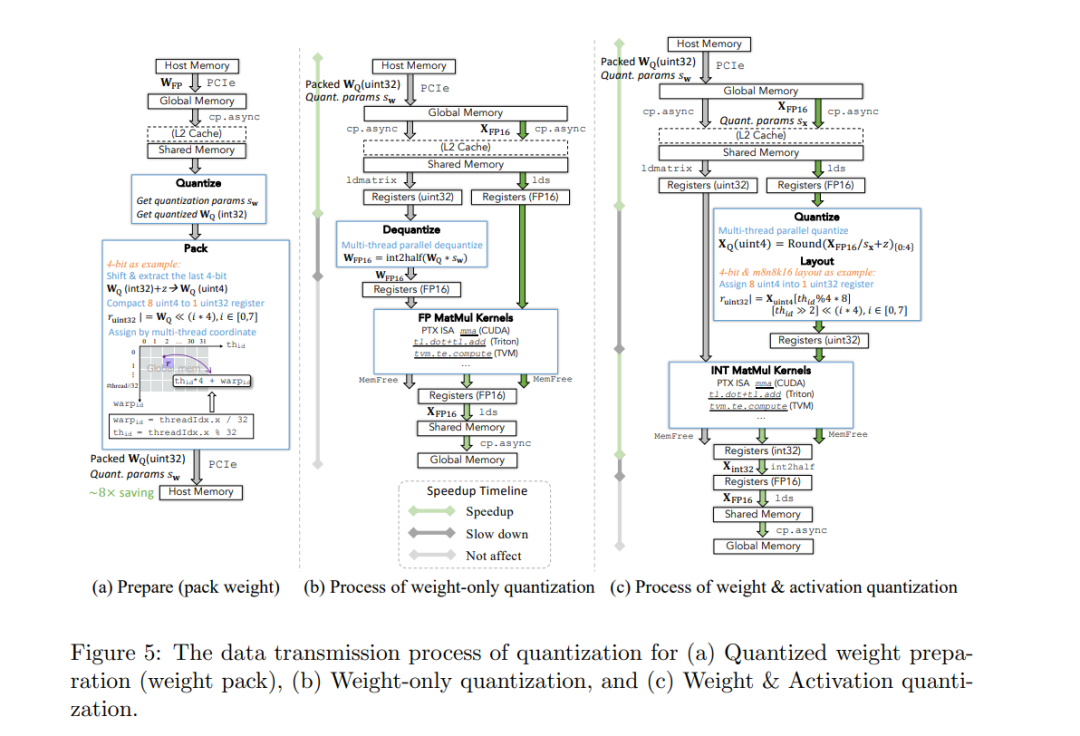
结论
在本综述中,我们对大语言模型(LLM)的低比特量化技术进行了深入探讨,重点强调了其在解决这些模型在受限环境中部署时所面临的计算和内存挑战中的重要性。我们首先阐明了低比特量化的基本原理,包括专门针对 LLM 的新型数据格式和量化粒度。我们对系统和框架的回顾展示了支持低比特 LLM 在不同硬件平台上运行的多种方法和工具。我们还对各种用于优化训练和推理的技术进行了分类和讨论,提供了对当前方法的全面理解。最后,我们探讨了该领域的未来方向和新兴趋势,强调了可能的研究领域和技术进步,这些将进一步提升 LLM 量化的效率和效果。随着 LLM 研究领域的不断演变,本综述旨在为推动低比特量化技术的发展提供有价值的参考资源。