
深度学习模型可以实现准确和高效的疾病诊断,但迄今为止,由于医学界存在的数据稀缺性而受到阻碍。自动诊断研究一直受制于力量不足的单中心数据集,尽管一些结果显示出了希望,但由于没有考虑到机构间的数据异质性,它们对其他机构的普遍性仍然是值得怀疑的。通过允许模型以分布式的方式进行训练并保护患者的隐私,联邦学习有望通过实现多中心研究来缓解这些问题。我们提出了第一个关于心血管磁共振模式的模拟联邦学习研究,并使用来自M&M和ACDC数据集子集的四个中心,专注于肥厚型心肌病的诊断。我们调整了一个在动作识别上预训练的3D-CNN网络,并探索了将形状先验信息纳入模型的两种不同方式,以及四种不同的数据增强设置,系统地分析了它们对不同协作学习选择的影响。我们表明,尽管数据规模较小(180名受试者来自四个中心),但保护隐私的联邦学习取得了有希望的结果,与传统的集中式学习相比具有竞争力。我们进一步发现,联邦训练的模型表现出更强的鲁棒性,对领域转移效应更敏感。

引言
基于人工智能模型的诊断工具在多个医学影像领域的各种单中心研究中显示出良好的效果,但其对隐形分布的通用性仍未得到充分研究,其在临床实践中的应用仍远未实现。由于数据仍然被隔离在不同的机构中,此类研究大多集中在有限的单中心数据集上进行训练和评估。除了样本量小这一明显的问题外,在这种情况下的评估是有问题的,因为不能假设这种性能如何迁移到未见过的中心。为了使ML方法能够推广到未见过的数据集,通常假设新看到的数据与训练期间看到的数据是独立和相同分布的(IID),即每个数据点来自相同的概率分布,并且与所有其他数据相互独立。由于这个原因,多中心医疗数据中存在的数据异质性构成了一个重大问题,因为在所有情况下,这些数据都是非IID的,这是使用不同的采集协议、不同的扫描仪和不同的人口统计学的直接结果。
为了克服数据稀缺的核心障碍,更好地理解不同中心之间存在的数据异质性的影响,各机构需要走到一起合作。迄今为止,这是很困难的,因为由于隐私法规(如欧盟的GDPR和美国的HIPAA),各机构都倾向于严格控制其医疗数据。虽然对于合作者来说,一个明显的方法是在中央服务器上分享他们的数据(CDS,图1A),但这通过增加数据泄漏的机会而危及患者的隐私。分布式学习允许人工智能模型在多个边缘设备或中心进行训练,而数据永远不会离开其原始位置。2017年,谷歌提出了联邦学习(FL,图1B)的框架,允许深度学习模型在本地数据上分布和训练,只在中央服务器上聚集它们的参数。中央服务器只看到初始数据的复杂表征,正如本地模型所学习的那样,这些表征在被重新分配用于后续训练之前,被一种叫做FederatedAveraging的算法所结合。
用于医学图像分析的保护隐私的联邦学习系统主要是在大脑、前列腺和COVID-19影响区域的分割方面进行探索。分割仍然是一个开放的问题,并面临多种挑战,特别是在数据收集阶段,因为专家手工注释很耗时,并在分割掩模中表现出操作者之间和内部的差异。然而,诊断是一个探索较少的话题,而分割步骤往往是诊断模型准确的前提条件。在这种情况下,数据稀缺的问题更加突出,因为关于疾病存在的地面真实信息具有更敏感的性质,而且缺乏临床登记册。标签的不平衡性和人口统计学的差异性也变得更加相关,因为不同的机构通常包含不同类型的疾病,而在分割中,预期的基础真相在所有情况下都是一样的,即分割部分的掩码。从数据科学的角度来看,分割允许更灵活的数据增强方法(甚至是基于GAN的生成),而在诊断任务中,增强应该非常谨慎,以避免转移相应标签的真实值。这通常需要人类专家验证,这取决于扩增方法,以免有增加噪音的风险。分割还具有自由使用二维切片和基于补丁的方法的优势,这允许人们从一次扫描中提取许多训练样本,而在诊断中,单一的三维体积(或有时是一系列的纵向数据)被用作单一的训练数据点。
由于这些原因,除分割以外的领域的相关研究比较有限,与诊断相关的研究早在2020年才在乳腺密度分类和肺部肿瘤生存预测中出现。随着COVID-19大流行的出现,对诊断工具的迫切需求规避了常见的障碍,使研究人员首次在联邦学习诊断中进行合作。最近,一个将FL与端到端加密功能整合在一起以防止反转攻击的开源框架被开发出来,并对儿科X射线分类进行了培训和测试。
在这项工作中,我们专注于基于心脏MRI的心血管疾病(CVD)的诊断。由于心血管疾病在人口中的流行,占每年死亡人数的三分之一,因此进一步了解心脏的结构和功能的重要性得到了强调。心脏核磁共振一直是这项工作的首选方式,可以评估和划分三个心脏部分--即心肌、左心室和右心室血池--以确定是否存在异常,如心肌梗塞或心肌病。基于这种方式,通过利用手工制作的特征,机器学习(ML)诊断工具已经被开发出来,并在单中心数据集中取得了一些成功。
为了实现CMR诊断中的人工智能研究,已经出现了心脏MRI分割和诊断的公共挑战,如 "自动心脏诊断挑战 "数据集(ACDC)和 "多中心、多供应商和多病种心脏分割挑战 "数据集(M&M)。尽管它的名字,M&M现在也包括诊断标签。我们将在研究中使用这些数据集的子集,并在 "数据集 "部分提供更多关于数据采集和注释的细节。
在心脏MRI模式方面,已经有很多关于基于深度学习的分割的文献,诊断通常是一个后续步骤,利用分割掩码,利用模型,如随机森林,支持向量机或简单的诊断规则。这些诊断模型集中在每个病人的心脏磁共振成像的两个时间点:末梢舒张期(ED)(最大的心脏放松)和收缩末期(ES)(最大的心脏收缩)。目前这类研究强调上述ACDC数据集,这是一个单一中心的数据集,承载着100个受试者和5个标签(每个受试者20个)。
Khened等人报告了多标签诊断的有希望的结果,但在10个样本的有限的保留测试集上进行了评估。在同一任务中,Cetin等人在手工分割得到的放射学特征之上使用了一个SVM,而Wolterink等人评估了一个随机森林分类器,两者都使用了交叉验证方案。Liu等人使用了一个基于深度学习的自动分割方案,并以诊断规则作为后续。尽管这些研究报告了令人印象深刻的分类性能,但这些模型都是在单中心数据集(ACDC)上训练和评估的,因此,不能假设它们对未见过的中心和更大的数据集的通用性。为了在现实世界中部署这样的模型,我们必须假设被测试的新受试者与训练和评估期间所见的受试者是同一种身份。在医学影像领域,各中心的数据是高度异质的,这种假设远非真实。此外,由于这些研究集中在一个单一的中心,没有研究隐私保护措施,而这些措施对于部署此类模型是必要的。
尽管人们对自动CMR诊断方法有着广泛的兴趣,但目前该领域还缺乏多中心和分布式的学习研究。在本文中,我们用四个中心进行研究,其中三个来自M&M数据集,第四个是ACDC的一个子集。我们测试了CDS和FL的协作学习框架。由于FL在每个中心训练本地模型,在M&M数据集的情况下,多标签分类是一个非常具有挑战性的问题,许多标签在中心之间几乎没有重叠,从而导致本地模型在不同的任务上过度适应。出于这个原因,我们只关注肥厚型心肌病(HCM)的诊断,即在正常(NOR)受试者和患有HCM的受试者之间进行二元分类。HCM是最常见的遗传性心肌病,发生率约为0.29%,即成年人口的1:344。与以往的心脏MRI诊断工作相反,我们在这里的主要目标是测试在多个中心之间进行心脏MRI诊断的可行性,并强调以一种有原则的方式评估IID和非IID性能的重要性(即在训练期间看到的中心分区和未看到的中心上测试模型)。
之前关于COVID-19和儿科X射线分类的联邦学习诊断工作主要集中在开发最先进的联邦学习框架上--后者开放了他们的管道,其中还集成了一个加密机制。在这项研究中,我们专注于多中心数据对该框架的影响,对CDS和FL范式进行了系统的比较分析,测试了各种数据策划和增强技术。通过在两个不同的交叉验证设置中进行评估并多次重复实验,我们获得了对IID和非IID性能的稳健估计,展示了两者之间的差距。我们的模型遵循众所周知的难以训练的3D-CNN架构,通过使用已经预训练过的动作识别的网络实例,利用转移学习。具体来说,我们的贡献可以概括为以下几点:
-
据我们所知,我们提出了第一个关于CMR诊断的联邦学习研究,并证明FL的性能可与CDS相媲美,同时保护了病人隐私。
-
我们提出了一种技术,通过利用地面真相掩模来诱导模型的不同先验,说明了一种有效的方法来约束解决方案的空间,并在两种协作学习设置中提高基于深度学习的多中心CMR诊断的性能。
-
我们应用一组不同的数据增量来人为地增加数据规模,并以一种原则性的方式研究它们对协作学习框架的影响,用不同的CNN权重初始化重复实验,以获得对模型鲁棒性的估计。我们还测试了FL算法在此背景下的一个变体,即给训练数据中的所有中心分配相同的投票,并表明它在某些情况下是有益的。
-
最后,通过使用两种不同的重复交叉验证设置--一种是将所有中心的一部分作为每个折叠的测试集,另一种是将整个中心作为每个折叠的测试集--我们得到了对现场和场外性能的估计,表明这两者有很大不同,并强调了它们对未来诊断研究的重要性。
-
为了促进该领域的未来研究,我们为研究界提供了我们的代码。
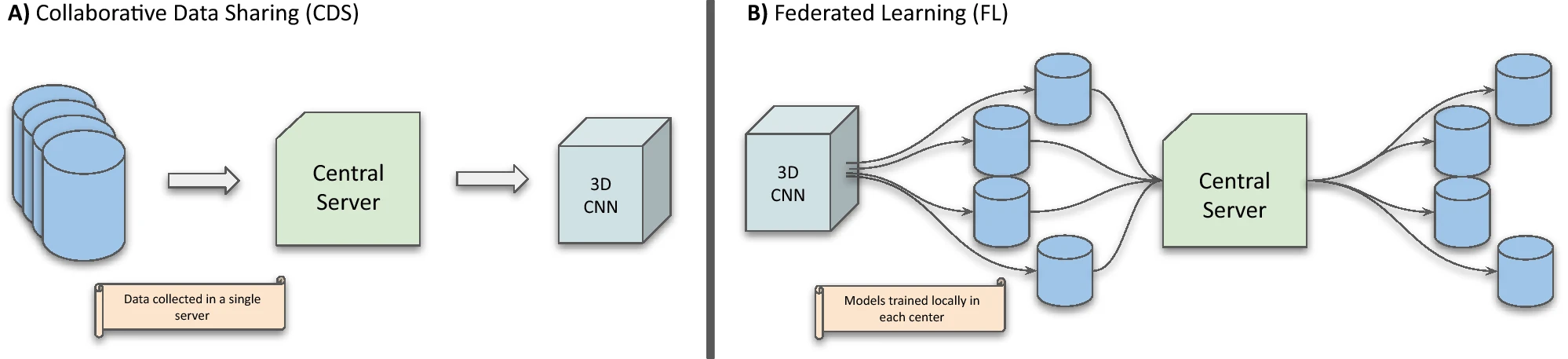
图1. 两种协作学习框架的图示。

