12 月 15 日,Nature 子刊《自然 - 机器智能》发表了由华中科技大学人工智能学院发起、剑桥大学、斯坦福大学、约翰霍普金斯大学、MD 安德森肿瘤医院、华中科技大学同济医学院附属同济医院、附属协和医院、国家药物筛选中心等国内外权威科研机构联合开发的联邦学习开源医学人工智能(AI)计算框架(Unified CT AI Diagnostic Initiative , UCADI)。
人工智能技术正在变革传统医疗。但当前人工智能模型普遍泛化性差:模型在训练过的数据集上表现优异,但是对于未曾见过的数据,表现差别大。这个根本性的缺陷导致 AI 技术在医学、医疗应用中表现出的局限性,甚至安全问题更加突出。由于医疗数据受到个人隐私,知识产权,数据尺寸等多方面的限制,无法实现大范围、集中式的数据融合,当前医学人工智能模型通常只能在有限,甚至单一的数据集上训练。因此在这样条件下构建的医疗 AI 模型应用范围十分有限。
为了解决这个根本性问题,
华中科技大学人工智能学院夏天教授与白翔教授团队提出基于联邦学习(Federated learning)开源医学人工智能计算框架(UCADI),并发表在了《自然 - 机器智能》上
。
![]()
论文地址:https://www.nature.com/articles/s42256-021-00421-z
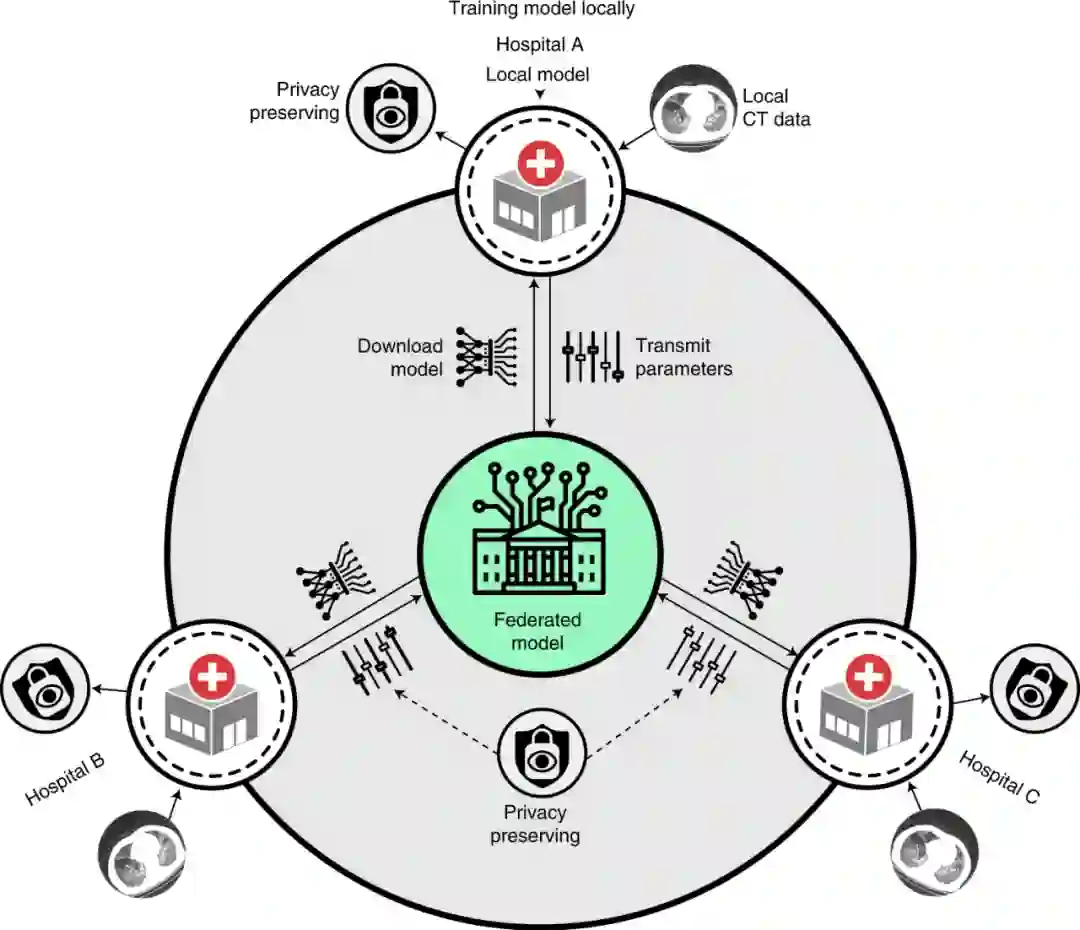
此架构在保证数据安全与隐私前提下,无需传输数据,能在不同物理地点共享训练医学数据,构建泛化性强的医学 AI 模型。
不仅如此,基于 UCADI,夏天教授与白翔教授联合华中科技大学同济医学院附属同济医院、附属协和医院、武汉天佑医院、武汉中心医院、武汉儿童医院、国家药物筛选中心与英国剑桥大学医学中心(维护全欧盟新冠影像数据,包括全英 23 家医院)发起国际大合作,实现真正全球分布式共享新冠影像数据 AI 模型训练与构建。
![]()
基于
中英 23 家医院近万张的胸部 CT 扫描数据
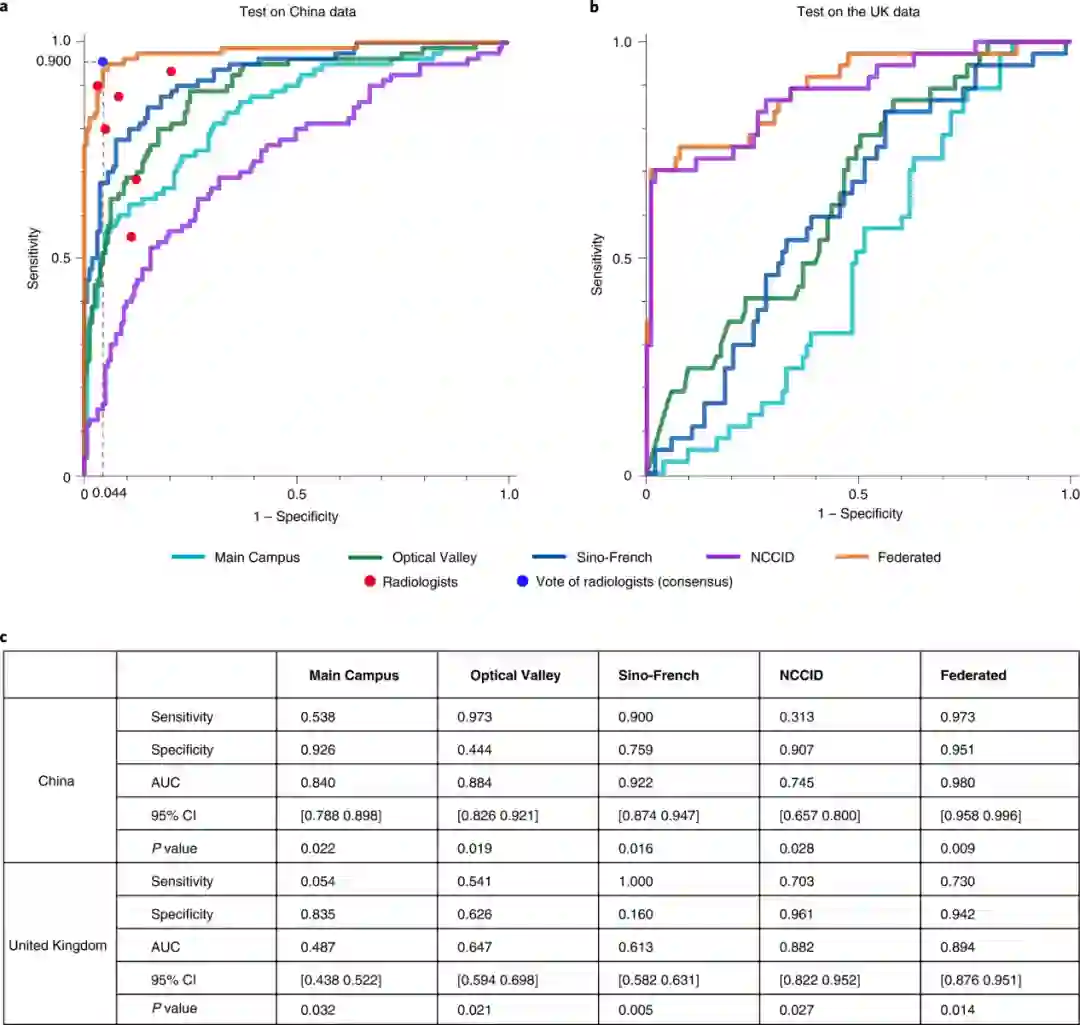
,研究团队验证了 UCADI 能够在保证用户数据隐私的情况下,多快好省地进行人工智能辅助诊断模型的训练和推理,实现跨国多中心的新冠病毒智能诊断。基于 UCADI 训练的 AI 新冠诊断模型相对于单个医院数据训练出的模型,不仅对新冠辅助诊断性能远超,同时在多个不同医院的验证数据集上表现出良好的泛化性与鲁棒性。
团队还进一步
分析了模型的可解释性和不确定性,并验证了训练的 AI 模型能够捕捉到类似磨玻璃样阴影、小叶间隔增厚等新冠病人独有的 CT 特征
。在此基础上,团队成员研究了数据异质性对模型性能的影响。
剑桥大学博士生、文章的共同一作王瀚宸发现“除了不同的医生、医院在 CT 的采集步骤上有所不同,国家与国家之间的差异更大。中英两国的 CT 数据有一个很大的区别是,中国的数据都是平扫,而英国的 CT 有很大一部分是注入造影剂后进行的增强扫描。此外,两国病人在年龄等属性上的分布也很不同,英国患者中的老年人比例非常高。这种数据上的异质性,对模型的训练是个很大的挑战。
![]()
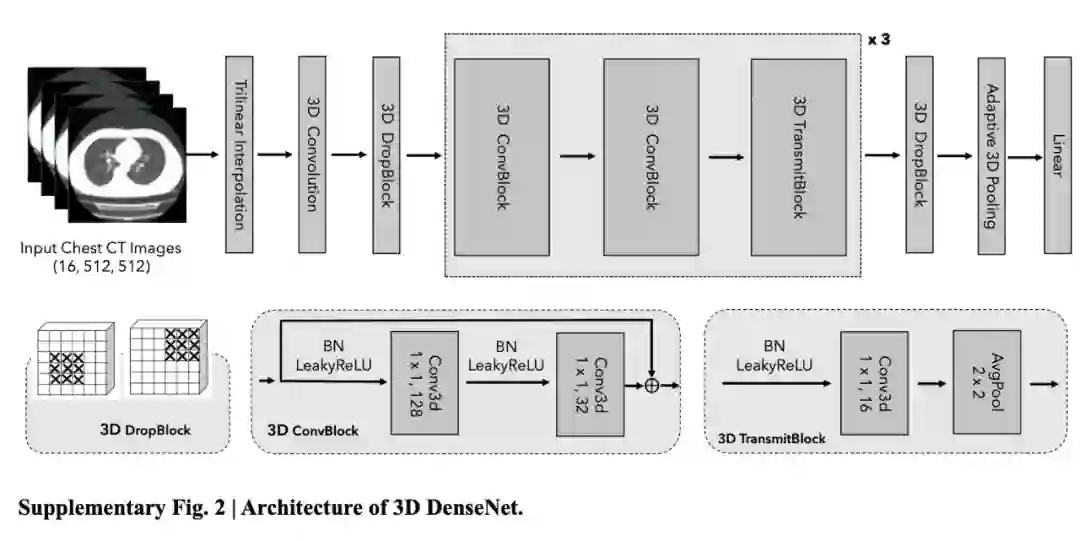
为了应对这种数据异质性,团队首先进行了很多模型上的筛选和尝试,在几种常见的 3D 卷积网络架构中,最后选择 3D DenseNet
。不仅是因为其较好的泛化性能,同时模型尺寸偏小,非常方便联邦学习中进行传输。但值得注意的是,3D DenseNet 也需要更多的计算资源。在此基础上,团队还尝试用 CycleGAN 在增强和平扫的 CT 间进行转换,取得了一些性能上的改善,但还是有相当的可提升空间。
![]()
此工作中,UCADI 框架初步展示了对于全球新冠数据的整合能力,基于全球范围数据构建的新冠诊断预测模型完全向全球开放使用,各国医疗机构可以在此基础上,利用 UCADI 进一步共享、更新、演进、优化预测模型。同时,UCADI 框架完全开源,可用于其他类型医疗数据,为未来的跨国智能诊断系统的研究与发展提供了基础设施。
团队已与剑桥大学和世界卫生组织 10 月份在德国新设立的疫情智能防控中心 (WHO Hub for Pandemic and Epidemic Intelligence) 建立进一步合作,重点研究现有的 AI 诊疗模型对识别新变种 Omicron 的鲁棒性,以及探索用持续学习 (Continual Learning) 等方法来开发一个可不断进化的联邦学习诊疗框架。
使用 NVIDIA Riva 快速构建企业级 ASR 语音识别助手
NVIDIA Riva 是一个使用 GPU 加速,能用于快速部署高性能会话式 AI 服务的 SDK,可用于快速开发语音 AI 的应用程序。Riva 的设计旨在帮助开发者轻松、快速地访问会话 AI 功能,开箱即用,通过一些简单的命令和 API 操作就可以快速构建高级别的语音识别服务。该服务可以处理数百至数千音频流作为输入,并以最小延迟返回文本。
12月29日19:30-21:00,本次线上分享主要介绍:
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com