

本文简要介绍CVPR 2024录用论文“Enhancing Visual Document Understanding with Contrastive Learning in Large Visual-Language Models”的主要工作。该论文提出一个对比学习方法DoCo,旨在提高大型视觉-语言模型的文档图像理解能力;DoCo利用一个多模态编码器来获取文档对象的多模态特征,并将其与由视觉编码器生成的视觉特征对齐。在文档图像理解的基准测试上的实验结果表明,所提出的方法可以实现优越的性能。
一、研究背景****
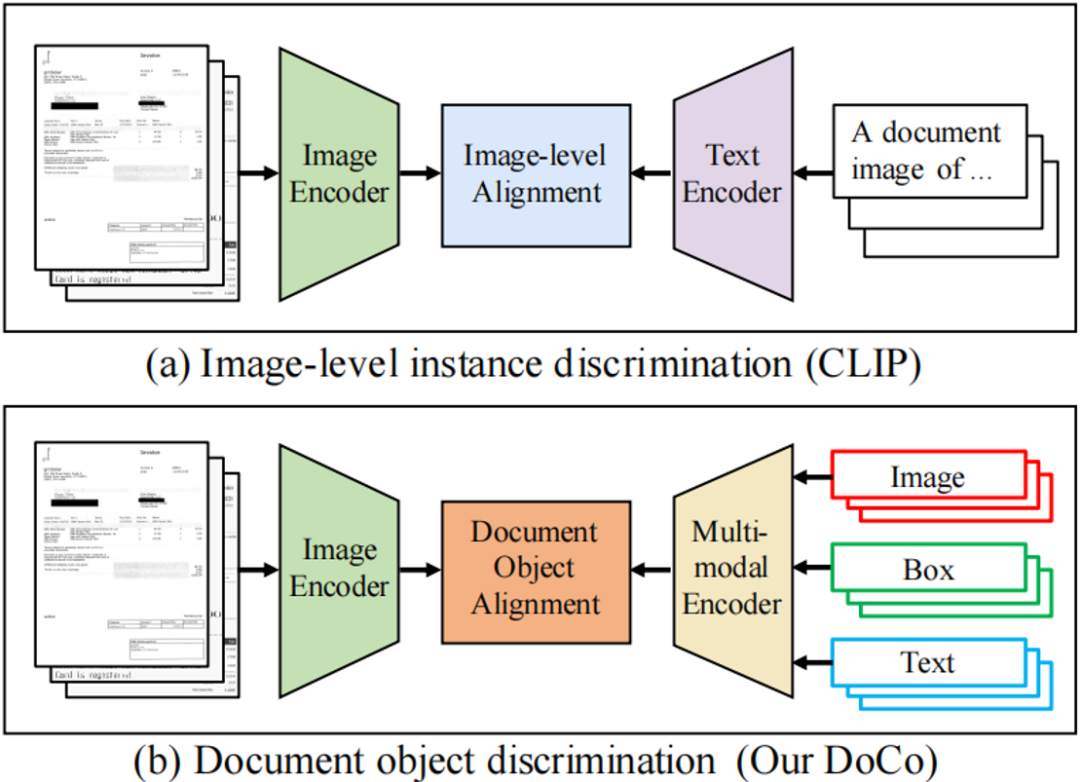
现有的通用多模态大型模型在多模态理解方面有很强的能力,但由于缺乏针对性的训练,它们在文本丰富的场景中表现仍然有限,如“文档图像理解”(以下简称VDU)任务。为了解决这个问题,一些“大型视觉-语言模型”(以下简称LVLMs)尝试提高在VDU任务上的性能,它们利用大规模的文档数据来训练或通过多模态理解同时处理多种VDU任务,代表性工作如mPLUG-DocOwl [1]、LLaVAR [2]、UniDoc [3]等。如图1(a)所示,这些模型的视觉编码器是基于CLIP[4]预训练的权重,CLIP通过对比学习将图像级的视觉和文本之间进行跨模态对齐。然而,这些图像级的表征对于如VDU等密集预测任务来讲并不是最优的,并且这样的图像编码器不能提取细粒度的视觉特征。这一问题引发了作者的思考:如何通过对细粒度特征的探索提高LVLMs在文本丰富场景中的性能?为解决这个问题,作者提出了一个新的对比学习方法Document Object COntrastive Learning (DoCo),如图1(b)所示,旨在将文档对象级的多模态特征和视觉特征对齐。
二、方法原理简述****
DoCo的整体框架如图2所示。DoCo主要由两个分支组成,即位于图2(a)顶部的视觉编码器和图2(a)底部的多模态编码器。在预训练阶段,一个输入图像经视觉编码器,获得图像Embedings。同时用OCR引擎获取文本的边界框和内容,并输入到多模态编码器,以提取文档文本的融合特征。然后,这两个编码器输出的特征由ROI聚合模块在文档对象级别进行对齐。通过这种对比学习的范式,DoCo增强了来自图像编码器的视觉表征。 如图2(b)所示,在微调阶段,多模态编码分支被移除,而增强后的图像特征与额外的文本输入(如问题)的Embedings一起输入视觉-语言Adapter,随后输入LLM。
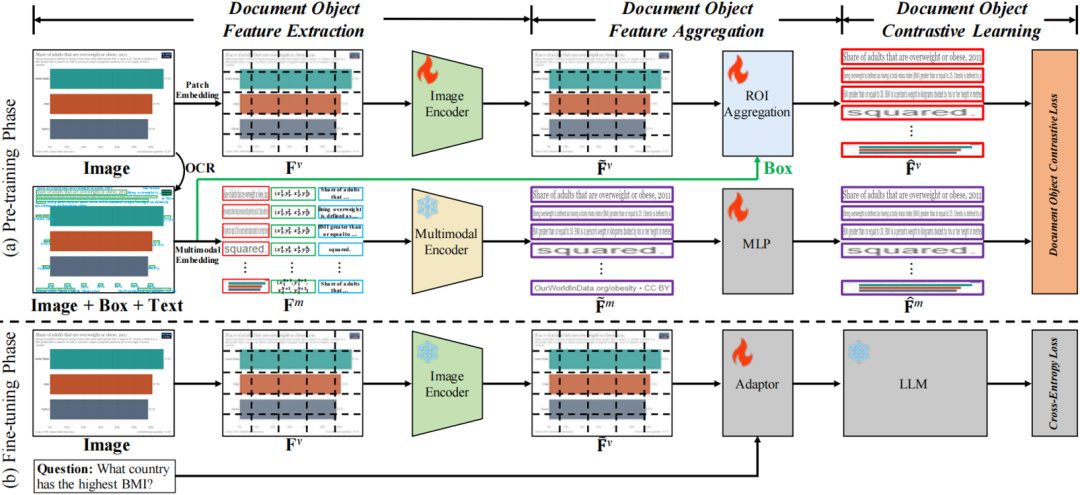
视觉特征提取:在整个训练和推理过程,输入的图像x通过Patch Embeding的过程转换为一个图像Embedings序列。随后使用CLIP[4]预训练过的ViT来提取图像Embedings的视觉特征。 多模态特征提取:该过程旨在通过多模态编码器提取每个文本框的特征。作者使用LayoutLMv3 [5]来提取特征,包括视觉Embedings、布局Embedings和文本Embedings,分别如图2中的红、绿和蓝框所示。一张图像会提取N+1个多模态Embedings,其中N表示OCR引擎识别出的文本框数量,额外的1代表用与图像相同分辨率的框提取到的全局特征。 ROI聚合模块:ROI聚合模块的具体结构如图3所示。将图像编码器的输出记为Fv。对于第i个框对象,对应的边界框被定义为bi ={xi1、yi1、xi2、yi2}。首先,作者计算bi和每个Patch,bp之间的重叠区域,并将其归一化为Mi:
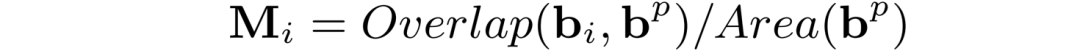
其中,Overlap和Area分别表示计算两个区域之间的重叠面积和区域的面积。Mi代表了视觉特征对第i个文档对象的注意力偏向。随后,作者在Patch Embedings序列Fv上加一个
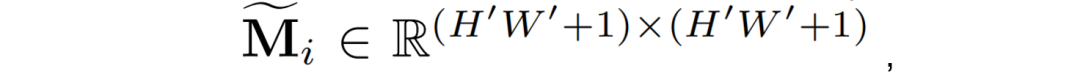
重组后的图像Embedings序列转为为Q、K、V,计算自注意力:
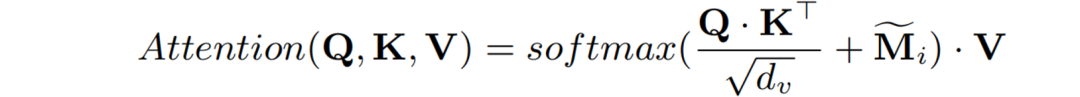
再用两组MLP模块将多模态表征转换到一个统一的维度空间
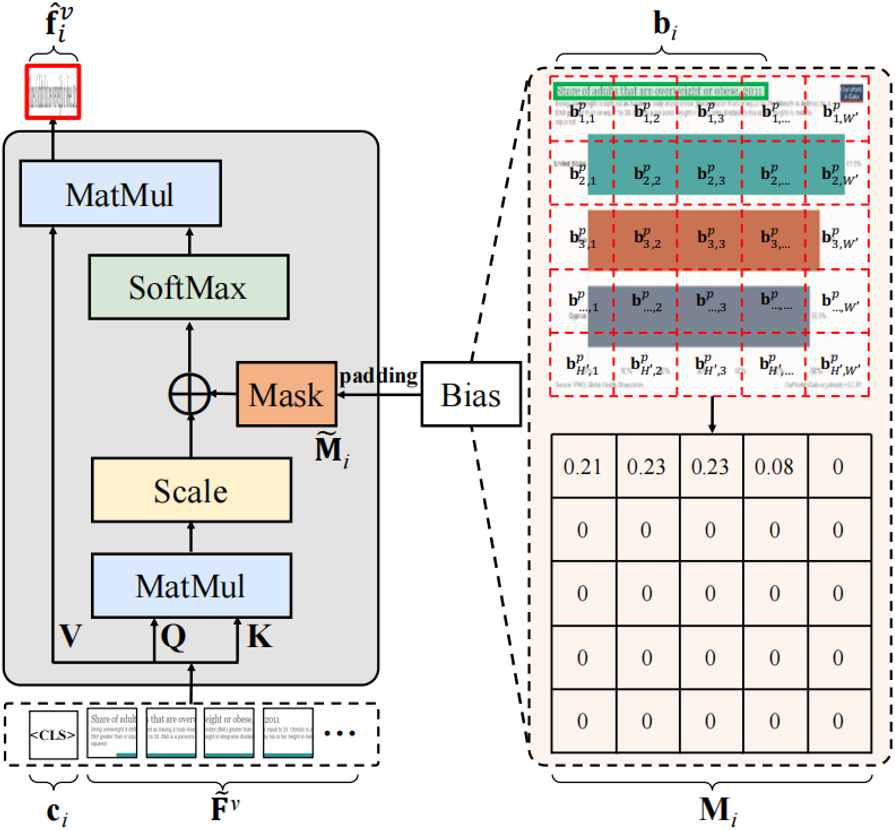
图3 ROI聚合模块的具体结构 训练Loss:DoCo的训练包含 Intra-DoCo和Inter-DoCo,它们分别表示在单个图像内和两个不同图像之间的文档对象表征学习。 (1).对于Intra-DoCo,如图4(a)所示,Loss为最小化正样本相似性对并使负样本对的相似性最大化:
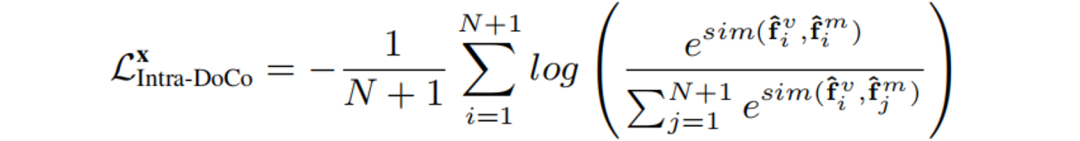
以对称的方式,计算从j到i的损失为:

因此Intra-DoCo部分的Loss为以上二者的平均:
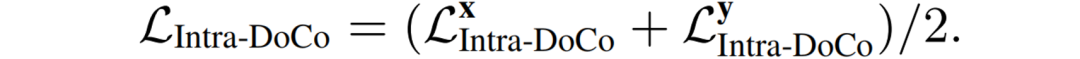
(2).对于Inter-DoCo,如图4(b)所示,作者对单个图像的视觉特征和多模态特征分别进行了平均,获得了文档对象全局的图像、多模态特征;同样最小化正样本相似性对并使负样本对的相似性最大化:
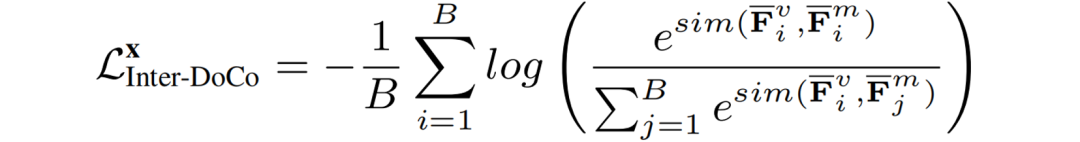
同Intra-DoCo一样,计算从j到i的损失,并把两者平均,得到Inter-DoCo部分的Loss: (3).总的Loss为Intra-DoCo和Inter-DoCo两部分Loss的叠加:
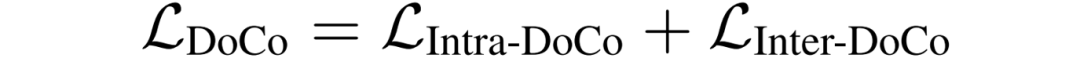
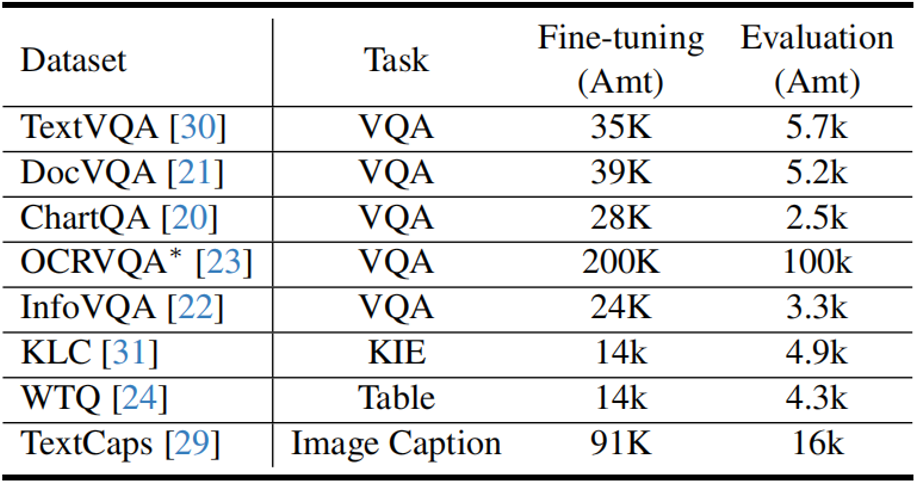
图4 Intra-DoCo和Inter-DoCo 训练策略: (1)预训练阶段:冻结多模态编码器,只训练图像编码器。使用约100万对图像文本对进行训练。包括来自CC3M数据集[6]的60万数据子集,以及来自LAION数据集[7]的另外40万数据子集。同时这些数据集都使用OCR引擎PaddleOCR [8]获取OCR结果。 (2)微调阶段:冻结图像编码器和LLM,只更新Adapter的参数。使用的微调和评估数据如表1所示。表1 微调阶段使用的数据
三、主要实验结果****
如表2所示,作者对比了不同LVLMs在各种文档图像理解基准上的结果,发现DoCo增强了在文本丰富场景下LVLM图像编码器的视觉表征,从而增强了VDU任务的性能。表3展示的在DocVQA上的消融实验,体现了作者提出的DoCo方法中各部分的作用。 表2 不同LVLMs在各种文档图像理解基准上的结果。带有“†”表示使用CLIP进行预训练,而带有“††”表示使用DoCo
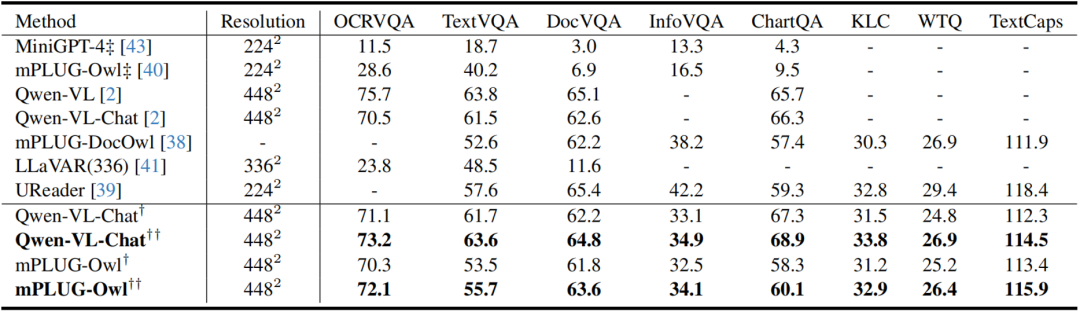
表3 在DocVQA数据集上的消融实验,“R”和“A”分别代表“ROI聚合”和“平均聚合”。“I”、“B”和“T”分别表示文档对象的“图像”、“文本框”和“文本”
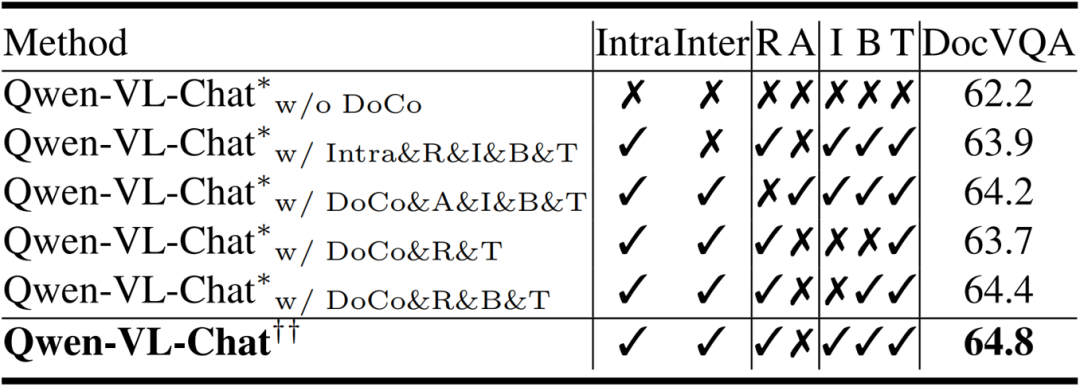
图5展示了Qwen-VL-Chat [9]在CLIP [4]预训练的版本和DoCo预训练的版本的定性结果。DoCo预训练的版本不仅能够熟练地从文档中提取相关数据,而且能够通过集中于特定的区域来提供相应的响应。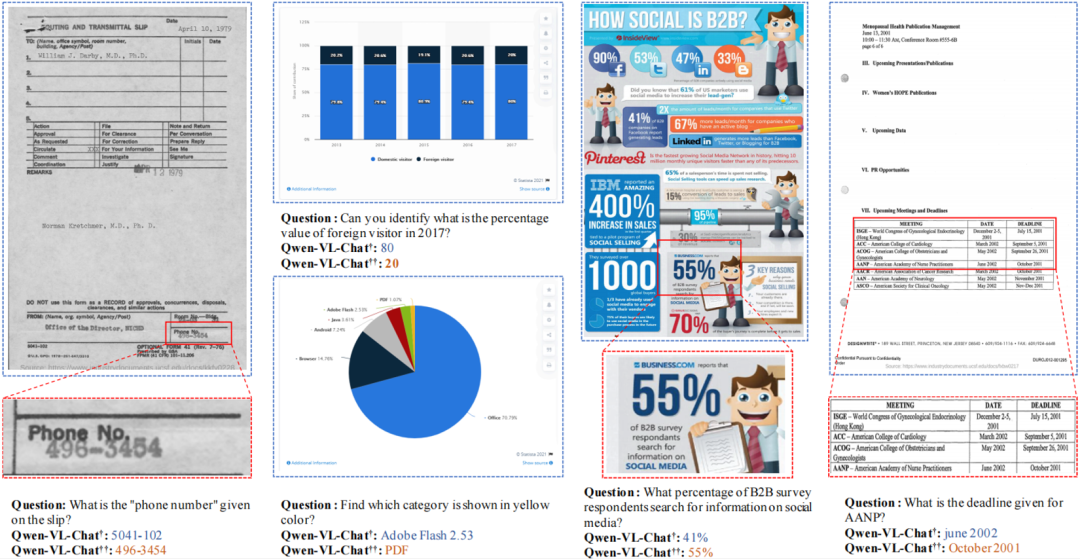
该论文提出了一种新的对比学习框架DoCo,用在于文本丰富场景中提取LVLMs的细粒度特征。不同于以往的图像级对比学习方法对比整个图像级别的视觉和文本输入,DoCo区分文档对象之间的图像和多模态特征,使LVLMs的图像编码器学习对于在文本丰富的场景更有效的视觉表征。实验结果表明,配备DoCo的LVLM可以取得优越的性能,减轻了视觉文档理解与传统视觉语言任务之间的差距。 五、相关资源****
论文地址: https://arxiv.org/pdf/2402.19014.pdf 参考文献****
[1] Jiabo Ye, Anwen Hu, Haiyang Xu, Qinghao Ye, Ming Yan, Yuhao Dan, Chenlin Zhao, Guohai Xu, Chenliang Li, Junfeng Tian, et al. mplug-docowl: Modularized multimodal large language model for document understanding. arXiv preprint arXiv:2307.02499, 2023. [2] Yanzhe Zhang, Ruiyi Zhang, Jiuxiang Gu, Yufan Zhou, Nedim Lipka, Diyi Yang, and Tong Sun. Llavar: Enhanced visual instruction tuning for text-rich image understanding. rXiv preprint arXiv:2306.17107, 2023. [3] Hao Feng, Zijian Wang, Jingqun Tang, Jinghui Lu, Wengang Zhou, Houqiang Li, and Can Huang. Unidoc: A universal large multimodal model for simultaneous text detection, recognition, spotting and understanding. arXiv preprint arXiv:2308.11592, 2023. [4] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021. [5] Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311, 2022. [6] Piyush Sharma, Nan Ding, Sebastian Goodman, and Radu Soricut. Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2556–2565, 2018. [7] Christoph Schuhmann, Romain Beaumont, Richard Vencu Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, et al. Laion-5b: An open large-scale dataset for training next generation image-text models. Advances in Neural Information Processing Systems, 35:25278–25294, 2022. [8] Yuning Du, Chenxia Li, Ruoyu Guo, Xiaoting Yin, Weiwei Liu, Jun Zhou, Yifan Bai, Zilin Yu, Yehua Yang, Qingqing Dang, et al. Pp-ocr: A practical ultra lightweight ocr system. arXiv preprint arXiv:2009.09941, 2020.[9] Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A frontier large vision-language model with versatile abilities. arXiv preprint arXiv:2308.12966, 2023.
原文作者:Xin Li, Yunfei Wu, Xinghua Jiang, Zhihao Guo, Mingming Gong, Haoyu Cao, Yinsong Liu, Deqiang Jiang, Xing Sun
