NLPCC 2020《预训练语言模型回顾》讲义下载,156页PPT
声明:本文转载自 哈工大讯飞联合实验室 公众号
哈工大讯飞联合实验室(HFL)资深级研究员、研究主管崔一鸣受邀在NLPCC 2020会议做题为《Revisiting Pre-trained Models for Natural Language Processing》的讲习班报告(Tutorial),介绍了预训练语言模型的发展历程以及近期的研究热点。本期推送文末提供了报告的下载方式。
NLPCC 2020 Tutorials:
http://tcci.ccf.org.cn/conference/2020/tutorials.php
报告信息
Title: Revisiting Pre-Trained Models for Natural Language Processing
Abstract : 预训练语言模型(PLM)已经成为最近自然语言处理研究的基本元素。在本教程中,我们将回顾文本表示的技术进展,即从一个热点嵌入到最近的PLMs。我们将介绍几种流行的PLMs(如BERT、XLNet、RoBERTa、ALBERT、ELECTRA等)及其技术细节和应用。另一方面,我们也将介绍中国plm的各种努力。在演讲的最后,我们将分析目前PLMs的不足之处,并展望未来的研究方向。
报告目录
Introduction
Traditional Approaches for Text Representation
one-hot, word2vec, GloVe
Contextualized Language Models
CoVe, ELMo
Deep Contextualized Language Models
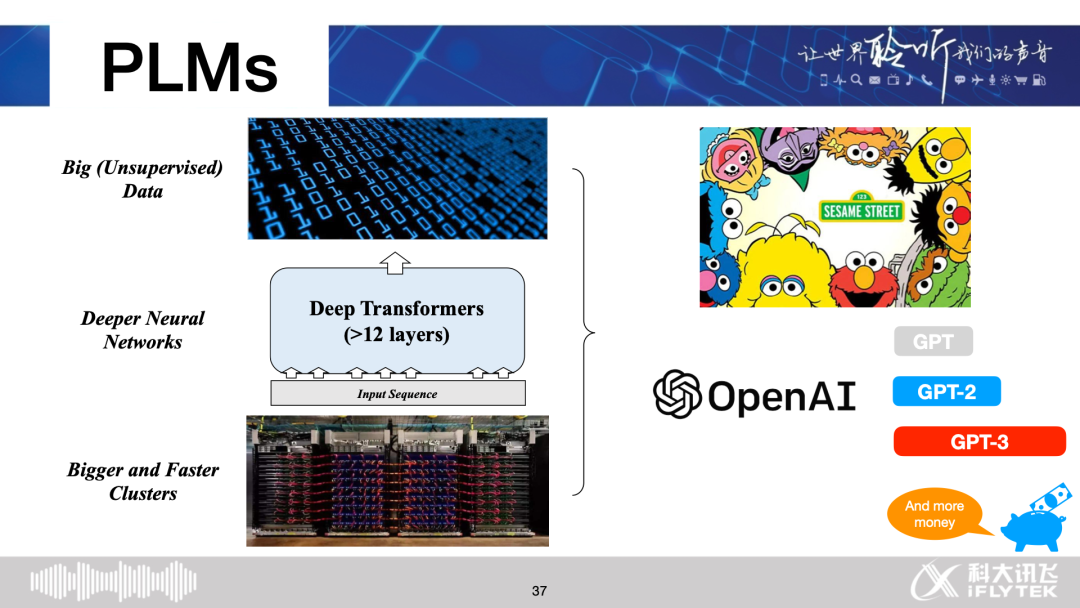
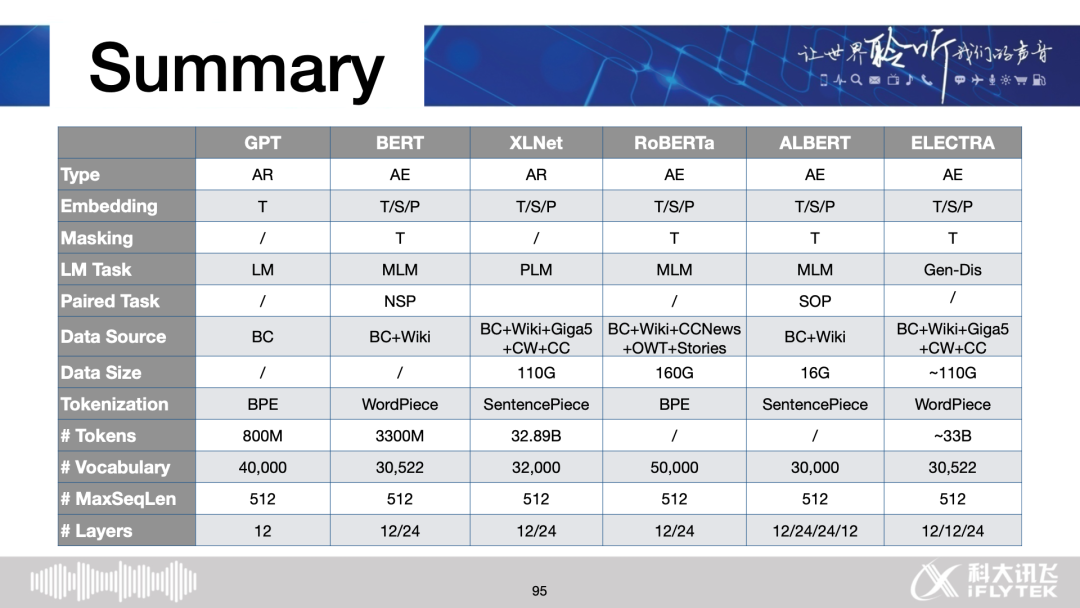
GPT, BERT, XLNet, RoBERTa, ALBERT, ELECTRA
Chinese Pre-trained Language Models
Chinese BERT-wwm, ERNIE, NEZHA, ZEN, MacBERT
Recent Research on PLM
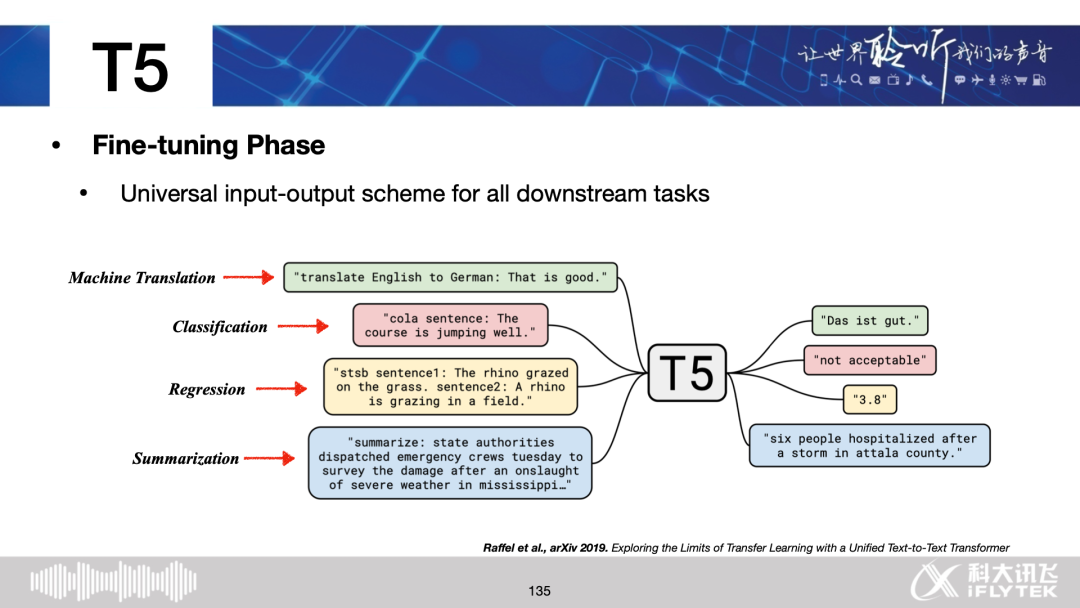
Trending: GPT-2, GPT-3, T5
Distillation: DistilBERT, TinyBERT, MobileBERT, TextBrewer
Multi-lingual: mBERT, XLM, XLM-R
Summary
讲义部分内容截图







专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“PTM156” 可以获取《NLPCC 2020《预训练语言模型回顾》讲义下载,156页PPT》专知下载链接索引







