

**连续学习,也称为增量学习或终身学习,**位于深度学习和AI系统的前沿。它突破了只在封闭集上的单向训练的障碍,并在开放集条件下实现了连续的自适应学习。在过去的十年中,连续学习已被探索并应用于多个领域,特别是在计算机视觉中,涵盖分类、检测和分割任务。连续语义分割(CSS)的密集预测特性使其成为一个具有挑战性、复杂性和蓬勃发展的任务。在本文中,我们对CSS进行了评述,致力于建立一个关于问题定义、主要挑战、通用数据集、新颖理论和多种应用的综合调查。具体来说,我们首先阐明了问题的定义和主要挑战。基于对相关方法的深入调查,我们将当前的CSS模型分为两个主要分支,包括数据重放和无数据集。在每个分支中,相应的方法都基于相似性进行了分类和深入分析,然后对相关数据集进行了定性比较和定量复现。此外,我们还介绍了四个CSS特点以及不同的应用场景和发展趋势。此外,我们为CSS开发了一个基准,包括代表性的参考文献、评估结果和复现,可以在https://github.com/YBIO/SurveyCSS 上找到。我们希望这次调查能为终身学习领域的发展提供有参考价值和刺激性的贡献,同时也为相关领域提供有价值的观点。
连续学习(CL),也称为增量学习[1]、[2]或终身学习[3]、[4],是一种侧重于顺序性获取知识的方法。CL起源于认知神经科学对记忆和遗忘机制的研究[5]、[6]、[7]、[8],并在过去的十年中经历了繁荣的发展。作为深度学习中的尖端热点,CL技术通过突破一次性学习的限制,大大提高了基于神经网络模型的泛化能力。相比之下,传统的机器学习方式通常建立在一个封闭集上,即它只能处理固定数量的预定义类,并且所有数据都需要在单步训练中呈现给模型。然而,在实际应用场景中,模型经常面临不断增长的数据的挑战。因此,如何使模型能够持续适应新数据或任务构成了一个普遍的挑战。CL的主要目标是在有限的计算和存储资源的限制下,在稳定性和可塑性的困境[9]中找到一个最佳的平衡,其中稳定性是指保持以前知识的能力,而可塑性是指整合新知识的能力。
自然地,典型的模型更新涉及到在新数据上进行重新训练[10]或应用迁移学习技术[11],这引发了灾难性遗忘的问题。这个问题早在1980年代就被McCloskey等人[12]发现并讨论。也就是说,使用反向传播训练的算法会遭受严重的知识遗忘,就像人类遭受以前学到的任务的逐渐遗忘一样。此外,简单地从头开始重新训练模型可能会导致类似阿尔茨海默症的问题,其中模型由于参数更新而失去了过去的能力[11]。作为一个密集预测任务,连续语义分割(CSS)作为一个与各种实际视觉计算领域相关的有前景但具有挑战性的任务崭露头角,例如开放世界视觉解释[13]、[14]、精密医疗辅助[15]、[16]、[17]、遥感观测[18]、[19]、[20]以及自动驾驶[21]、[22]等。
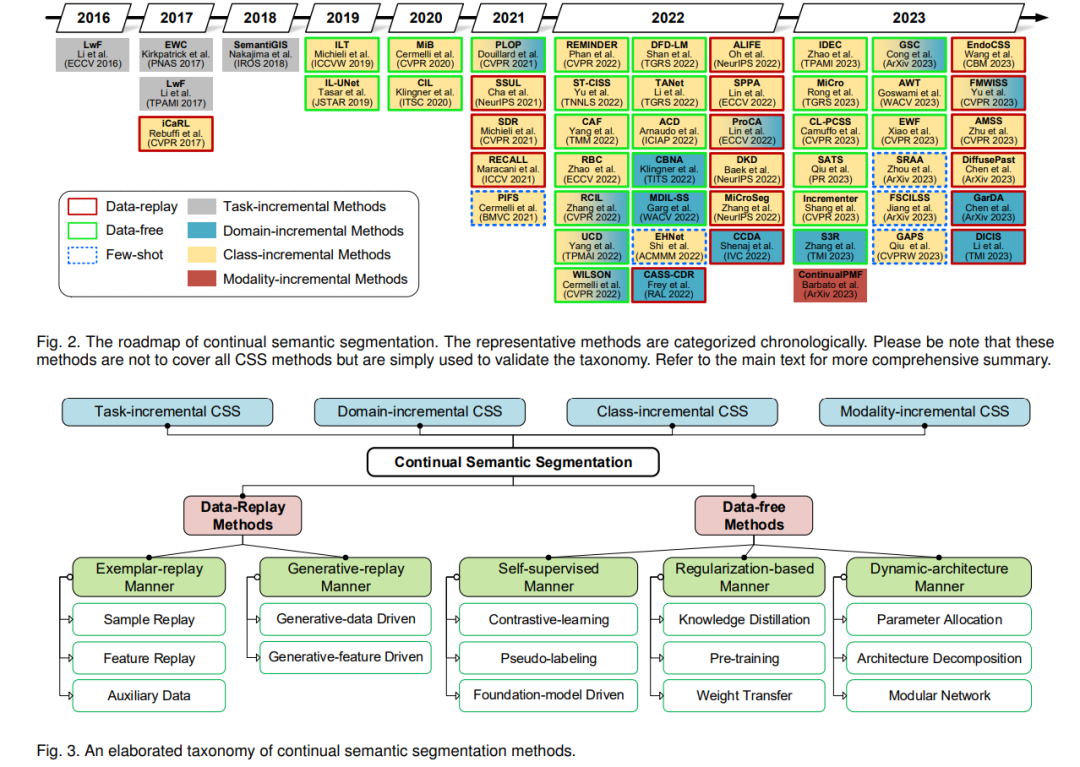
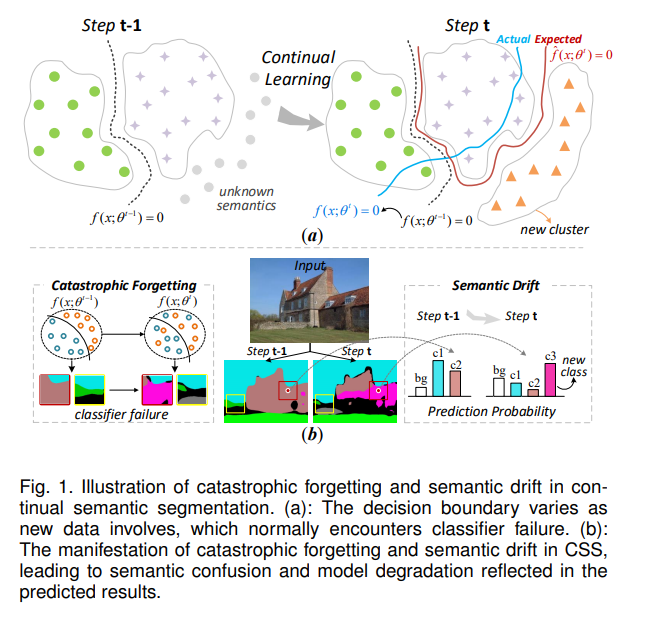
除了灾难性遗忘,CSS中的另一个关键挑战是语义漂移。这种现象指的是随着逐步学习新的类别,背景的语义内容的逐渐变化或演变。从根本上说,它源于真实背景、旧类和未来类的混合语义。如图1(a)所示,由于缺乏历史数据,模型在CL步骤中往往会遇到类别混淆和分类器偏见。此外,由于每个增量步骤只有当前的类别被标记,背景像素的语义发生漂移,因为它们的内涵变化,即已知的类别和未来的类别被混合为单一的背景类。因此,这导致了随后的分类混乱,并最终导致分类器失败。如图1(b)所示,CSS的主要挑战包括灾难性遗忘和语义漂移。它们源于旧数据的缺失和参数更新[23]、[24]、[25],导致语义混淆和模型退化。尽管CSS的一个显著前提是不能访问来自旧任务的数据,但一些研究允许将部分旧数据存储在缓存中,以增强学习新任务时的CSS效率。此外,实用的无数据和混合的少镜头CSS方法目前也在进行深入的探索。在图2中,我们展示了一系列代表性的CSS方法,展示了不同时间段的研究焦点的演变。很明显,CSS起源并在最近的十年中蓬勃发展,特别是在过去的三年中。基于历史数据的利用,CSS方法可以广泛地分类为两组。如图3所示,第一类,称为数据重放方法,涉及将部分过去的训练数据存储为示例记忆,例如[26]、[27]、[28]、[29]、[30]、[31]、[32]、[33]、[34]、[35]、[36]。第二类,称为无数据方法,包括像[37]、[38]、[39]、[40]、[41]、[42]、[43]、[44]、[45]、[46]、[47]、[48]、[49]这样的方法。这些方法利用迁移学习技巧,如知识蒸馏,来继承旧模型的能力。此外,还有许多方法的子类,它们在表1中总结,在第4节中详细说明。关于应用场景,CSS方法还可以分为四种任务,这些任务在第2.2节中详细讨论。
在这里,我们希望基于指定模型在大型模型兴起期间讨论持续学习的优势和必要性。尽管最近的大型模型形式[59]、[60]达到了相当的零镜头学习能力,但它们往往缺乏像人类那样具有语义理解的目标分类能力。另一个重要的担忧是成本。例如,大型语言模型(LLMs),如ChatGPT,通常需要数百万美元进行一次性训练。有时由于隐私限制和存储负担,历史数据变得无法访问。此外,在某些特定领域,如全景遥感和医疗援助,仍然需要专用模型,因为这些领域需要高精度。因此,我们主张将大型模型的通用性和专用模型的定制性集成是未来的趋势。考虑到CL的日益成熟,我们相信这最新和全面的调查可以为未来的工作提供一个全面的视角。尽管已经有一些关于持续学习的早期调查[61]、[62]、[63]、[64]、[65],涵盖范围相对较广,但在专门针对基本的密集预测任务的评论中仍然存在明显的差距。本次调查代表了一个致力于探索持续语义分割的最新进展的努力。
本文的贡献概述如下: • 本文回顾了持续语义分割(CSS)的概念、挑战、方法和应用,这是一个关于计算机视觉领域中这一基本但蓬勃发展的任务的专门的综合调查。 • 本文基于各种技术路线、持续学习策略和任务规范对CSS方法进行分类和总结,作为CSS方法的详细分类和全面回顾。 • 我们对CSS方法进行统一的定性和定量调查,提供了优势、劣势和适用场景的详细讨论。 • 我们提出了对CSS实际应用的深入研究分析,并总结了几个有前途的探索方向。本文的其余部分组织如下。
第2节详述了基本的CSS设置,包括问题定义、基本公式和适用任务。在第3节,我们总结了CSS的数据集和流行的协议。在第4节,我们按类别介绍了最新的CSS方法。此后,在第5节中,我们提供了定性和定量分析以及详细的讨论。最后,在第6节中,我们讨论了当前有前途的应用,并总结了CSS的未来前景。
