

随着数据的爆炸性增长和计算资源的发展,构建能够在各种任务中取得卓越表现的预训练模型变得可能,如神经语言处理、计算机视觉等。尽管预训练模型具有强大的能力,但它们也引发了对其实际应用中出现的安全挑战的关注。安全和隐私问题,如泄露隐私信息和生成有害回应,严重削弱了用户对这些强大模型的信任。随着模型性能的显著提升,相关担忧也在加剧。研究人员迫切希望探索这些新兴的安全与隐私问题、它们的特征及如何防御这些问题。然而,现有文献缺乏关于预训练模型新兴攻击与防御的清晰分类,这阻碍了对这些问题的高层次和全面理解。为填补这一空白,我们对预训练模型的安全风险进行了系统性综述,提出了一种基于预训练模型输入和权重在各种安全测试场景中的可访问性来分类攻击和防御方法的分类法。该分类法将攻击和防御方法分为无变化(No-Change)、输入变化(Input-Change)和模型变化(Model-Change)三种方法。通过这一分类分析,我们捕捉了预训练模型的独特安全和隐私问题,并根据其特征对现有的安全问题进行了分类和总结。此外,我们对每个类别的优缺点进行了及时且全面的回顾。最后,我们的综述总结了预训练模型在安全和隐私方面的潜在新研究机会。
1 引言
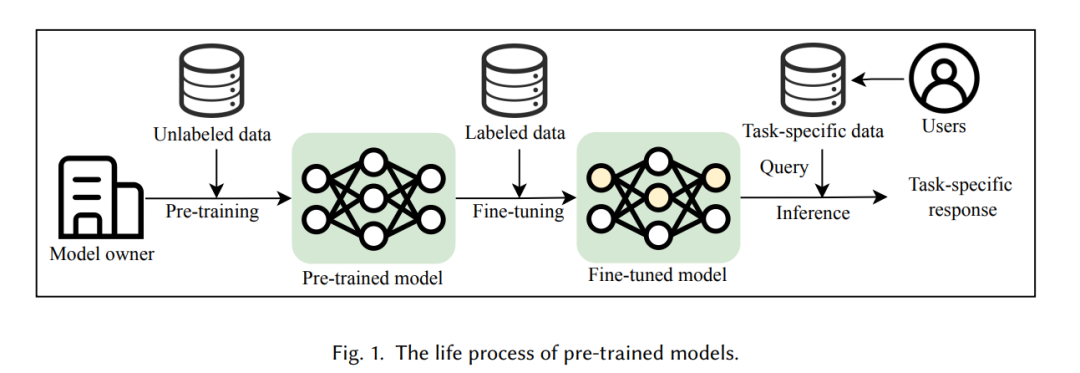
近年来,大型人工智能(AI)模型如大型语言模型和大型视觉模型的快速发展催生了预训练模型的概念。如今,预训练模型被视为具有复杂架构和大量参数的大规模编码器,最初通过使用广泛数据集和先进目标进行训练。由于数据的爆炸性增长和计算技术的进步,研究人员现在能够扩展训练数据和模型架构,创建像GPT [86, 88] 和BERT [29] 这样的预训练模型,它们将基础知识存储在庞大的参数中。通过对这些模型进行微调以适应特定任务,它们所编码的丰富知识可以提升各类下游应用。因此,使用预训练模型已成为开发和改进任务特定模型的常见做法。 然而,在享受预训练模型带来的便利的同时,人们对潜在的安全风险越来越担忧。例如,成员推断攻击(membership inference attacks)[61][12] 可以揭示训练数据集中某些内容的信息,而越狱攻击(jailbreak attacks)[28][90][54] 则能误导模型生成有害的回应。然而,除了传统模型中已经广泛研究的各种安全问题外,预训练模型强大的能力也带来了传统模型中不存在的新安全问题。因此,填补这些空白并为预训练模型的保护建立更高标准显得尤为重要。 已有一些研究总结了大型模型中的安全与隐私问题,但很少有研究深入全面地探讨大型模型中新兴安全问题的根本原因。我们发现,这些新安全问题是由不同的训练策略和大规模数据集引入的。由于这些原因,预训练模型——能够应用于不同任务——与传统专注于单一任务的模型之间存在巨大差距。例如,当前研究领域流行的“预训练/微调/推理”(pre-train/fine-tune/inference)策略相比传统的“训练/推理”(train/inference)策略,出现了新的攻击方式,专门攻击预训练模型在微调过程中的安全性。这些攻击方法可能与传统攻击方法相似,但在细节上有所更新,比如攻击预训练模型特有的训练策略,如带有人工反馈的强化学习(Reinforcement Learning with Human Feedback, RLHF)[81]。 预训练模型之间仍然存在差异。最显著的是,较大的模型往往表现出更强的功能性。这引出了一个问题:随着模型规模的增大,会出现什么独特的安全和隐私问题,为什么这些问题会发生?回答这个问题是一个长期的挑战。尽管全面解释大型模型为何具有强大能力仍然困难,但初步的思路可以从较小的预训练模型的安全与隐私问题入手,探索这些问题如何扩展到更大的模型。这将有助于识别常见的和不同的安全与隐私问题,以及不同模型规模下攻击和防御策略的异同。 在这个领域中,存在着多种概念和多种攻击/防御方法,且预训练模型和传统模型之间的边界往往模糊不清。正是这些挑战促使我们开展了一项全面的综述,旨在总结、分析并分类预训练模型的安全问题及其相应的防御对策。我们的分析指出了这一领域中各种攻击和防御方法的独特特点及其差异。此外,我们提出了一种新的分类法,用于分类文献中的最新方法。我们的贡献可总结为以下几点:
- 我们提出了一种新的攻击/防御技术分类法,基于攻击/防御的阶段和具体策略对预训练模型进行分类。
- 我们基于提出的分类法,全面总结了当前最先进的攻击/防御技术,展示了它们的优缺点。
- 我们回顾了针对不同规模预训练模型的攻击与防御方法,总结了它们的共性与差异。
- 我们对预训练模型中开放的安全和隐私问题进行了深刻讨论,并指出了未来可能的研究方向。
我们希望这项工作能够帮助全面回顾和评估预训练模型的安全与隐私风险。建立标准化的评估系统将有助于更准确地进行风险评估,最终提高用户对预训练模型的信任。
