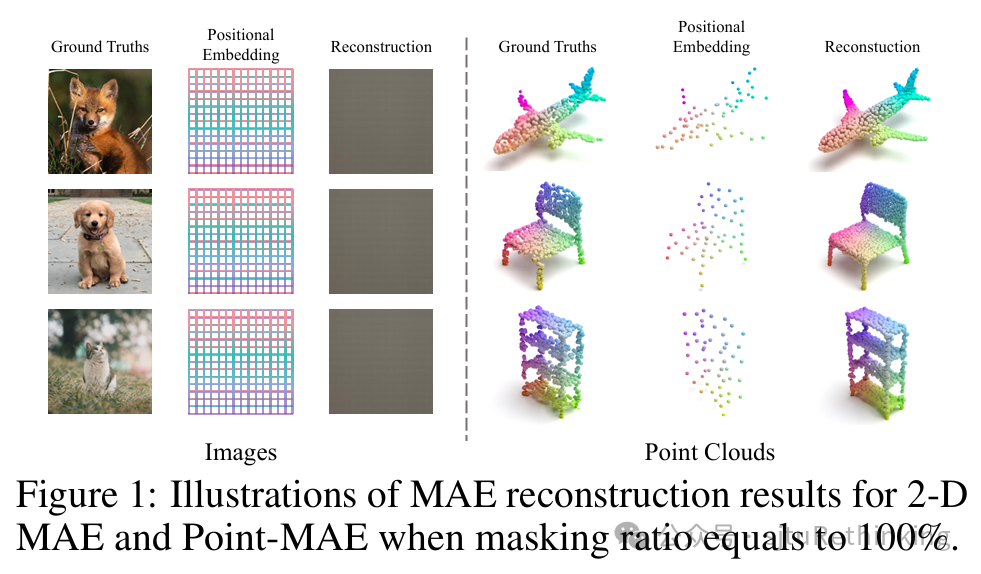
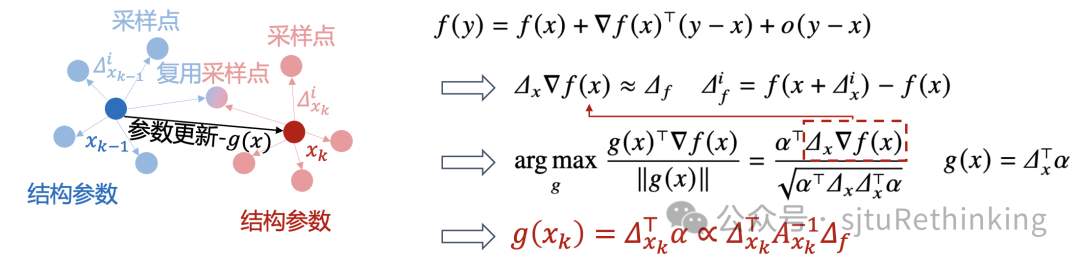上海交通大学ReThinklab近期在国际机器学习顶会NeurIPS2024上录用16篇论文,涉及量子计算、自动驾驶、大模型、自监督学习、EDA/CAD、运筹优化等领域。
NeurIPS (the Thirty-Eighth Annual Conference on Neural Information Processing Systems)是人工智能领域的顶级会议之一,具有广泛而深远的国际影响力,受到来自学术界和工业界的广泛关注,也是中国计算机学会(China Computer Federation, CCF)推荐的A类会议。
Main Track
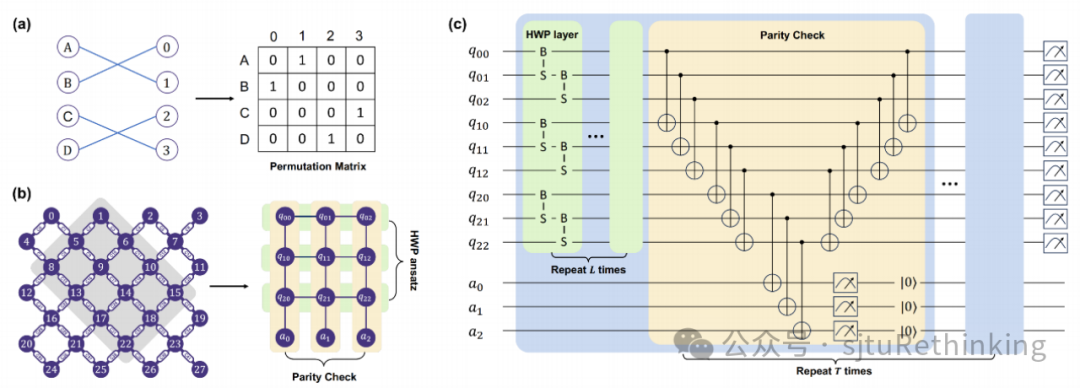
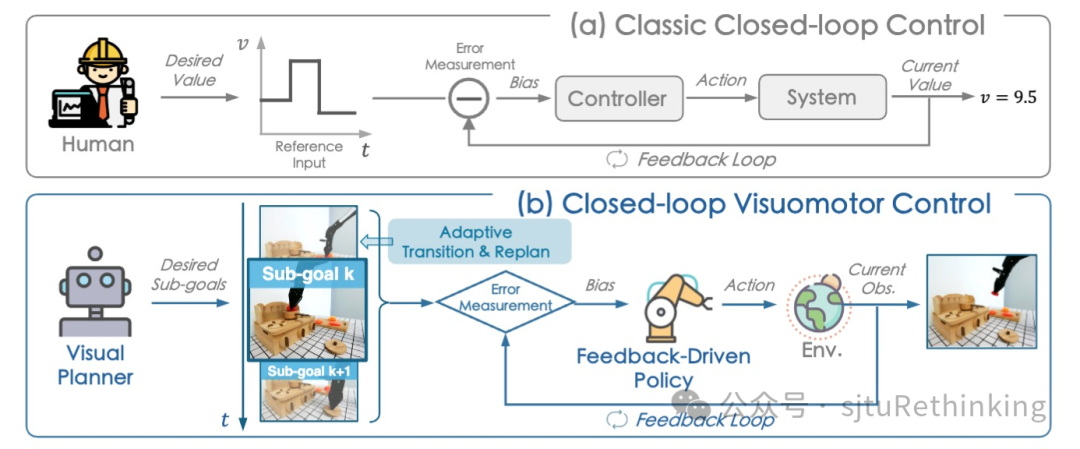
unsetunset【论文1】Rethinking Parity Check Enhanced Symmetry-Preserving Ansatzunsetunset 作者:严格,冉梦菲(本科生),王若丞(本科生),潘开森(本科生),严骏驰 简介:本文提出通过结合保汉明距离构型和奇偶性校验,在量子线路中构造纠错机制与硬约束,提升解决复杂优化问题的准确性和效率。我们首先分析了奇偶性校验作为保汉明距离构型的纠错方法在量子化学问题中的效果。在无噪声环境下,我们设计了保汉明距离构型线路,性能超越了单、双、甚至三激发情况下的UCC方法;在噪声环境下,我们发现仅在线路末端检测比特翻转并不足以充分纠错,因此在线路中持续进行奇偶性校验至关重要,并进一步优化了校验的插入频率。进一步,我们将奇偶性校验在纠错的基础上扩展为硬约束机制,结合保汉明距离构型的特点,提出了一种适应量子硬件拓扑结构的双重硬约束范式,适用于约束组合优化问题,尤其是广泛研究的二次分配问题(QAP)和旅行商问题(TSP)。我们通过将置换矩阵映射到量子比特拓扑结构,并利用奇偶校验进行投影测量将量子态限制在问题子空间内,从而在约束空间中找到最优解。我们在模拟器和超导量子处理器上实验验证了该方法,与多种基线方法(如HEA、QAOA和XYmixer)相较表现优越。以往的量子算法常通过编码惩罚项实现软约束,而我们展示了如何利用奇偶校验作为保汉明距离构型的纠错方案及硬约束,使得解始终保持在约束域内。 ![]() unsetunset【论文2】Closed-Loop Visuomotor Control with Generative Expectation for Robotic Manipulationunsetunset 作者:布清文,曾嘉,陈立,杨言超,周谷越,严骏驰,罗平,崔鹤鸣,马毅,李弘扬 简介:尽管近年来机器人技术和具身智能技术取得了显著进展,但长时序任务仍然是一个巨大的挑战。大多数现有方法缺乏与期望状态之间的实时度量,容易引起误差累积,导致鲁棒性不足。受经典闭环控制系统的启发,我们提出一种闭环视觉运动控制框架CLOVER,构造闭环反馈机制提高机器人自适应控制能力。CLOVER利用Video Diffusion Model预测未来的一系列期望状态,然后像经典的闭环反馈控制一样,基于当前状态和期望状态之间的偏差来调整动作,直至偏差在允许范围内。利用误差反馈机制,CLOVER还可以自适应地重新规划目标并判断任务完成进度。相比于先前的方法,CLOVER在真机任务上和CALVIN模拟环境上的长程任务性能提升显著,并且展现出更强的视觉抗干扰能力。
unsetunset【论文2】Closed-Loop Visuomotor Control with Generative Expectation for Robotic Manipulationunsetunset 作者:布清文,曾嘉,陈立,杨言超,周谷越,严骏驰,罗平,崔鹤鸣,马毅,李弘扬 简介:尽管近年来机器人技术和具身智能技术取得了显著进展,但长时序任务仍然是一个巨大的挑战。大多数现有方法缺乏与期望状态之间的实时度量,容易引起误差累积,导致鲁棒性不足。受经典闭环控制系统的启发,我们提出一种闭环视觉运动控制框架CLOVER,构造闭环反馈机制提高机器人自适应控制能力。CLOVER利用Video Diffusion Model预测未来的一系列期望状态,然后像经典的闭环反馈控制一样,基于当前状态和期望状态之间的偏差来调整动作,直至偏差在允许范围内。利用误差反馈机制,CLOVER还可以自适应地重新规划目标并判断任务完成进度。相比于先前的方法,CLOVER在真机任务上和CALVIN模拟环境上的长程任务性能提升显著,并且展现出更强的视觉抗干扰能力。
![]()
unsetunset【论文3】Unveiling The Matthew Effect Across Channels: Assessing Layer Width Sufficiency via Weight Norm Varianceunsetunset
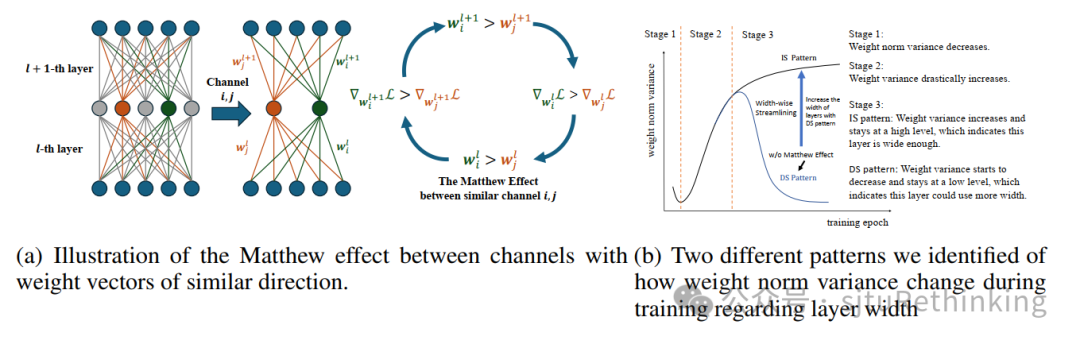
作者:陈奕廷,卜家梓(本科生),严骏驰 简介:在现有的深度学习实践中,如何在神经网络的不同层之间分配计算资源往往基于经验人为给定的,例如卷积神经网络的层宽度逐渐增大,Transformer的各层之间保持相同的宽度。是否存在一个指标可以衡量不同层之间宽度设定是否合理并指导神经网络的结构设计?在本文中,基于前人发现的神经网络在训练后同一层内部可能存在相似神经元的现象,我们指出同一层的相似神经元之间存在马太效应——即权重越大的通道对应的梯度越大。进一步地,我们发现对于神经网络的某一层,由窄到宽,训练时该层不同神经元的权重方差的变化展现出两种模式。我们在卷积神经网络(CNN),循环神经网络(RNN),图神经网络(GNN)以及ViT等结构上验证了这一发现。其中较宽的层由于存在相似神经元,其不同神经元权重范数方差在训练过程中逐渐上升并最后收敛;较窄的层由于相似神经元较少,其不同神经元权重范数方差在训练过程中呈现先上升后下降并最后收敛的现象。神经元权重范数方差的两种变化趋势为我们评估模型宽度并改进模型结构提供了一个可能的角度。我们对现有的卷积神经网络(ResNet和VGG)进行了结构调整,并以更少的参数,相似的计算复杂度取得了更好的图像分类准确度。
![]()
unsetunset【论文4】What Rotary Position Embedding Can Tell Us: Identifying Query and Key Weights Corresponding to Basic Syntactic or High-level Semantic Informationunsetunset
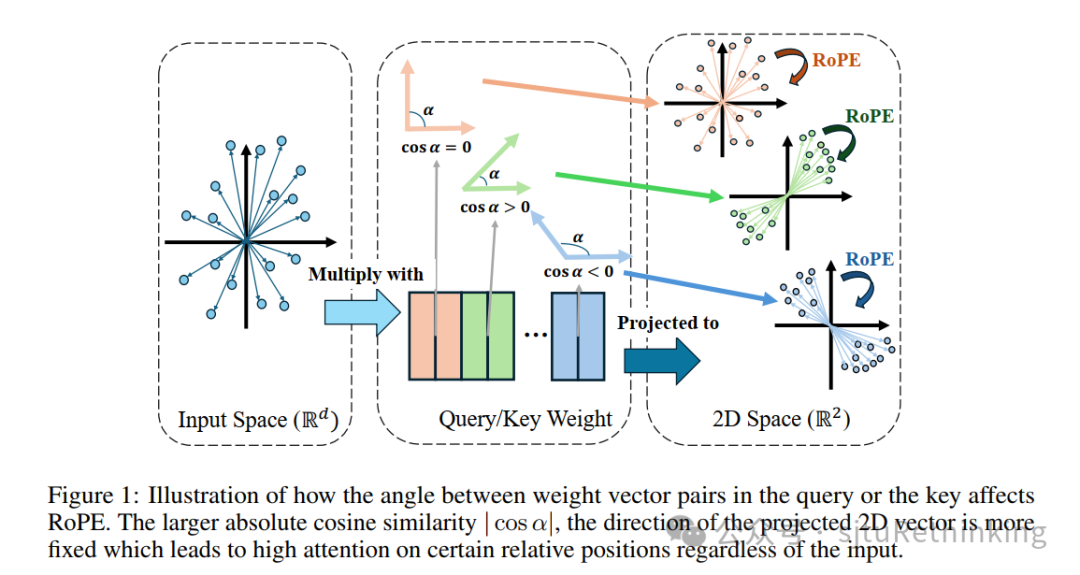
作者:陈奕廷,严骏驰 简介:Rotary Position Embedding(RoPE)作为一种被业界大模型广泛应用的位置编码方式,通过将Query和Key中的每两个数值对应的二维向量进行旋转来加载位置信息。在本文中,我们指出RoPE中二维向量的初始角度受对应权重向量对夹角的影响。在一种极端情况下,当对应两个权重向量共线,则任何输入向量与这两个权重向量内积得到的两个数值所对应的二维向量的角度是固定的。基于此,我们从理论上推导出某一权重向量对的余弦相似度绝对值越大,其对输入越不敏感,而是将注意力集中于特定的相对位置。进一步地,我们猜测:余弦相似度绝对值较大的权重对对应处理底层句法信息,余弦相似度绝对值较小的权重对对应处理高层语义信息。我们在多个开源大模型上进行了实验,并提供了经验性的实验结果来验证我们的猜测。特别地,我们发现大模型微调主要改变接近正交的权重向量对。基于这一发现,我们提出了只微调接近正交的权重向量对的参数高效微调(PEFT)方法 QK-IPM。我们实验验证了所提出的方法可以同时减少微调参数量和提升模型微调后的性能。
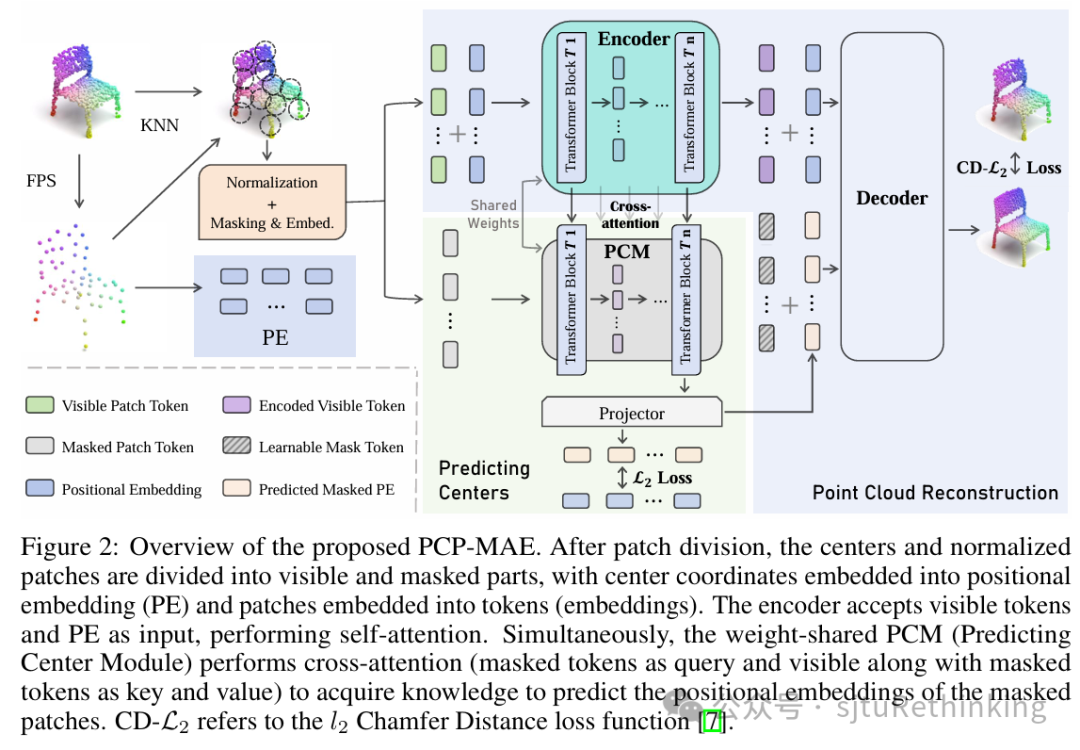
![]() unsetunset【论文5 (spotlight)】PCP-MAE: Learning to Predict Centers for Point Masked Autoencodersunsetunset
unsetunset【论文5 (spotlight)】PCP-MAE: Learning to Predict Centers for Point Masked Autoencodersunsetunset
作者:张祥东*(本科生),张少锋*,严骏驰 简介:掩码自编码器(Masked Autoencoders)在点云自监督学习中得到了广泛的探索,其中点云通常被划分为visible部分和masked部分。这些方法通常包括visible patches(normalized)和centers(位置信息)作为输入的encoder,以及一个接收encoder输出和masked centers以重建掩码块(masked patches)中每个点的decoder。然后,预训练的encoder用于下游任务。本文指出了Point-MAE的一个核心问题,即提供给decoder的masked centers泄露了关于物体三维结构的信息,使得点云的重建在不考虑encoder输出的情况下也能实现。基于这一观察,我们提出了一种有效的改进方法,称为预测点云中心的掩码自编码器(PCP-MAE),该方法通过引导模型学习预测块中心,增强encoder对相关信息的嵌入能力,防止信息泄露。具体来说,我们提出了一个预测中心模块(PCM),该模块与encoder共享参数,并通过额外的交叉注意力机制来预测masked centers。与其他替代方法相比,PCP-MAE在保持较高的预训练效率的同时,在多个下游任务中表现优异。
![]()
![]()
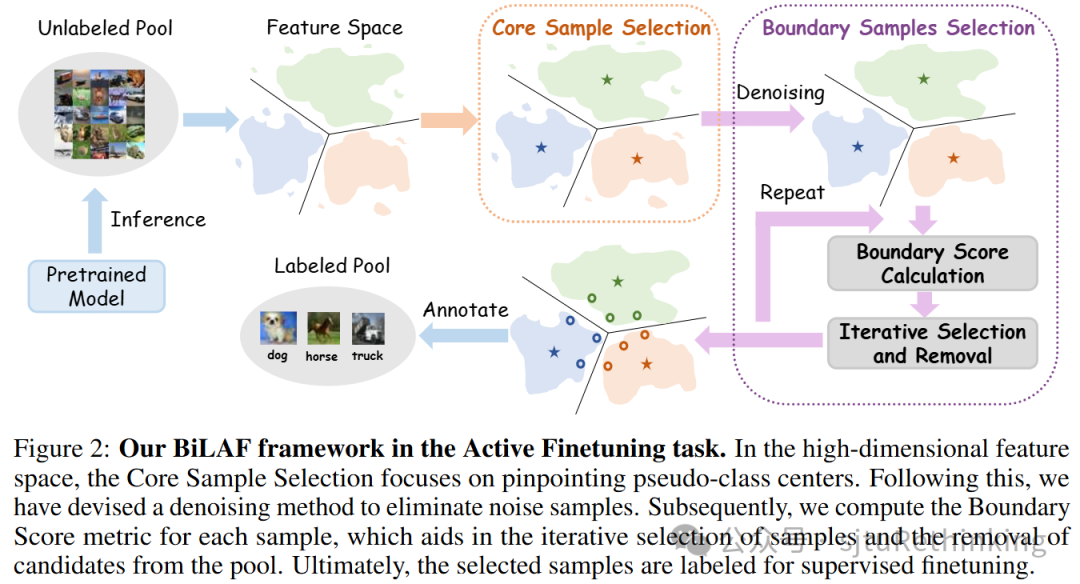
<<< 左右滑动见更多 >>>unsetunset【论文6】Boundary Matters: A Bi-Level Active Finetuning Methodunsetunset 作者:陆晗,谢熠辰,杨小康,严骏驰 简介:预训练-微调范式(Pretraining-Finetuning)已经在视觉任务和其他领域广泛采用。但是,微调阶段仍然需要高质量的标注样本。为克服这一挑战,主动微调(Active Finetuning)的任务被提出,旨在有限预算内选择最合适的样本进行模型微调。现有的主动学习方法在这种情况下无法胜任,因为它们在批量选择中会逐步积累偏差。而最近的主动微调方法仅专注于全局分布对齐,但忽略了样本对局部边界的贡献。因此,我们提出了一个双层主动微调框架(BiLAF),用于选择标注样本,在只进行一轮选择的过程中涵盖两个阶段:核心样本(Core Sample)选择以实现全局多样性,和边界样本(Boundary Sample)选择以实现局部决策不确定性。在不需要真实样本标签的情况下,我们的方法可以首先识别伪类中心(Pseudo-class Centers),进行全新的去噪技术,基于设计的评估指标(Boundary Score)并迭代选择边界样本。大量实验提供了对我们方法优越效果的定性和定量证据,可以有效超越现有的基线。
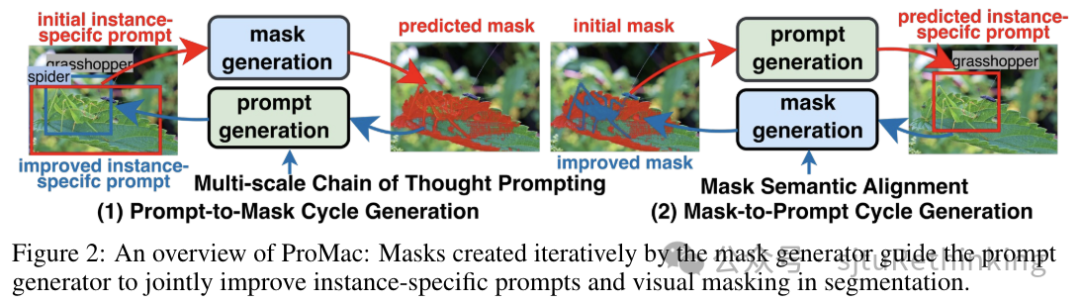
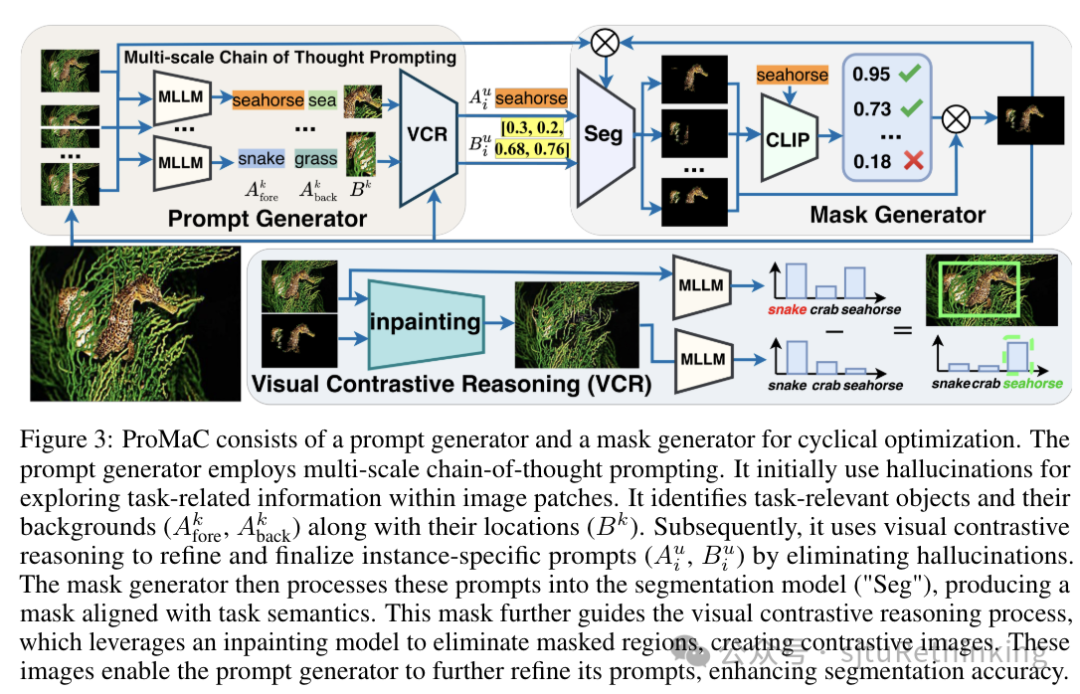
![]() unsetunset【论文7】Leveraging Hallucinations to Reduce Manual Prompt Dependency in Promptable Segmentationunsetunset 作者:胡健,林佳怡,严骏驰,龚少刚 简介:提示式分割(Promptable Segmentation)通常需要针对每个目标对象的特定手动提示来指导分割。为了减少这种需求,任务通用的提示式分割(Task-generic Promptable Segmentation)被引入,它使用单一的任务通用提示来分割同一任务中不同对象的各种图像。当前方法使用多模态大型语言模型(MLLMs)从任务通用提示中推理出详细的特定实例提示,以提高分割精度。这种分割方法的有效性极大地依赖于这些派生提示的精确度。然而,MLLMs在推理过程中经常出现幻觉,导致提示不准确。尽管现有方法专注于消除幻觉以改进模型,我们认为,如果正确利用,MLLM的幻觉可以揭示有价值的上下文见解,因为它们代表了超越图像个体的预训练大规模知识。在本文中,我们利用幻觉来挖掘图像中的任务相关信息,并验证其准确性,以提高生成提示的精确度。具体地,我们引入了一个迭代的提示-mask循环生成框ProMaC,包括一个提示生成器和一个mask生成器。提示生成器最初使用幻觉来从测试图像中提取扩展的上下文知识。然后这些幻觉被简化,形成精确的特定实例提示,指导mask生成器产生与任务语义一致的mask。生成的mask迭代地促使提示生成器更多地关注任务相关的图像区域并减少不相关的幻觉,从而共同改进了提示和mask。大量实验证明了ProMaC的有效性。 项目链接:https://lwpyh.github.io/ProMaC/
unsetunset【论文7】Leveraging Hallucinations to Reduce Manual Prompt Dependency in Promptable Segmentationunsetunset 作者:胡健,林佳怡,严骏驰,龚少刚 简介:提示式分割(Promptable Segmentation)通常需要针对每个目标对象的特定手动提示来指导分割。为了减少这种需求,任务通用的提示式分割(Task-generic Promptable Segmentation)被引入,它使用单一的任务通用提示来分割同一任务中不同对象的各种图像。当前方法使用多模态大型语言模型(MLLMs)从任务通用提示中推理出详细的特定实例提示,以提高分割精度。这种分割方法的有效性极大地依赖于这些派生提示的精确度。然而,MLLMs在推理过程中经常出现幻觉,导致提示不准确。尽管现有方法专注于消除幻觉以改进模型,我们认为,如果正确利用,MLLM的幻觉可以揭示有价值的上下文见解,因为它们代表了超越图像个体的预训练大规模知识。在本文中,我们利用幻觉来挖掘图像中的任务相关信息,并验证其准确性,以提高生成提示的精确度。具体地,我们引入了一个迭代的提示-mask循环生成框ProMaC,包括一个提示生成器和一个mask生成器。提示生成器最初使用幻觉来从测试图像中提取扩展的上下文知识。然后这些幻觉被简化,形成精确的特定实例提示,指导mask生成器产生与任务语义一致的mask。生成的mask迭代地促使提示生成器更多地关注任务相关的图像区域并减少不相关的幻觉,从而共同改进了提示和mask。大量实验证明了ProMaC的有效性。 项目链接:https://lwpyh.github.io/ProMaC/![]()
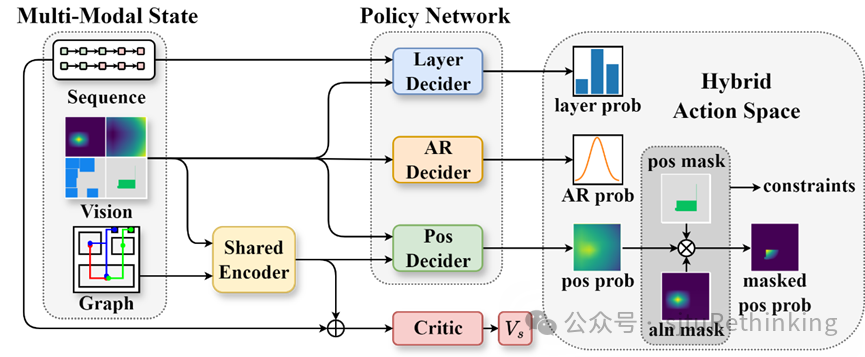
![]() unsetunset【论文8】FlexPlanner: Flexible 3D Floorplanning via Deep Reinforcement Learning in Hybrid Action Space with Multi-Modality Representationunsetunset 作者:钟睿哲,杜星波,开昰雄,唐振韬,许思源,郝建业,袁明轩,严骏驰 简介:在集成电路(Integrated Circuit,IC)设计流程中,布图规划(floorplanning,FP)意在求解每个模块的位置和形状。然而,随着多层堆叠的3D IC的出现,现有方法在灵活性上有所欠缺,无法处理多样化的约束。此外,受限于对传统启发式表征的依赖,它们无法较好处理3D IC中的跨层模块对齐约束,而这可能导致跨层数据通信的效率降低。为了解决这些问题,我们提出了FlexPlanner,一种灵活的、基于深度强化学习的方法。FlexPlanner采用多模态表征建模状态空间,同时引入混合动作空间,同时处理模块的位置、宽高比和摆放顺序。据我们所知,FlexPlanner是首个在三维布图规划任务中不依赖于传统启发式搜索的方法。因此,三维布图规划的解空间不再受到传统启发式表征的约束和限制,从而在对齐分数(alignment score)和线长(wire length)指标上实现显著优化。具体而言,FlexPlanner基于多模态表征对三维布图规划进行建模,包括视觉表征、图表征和序列表征。为了解决对传统启发式依赖问题,我们设计了一个新的策略网络,具有混合动作空间和异步层决策机制,以确定每个模块的位置、宽高比、摆放顺序。我们在开源数据集MCNC和GSRC上进行实验,以展现我们方法的有效性。我们将对齐分数从0.474显著提高到0.940,线长平均减少16%。此外,我们的方法在新电路上也展现出zero-shot/fine-tune迁移泛化性能。
unsetunset【论文8】FlexPlanner: Flexible 3D Floorplanning via Deep Reinforcement Learning in Hybrid Action Space with Multi-Modality Representationunsetunset 作者:钟睿哲,杜星波,开昰雄,唐振韬,许思源,郝建业,袁明轩,严骏驰 简介:在集成电路(Integrated Circuit,IC)设计流程中,布图规划(floorplanning,FP)意在求解每个模块的位置和形状。然而,随着多层堆叠的3D IC的出现,现有方法在灵活性上有所欠缺,无法处理多样化的约束。此外,受限于对传统启发式表征的依赖,它们无法较好处理3D IC中的跨层模块对齐约束,而这可能导致跨层数据通信的效率降低。为了解决这些问题,我们提出了FlexPlanner,一种灵活的、基于深度强化学习的方法。FlexPlanner采用多模态表征建模状态空间,同时引入混合动作空间,同时处理模块的位置、宽高比和摆放顺序。据我们所知,FlexPlanner是首个在三维布图规划任务中不依赖于传统启发式搜索的方法。因此,三维布图规划的解空间不再受到传统启发式表征的约束和限制,从而在对齐分数(alignment score)和线长(wire length)指标上实现显著优化。具体而言,FlexPlanner基于多模态表征对三维布图规划进行建模,包括视觉表征、图表征和序列表征。为了解决对传统启发式依赖问题,我们设计了一个新的策略网络,具有混合动作空间和异步层决策机制,以确定每个模块的位置、宽高比、摆放顺序。我们在开源数据集MCNC和GSRC上进行实验,以展现我们方法的有效性。我们将对齐分数从0.474显著提高到0.940,线长平均减少16%。此外,我们的方法在新电路上也展现出zero-shot/fine-tune迁移泛化性能。
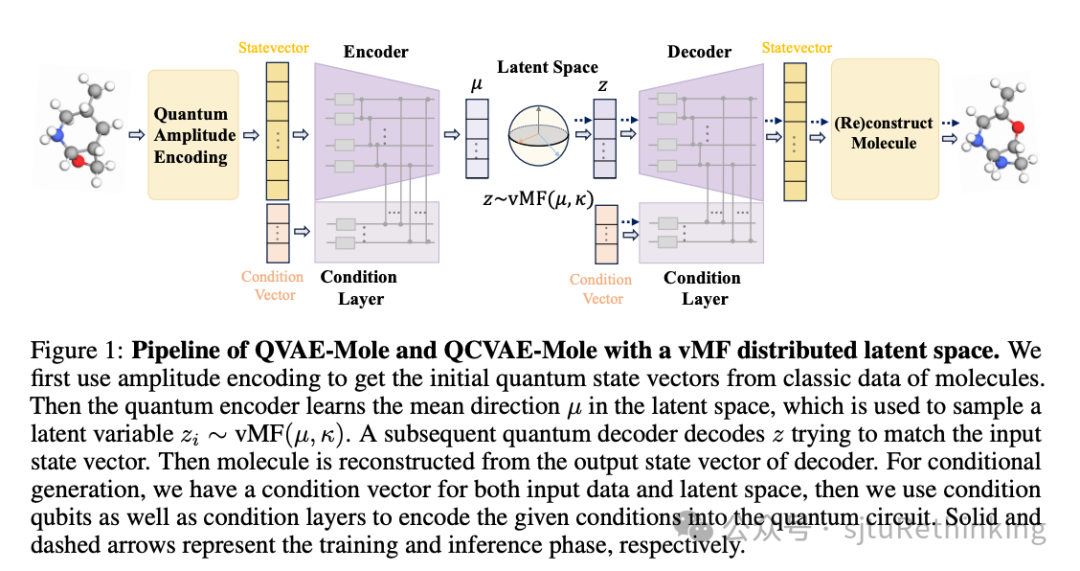
![]() unsetunset【论文9】QVAE-Mole: The Quantum VAE with Spherical Latent Variable Learning for 3-D Molecule Generationunsetunset 作者:吴怀瑾*,叶欣雨*,严骏驰 简介: 3D分子生成在材料科学、化学和生命科学等领域具有广泛的应用前景。鉴于量子技术潜在的优势,尤其是在NISQ(噪声中等规模量子)时代的背景下,本文首次提出了用于3D分子生成的量子参数化电路。我们选择变分自动编码器(VAE)作为生成框架,主要是因为其结构简单且能够一次性生成完整分子。相比经典方法中使用的自回归生成模型或扩散模型,VAE更适合与量子算法结合。具体来说,我们提出了一种为3D分子设计的量子编码方案,其量子比特复杂度为O(n)(n为分子中原子的数量),并采用冯·米塞斯-费舍尔(vMF)分布的潜在空间,以保持量子系统的内在相干性。此外,我们设计了条件编码方案,将特定分子属性嵌入量子电路中,从而实现属性控制的分子生成。通过实验验证,我们的量子神经网络模型不仅能够生成合理的3D分子结构,还在定量评估中展现了有竞争力的性能,并显著减少了与经典模型相比的电路参数。
unsetunset【论文9】QVAE-Mole: The Quantum VAE with Spherical Latent Variable Learning for 3-D Molecule Generationunsetunset 作者:吴怀瑾*,叶欣雨*,严骏驰 简介: 3D分子生成在材料科学、化学和生命科学等领域具有广泛的应用前景。鉴于量子技术潜在的优势,尤其是在NISQ(噪声中等规模量子)时代的背景下,本文首次提出了用于3D分子生成的量子参数化电路。我们选择变分自动编码器(VAE)作为生成框架,主要是因为其结构简单且能够一次性生成完整分子。相比经典方法中使用的自回归生成模型或扩散模型,VAE更适合与量子算法结合。具体来说,我们提出了一种为3D分子设计的量子编码方案,其量子比特复杂度为O(n)(n为分子中原子的数量),并采用冯·米塞斯-费舍尔(vMF)分布的潜在空间,以保持量子系统的内在相干性。此外,我们设计了条件编码方案,将特定分子属性嵌入量子电路中,从而实现属性控制的分子生成。通过实验验证,我们的量子神经网络模型不仅能够生成合理的3D分子结构,还在定量评估中展现了有竞争力的性能,并显著减少了与经典模型相比的电路参数。
![]() unsetunset【论文10】ReLIZO: Sample Reusable Linear Interpolation-based Zeroth-order Optimizationunsetunset 作者:王晓星*,秦啸涵*(本科生),杨小康,严骏驰 简介:梯度估计在零阶优化方法中至关重要,这些方法旨在通过采样更新方向和更新后的损失函数评估来获取下降方向。已有大量研究涉及平滑和线性插值等零阶优化方法。前者通过在当前样本点处以均匀或高斯分布采样更新方向,并利用损失函数值对更新方向做线性加权来估计梯度;而后者则根据采样更新方向与损失函数变化量,构建了线性方程组来求解梯度方向,该方法通常有更准确的估计,但每次迭代需要大量采样样本以保证方程组可解。本文基于线性插值策略,提出通过重用先前迭代中的采样样本和损失函数来减少梯度估计的计算量。具体而言,我们将梯度估计建模为一个二次约束线性规划问题,并推导出其解析解。该方法创新性地将所需样本大小与变量维度解耦,无需额外的采样条件,从而能够利用先前迭代中的采样样本。此外,本文提出基于索引的加速计算策略,由于对部分采样样本进行了复用,因此部分对梯度估计有贡献的中间变量可以直接索引,从而显著降低计算复杂性。本文在仿真函数和实际场景(黑箱对抗攻击和神经架构搜索)上的实验显示了其有效性和效率。
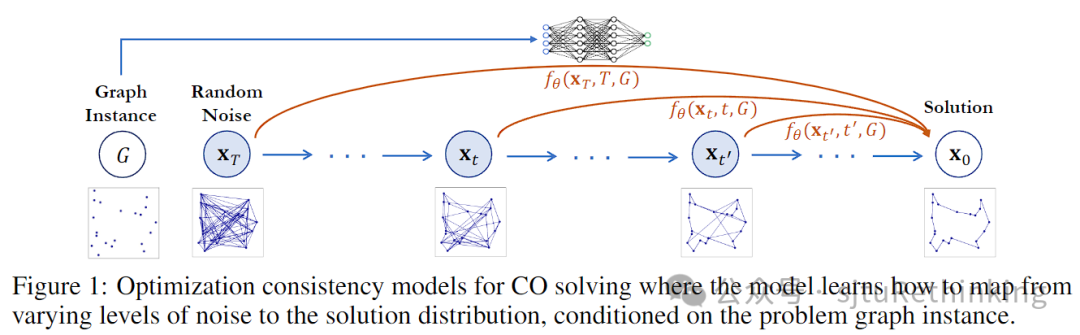
unsetunset【论文10】ReLIZO: Sample Reusable Linear Interpolation-based Zeroth-order Optimizationunsetunset 作者:王晓星*,秦啸涵*(本科生),杨小康,严骏驰 简介:梯度估计在零阶优化方法中至关重要,这些方法旨在通过采样更新方向和更新后的损失函数评估来获取下降方向。已有大量研究涉及平滑和线性插值等零阶优化方法。前者通过在当前样本点处以均匀或高斯分布采样更新方向,并利用损失函数值对更新方向做线性加权来估计梯度;而后者则根据采样更新方向与损失函数变化量,构建了线性方程组来求解梯度方向,该方法通常有更准确的估计,但每次迭代需要大量采样样本以保证方程组可解。本文基于线性插值策略,提出通过重用先前迭代中的采样样本和损失函数来减少梯度估计的计算量。具体而言,我们将梯度估计建模为一个二次约束线性规划问题,并推导出其解析解。该方法创新性地将所需样本大小与变量维度解耦,无需额外的采样条件,从而能够利用先前迭代中的采样样本。此外,本文提出基于索引的加速计算策略,由于对部分采样样本进行了复用,因此部分对梯度估计有贡献的中间变量可以直接索引,从而显著降低计算复杂性。本文在仿真函数和实际场景(黑箱对抗攻击和神经架构搜索)上的实验显示了其有效性和效率。![]() unsetunset【论文11】OptCM: The Optimization Consistency Models for Solving Combinatorial Problems in Few Shotsunsetunset 作者:郦洋*,郭锦沛*(本科生),汪润中,查宏远,严骏驰 扩散模型最近在组合优化领域取得了重要进展,成为神经网络求解器的重要backbone之一。然而,扩散模型的迭代采样过程需要在多个噪声级别上进行去噪,导致了较大的计算开销。我们提出了一种新方法,通过直接学习给定问题样例条件下从不同噪声级别到特定问题的最优解的映射,从而实现仅需极少的采样步数的高质量生成。我们将一致性训练范式推广至优化场景下来实现这一目标,模型对给定样例,最小化来自不同生成轨迹和时间步长的模型预测与最优解之间的差异。提出的优化一致性模型能够实现快速的单步解生成,同时允许进一步使用更多采样步数来提升求解质量,从而在采样质量和速度之间取得更好的平衡,成为神经求解器更为高效的backbone模型。此外,为了减少在训练过程中对历史实例的依赖与解决新样例时的差距,我们在测试阶段引入了一种基于一致性映射的梯度搜索方案。通过在噪声注入和去噪步骤交替进行的过程中,更新潜在解的概率分布,该方法利用目标函数梯度作为指导,进行更有效的解空间探索。实验表明,在旅行商问题和最大独立集等代表性任务上,优化一致性模型在解的质量和效率方面均表现出色,甚至在给定有限时间内超越了经典启发式SOTA算法LKH。与此前SOTA的神经网络求解器相比,优化一致性模型仅需单步生成和单步梯度搜索,就能够在大多数情况下超越需要数百步的最先进扩散模型,同时实现数十倍的加速。
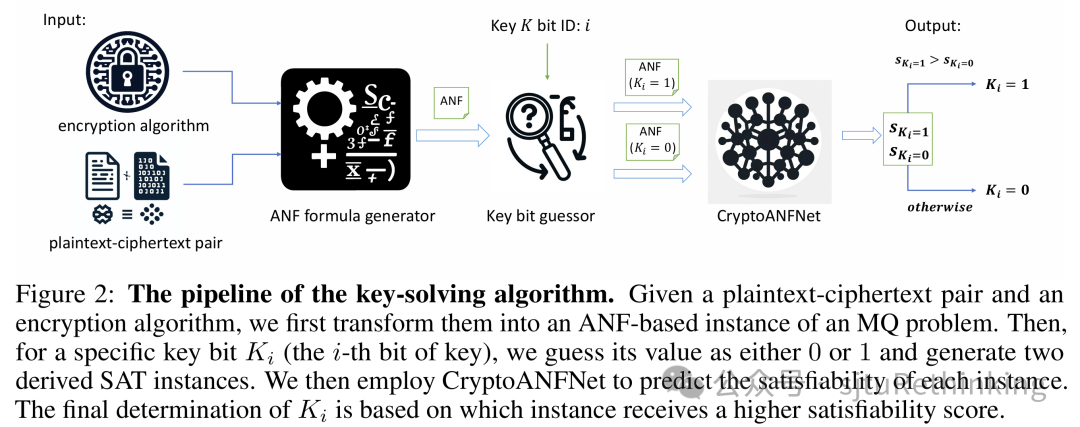
unsetunset【论文11】OptCM: The Optimization Consistency Models for Solving Combinatorial Problems in Few Shotsunsetunset 作者:郦洋*,郭锦沛*(本科生),汪润中,查宏远,严骏驰 扩散模型最近在组合优化领域取得了重要进展,成为神经网络求解器的重要backbone之一。然而,扩散模型的迭代采样过程需要在多个噪声级别上进行去噪,导致了较大的计算开销。我们提出了一种新方法,通过直接学习给定问题样例条件下从不同噪声级别到特定问题的最优解的映射,从而实现仅需极少的采样步数的高质量生成。我们将一致性训练范式推广至优化场景下来实现这一目标,模型对给定样例,最小化来自不同生成轨迹和时间步长的模型预测与最优解之间的差异。提出的优化一致性模型能够实现快速的单步解生成,同时允许进一步使用更多采样步数来提升求解质量,从而在采样质量和速度之间取得更好的平衡,成为神经求解器更为高效的backbone模型。此外,为了减少在训练过程中对历史实例的依赖与解决新样例时的差距,我们在测试阶段引入了一种基于一致性映射的梯度搜索方案。通过在噪声注入和去噪步骤交替进行的过程中,更新潜在解的概率分布,该方法利用目标函数梯度作为指导,进行更有效的解空间探索。实验表明,在旅行商问题和最大独立集等代表性任务上,优化一致性模型在解的质量和效率方面均表现出色,甚至在给定有限时间内超越了经典启发式SOTA算法LKH。与此前SOTA的神经网络求解器相比,优化一致性模型仅需单步生成和单步梯度搜索,就能够在大多数情况下超越需要数百步的最先进扩散模型,同时实现数十倍的加速。![]() unsetunset【论文12】Learning Plaintext-Ciphertext Cryptographic Problems via ANF-based SAT Instance Representationunsetunset 作者:郑心浩,郦洋,范存心(本科生),吴怀瑾,宋鑫浩(本科生),严骏驰 简介:机器学习在基于SAT的密码分析中展现了优势。基于机器学习的求解器利用数据驱动的学习方法处理大型数据集,具有较快的预测速度和自适应学习能力。密码分析中的密钥求解问题可以自然转化为SAT实例,可以利用机器学习方法来自动发现密码实例中的结构性特点。然而,大规模和复杂的密码实例对先前的机器学习求解器提出了重大挑战,这些算法通常依赖合取范式(CNF)对密码问题进行编码,并且主要在变量数相对较少的实例中有效,其面对复杂、大规模的密码实例表现有限,特别是密码中的XOR操作难以用合取范式(CNF)有效表示。这些实例通常需要大量子句来编码复杂操作,导致问题规模膨胀,增加了求解难度。 为解决这一问题,我们提出以代数标准型(ANF)替代CNF表示XOR操作。在ANF中,公式表示为在GF(2)上使用加法(XOR)和乘法(AND)操作的多项式集合。ANF能简洁地表达高阶操作,特别适用于密码问题。然而,如何将ANF表示为图结构以便于网络进行学习是一个具有挑战性的问题,并且将ANF应用于现有SAT求解器不像CNF那样直接,导致其在诸如密码问题等复杂场景中的后续应用受到阻碍。因此,为了学习ANF形式的SAT实例的特征,我们提出了一种基于ANF的图结构用于表示密码应用中的SAT实例,并提出了CryptoANFNet,通过ANF的图表示来预测SAT实例可满足性。与CNF表示相比,ANF使SAT实例的节点数量大幅减少,显著提高了模型效率。CryptoANFNet不仅能够处理更大规模的实例,还能在高阶的SAT实例数据上达到了更高的准确率。此外,我们提出了一种密钥解密算法,通过明文-密文对生成ANF基的SAT实例,利用两个扩展SAT实例的输出推导正确的密钥位值。在数据集上的实验表明,该方法进一步提高了预测的准确性。
unsetunset【论文12】Learning Plaintext-Ciphertext Cryptographic Problems via ANF-based SAT Instance Representationunsetunset 作者:郑心浩,郦洋,范存心(本科生),吴怀瑾,宋鑫浩(本科生),严骏驰 简介:机器学习在基于SAT的密码分析中展现了优势。基于机器学习的求解器利用数据驱动的学习方法处理大型数据集,具有较快的预测速度和自适应学习能力。密码分析中的密钥求解问题可以自然转化为SAT实例,可以利用机器学习方法来自动发现密码实例中的结构性特点。然而,大规模和复杂的密码实例对先前的机器学习求解器提出了重大挑战,这些算法通常依赖合取范式(CNF)对密码问题进行编码,并且主要在变量数相对较少的实例中有效,其面对复杂、大规模的密码实例表现有限,特别是密码中的XOR操作难以用合取范式(CNF)有效表示。这些实例通常需要大量子句来编码复杂操作,导致问题规模膨胀,增加了求解难度。 为解决这一问题,我们提出以代数标准型(ANF)替代CNF表示XOR操作。在ANF中,公式表示为在GF(2)上使用加法(XOR)和乘法(AND)操作的多项式集合。ANF能简洁地表达高阶操作,特别适用于密码问题。然而,如何将ANF表示为图结构以便于网络进行学习是一个具有挑战性的问题,并且将ANF应用于现有SAT求解器不像CNF那样直接,导致其在诸如密码问题等复杂场景中的后续应用受到阻碍。因此,为了学习ANF形式的SAT实例的特征,我们提出了一种基于ANF的图结构用于表示密码应用中的SAT实例,并提出了CryptoANFNet,通过ANF的图表示来预测SAT实例可满足性。与CNF表示相比,ANF使SAT实例的节点数量大幅减少,显著提高了模型效率。CryptoANFNet不仅能够处理更大规模的实例,还能在高阶的SAT实例数据上达到了更高的准确率。此外,我们提出了一种密钥解密算法,通过明文-密文对生成ANF基的SAT实例,利用两个扩展SAT实例的输出推导正确的密钥位值。在数据集上的实验表明,该方法进一步提高了预测的准确性。
![]()
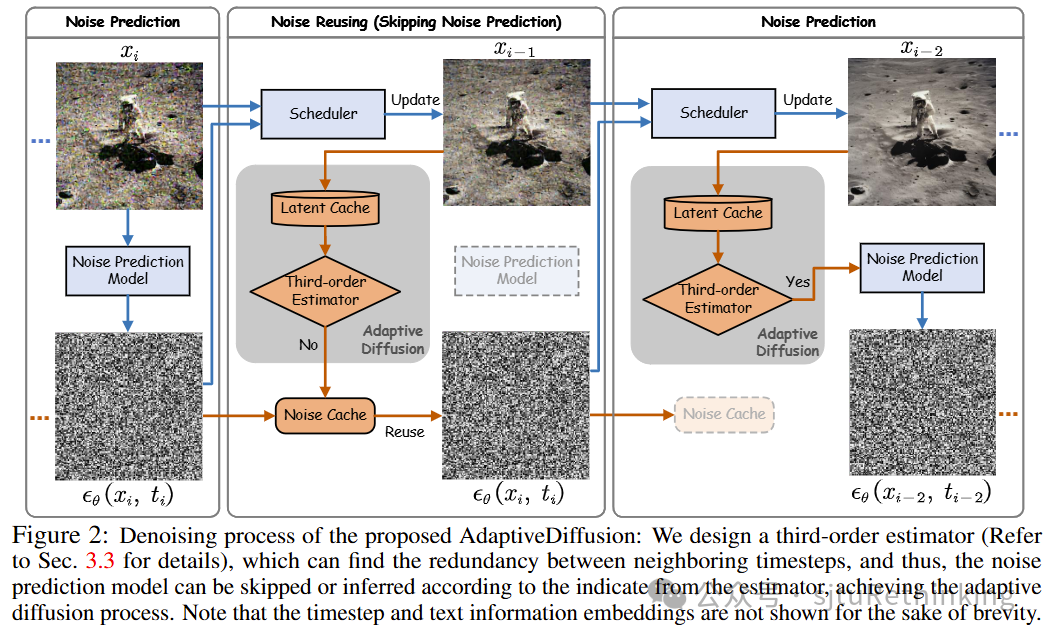
![]() unsetunset【论文13】Training-Free Adaptive Diffusion with Bounded Difference Approximation Strategyunsetunset 作者:叶涵诚,袁家康,夏纫秋,闫翔超,陈涛,严骏驰,石博天,张铂 简介:扩散模型在近期的高质量图像与视频合成领域取得了显著成就。然而,当前扩散模型中所采用的去噪技术普遍基于逐步骤的噪声预测,这种做法带来了较高的计算负担,对于实时交互式应用而言,所造成的延迟是难以接受的。本文提出了一种名为自适应扩散(AdaptiveDiffusion)的新方法,旨在通过在去噪过程中自适应地减少噪声预测步骤,从而有效降低这一性能瓶颈。本方法在确保去噪最终结果与原始全步骤过程相一致的前提下,力求最大化跳过噪声预测步骤的数量。具体而言,跳过策略是由去噪过程中不同时间步隐空间的三阶差分所引导,该差分值有效指示了时间步的稳定性,从而促进了先前噪声预测结果的复用。通过对图像和视频扩散模型的广泛实验验证,本研究方法显著提升了去噪效率,在保证与原始全步骤过程生成质量相同的情况下,实现了平均2至5倍的速度提升。
unsetunset【论文13】Training-Free Adaptive Diffusion with Bounded Difference Approximation Strategyunsetunset 作者:叶涵诚,袁家康,夏纫秋,闫翔超,陈涛,严骏驰,石博天,张铂 简介:扩散模型在近期的高质量图像与视频合成领域取得了显著成就。然而,当前扩散模型中所采用的去噪技术普遍基于逐步骤的噪声预测,这种做法带来了较高的计算负担,对于实时交互式应用而言,所造成的延迟是难以接受的。本文提出了一种名为自适应扩散(AdaptiveDiffusion)的新方法,旨在通过在去噪过程中自适应地减少噪声预测步骤,从而有效降低这一性能瓶颈。本方法在确保去噪最终结果与原始全步骤过程相一致的前提下,力求最大化跳过噪声预测步骤的数量。具体而言,跳过策略是由去噪过程中不同时间步隐空间的三阶差分所引导,该差分值有效指示了时间步的稳定性,从而促进了先前噪声预测结果的复用。通过对图像和视频扩散模型的广泛实验验证,本研究方法显著提升了去噪效率,在保证与原始全步骤过程生成质量相同的情况下,实现了平均2至5倍的速度提升。
![]()
Benchmark Track
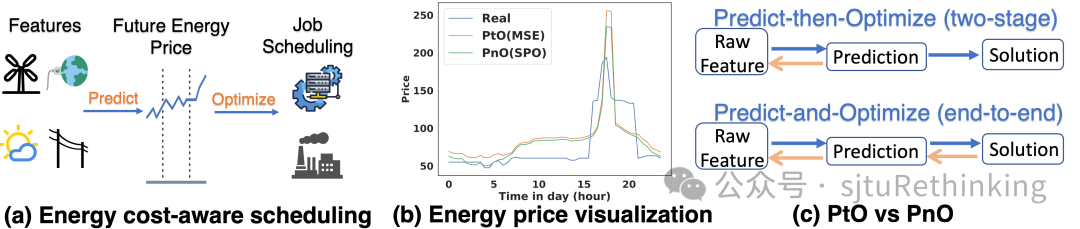
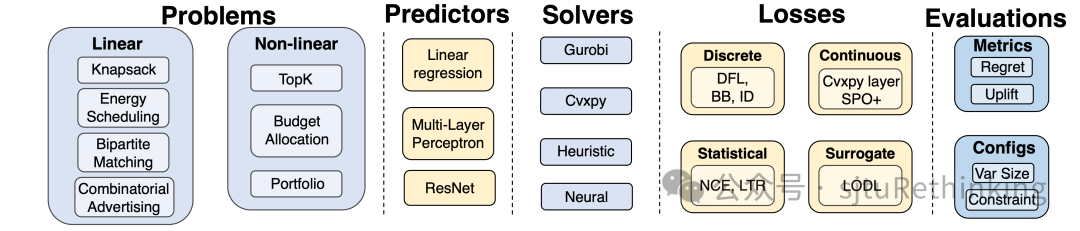
unsetunset【论文1】There is No Silver Bullet: Benchmarking Methods in Predictive Combinatorial Optimizationunsetunset 作者:耿皓宇*,阮航*(本科生),汪润中,郦洋,王扬,陈磊,严骏驰 简介:决策问题在工业调度生产、商业增长、资产配置等众多领域中扮演着核心角色。但在现实世界中,这些决策问题所依赖的参数并非一成不变,而是随着时间推移、环境变化等因素动态调整。这种参数的不确定性和变化性,为运筹优化问题的决策带来了显著的挑战。近年来,机器学习和深度学习技术在众多业界的预测任务中广泛应用。然而,如何将深度学习的预测能力与运筹优化的求解能力有效融合,以实现不确定场景下的智能决策,仍然是学术界和工业界共同关注的挑战性问题。
![]()
针对不确定场景下的组合优化问题,我们提出一个预测决策一体化(Predict-and-Optimize)评测基准,和传统的两阶段先预测-后优化方法(Predict-then-Optimize)做比较。我们对现有的预测决策一体化方法做了系统性的归类梳理,包含每一类的设计思想、适用条件、复杂度、实际决策质量等分析。我们将评测基准解耦为数据集、预测模型、求解器、损失函数、评估模块等多个模块,在11个方法和8个数据集上全面进行评测,包括提出一个在广告营销问题的真实工业数据集,实验表明在其中7个数据集上一体化方法可以相比传统两阶段方法取得显著更好的决策质量。我们进一步给出影响这些方法的关键要素的实验分析,来探索预测决策一体化相较于传统的先预测后优化策略所具有的潜在优势、挑战和前景。
![]()
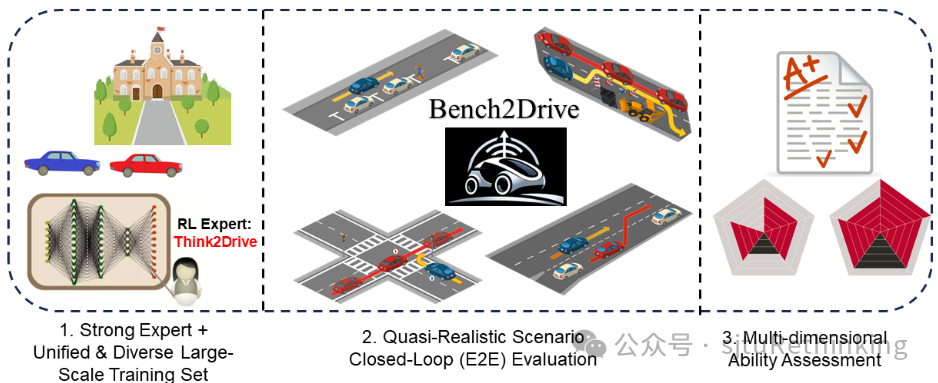
unsetunset【论文2】Bench2Drive: Towards Multi-Ability Benchmarking of Closed-Loop End-To-End Autonomous Drivingunsetunset
作者:贾萧松*,杨振杰*,李奇峰*,张致远*(本科生),严骏驰 简介:在大数据大模型大算力年代,自动驾驶技术同样处于变革之中,其中,端到端自动驾驶由于其在数据驱动范式下的强扩展潜力而备受关注。现有的端到端自动驾驶方法大多是开环评估,使用L2误差和碰撞率作为指标,这已经被广泛认为是无法充分反映算法的驾驶性能的。已有的闭环评测框架(例如,CARLA 1.0中的Town05Long和Longest6)使用驾驶评分作为指标,而这一指标由于累乘不平滑的计算方式和长途行驶中的大量随机性而具有很高的方差。此外,已有闭环评测的方法通常收集自己的数据进行训练,无法实现算法级别的公平比较。为了满足对全面、闭环、公平的自动驾驶测试环境的迫切需求,我们提出了Bench2Drive,这是第一个以闭环方式评估端到端自动驾驶系统多种能力的基准。Bench2Drive的官方训练数据由200万帧完全标注的帧组成,收集自10000多个短片段,囊括44种交互场景(切入、超车、绕行等)、23种天气(晴天、雾天、雨天等)和12个城镇(城市、乡村、大学等)。其评估流程要求端到端自动驾驶模型在不同地点和天气条件下通过44种交互场景,总计220条路线,从而提供在不同情况下驾驶能力的全面评估。
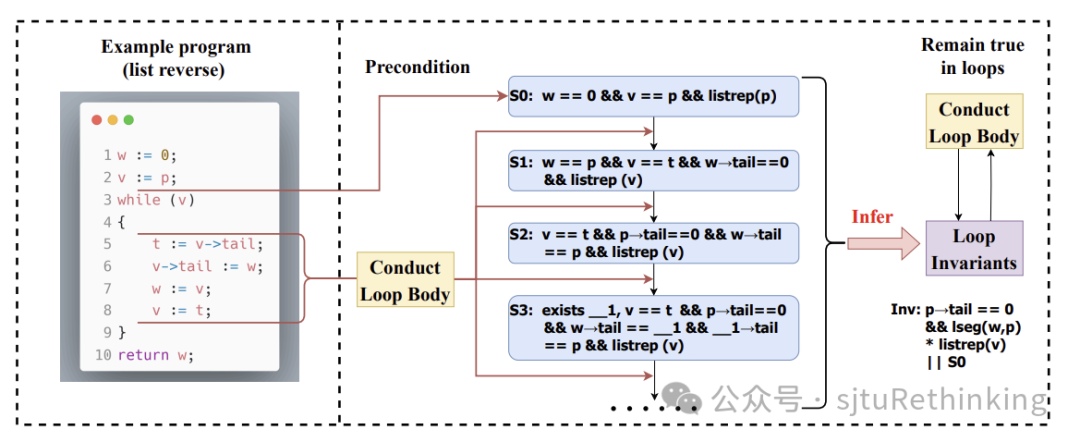
![]() unsetunset【论文3】Towards General Loop Invariant Generation: A Benchmark of Programs with Memory Manipulationunsetunset 作者:刘畅*,吴熙炜*,冯缘(本科生),曹钦翔*,严骏驰* 简介:随着软件系统复杂度的日益增加,程序验证在确保软件可靠性方面变得愈发重要。循环不变量作为一种在循环的每次迭代前后都保持为真的条件,是程序验证过程中不可或缺的要素。然而,传统的证明工具和基于机器学习的方法在生成循环不变量时,往往需要专家的介入或大量的标注数据支持,且通常只能处理数值属性的验证任务。当面对包含复杂数据结构和内存操作的程序时,这些方法显得力不从心,难以实现自动化处理。
unsetunset【论文3】Towards General Loop Invariant Generation: A Benchmark of Programs with Memory Manipulationunsetunset 作者:刘畅*,吴熙炜*,冯缘(本科生),曹钦翔*,严骏驰* 简介:随着软件系统复杂度的日益增加,程序验证在确保软件可靠性方面变得愈发重要。循环不变量作为一种在循环的每次迭代前后都保持为真的条件,是程序验证过程中不可或缺的要素。然而,传统的证明工具和基于机器学习的方法在生成循环不变量时,往往需要专家的介入或大量的标注数据支持,且通常只能处理数值属性的验证任务。当面对包含复杂数据结构和内存操作的程序时,这些方法显得力不从心,难以实现自动化处理。
![]()
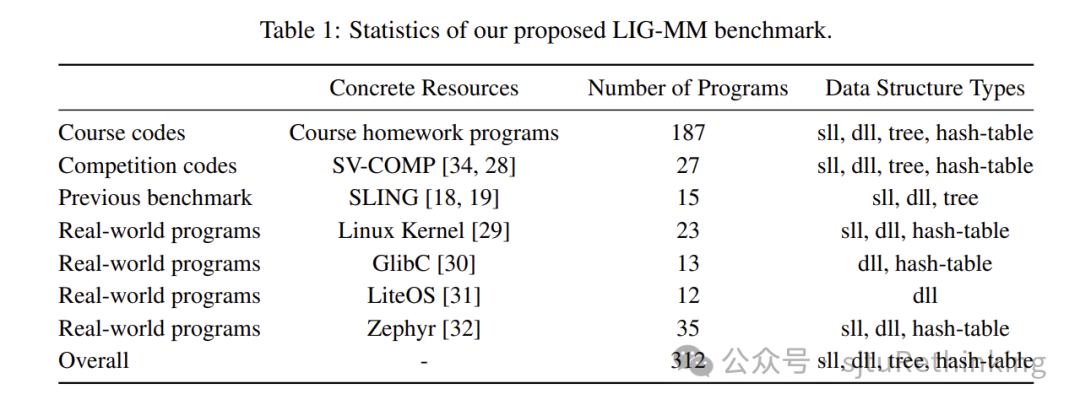
为了解决这一问题,我们提出了一个全新的基准数据集——LIG-MM,专门用于包含复杂数据结构和内存操作的程序。LIG-MM共收录了312个程序,涵盖了多个来源,包括大学课程中的日常程序、国际竞赛(SV-COMP)中的竞赛程序、前人论文中的基准程序(SLING),以及一些真实世界的软件系统(如Linux内核、GlibC、LiteOS和Zephyr)中的代码。通过对这些程序的测试,我们发现现有的方法(包括GPT-4)在验证这些复杂程序时都存在显著的局限性,难以实现自动化验证。
![]()
因此,我们提出了一种新的LLM-SE框架,通过自监督学习对大语言模型(LLM)进行微调,并结合符号执行技术,来生成循环不变量。实验结果表明,在LIG-MM基准上,我们的LLM-SE框架在准确性和效率方面均超越了现有的最先进方法,为在真实世界场景中实现程序自动化验证提供了新的方向。我们的代码已经开源,包括所有的LIG-MM数据集和我们提出的LLM-SE方法,链接是:https://github.com/Thinklab-SJTU/LIG-MM