

最近,机器学习和人工智能的快速发展为改进美国防部(DOD)兵棋推演创造了越来越多的机会。本研究旨在利用现代框架、算法和云硬件来提高美国防部的兵棋推演能力,具体重点是缩短训练时间、提高部署灵活性,并展示经过训练的神经网络如何为推荐行动提供一定程度的确定性。这项工作利用开源并行化框架来训练神经网络并将其部署到 Azure 云平台。为了衡量训练有素的网络选择行动的确定性,采用了贝叶斯变异推理技术。应用开源框架后,训练时间缩短了十倍以上,而性能却没有任何下降。此外,将训练好的模型部署到 Azure 云平台可有效缓解基础设施的限制,贝叶斯方法也成功提供了训练模型确定性的衡量标准。美国防部可以利用机器学习和云计算方面的这些进步,大大加强未来的兵棋推演工作。
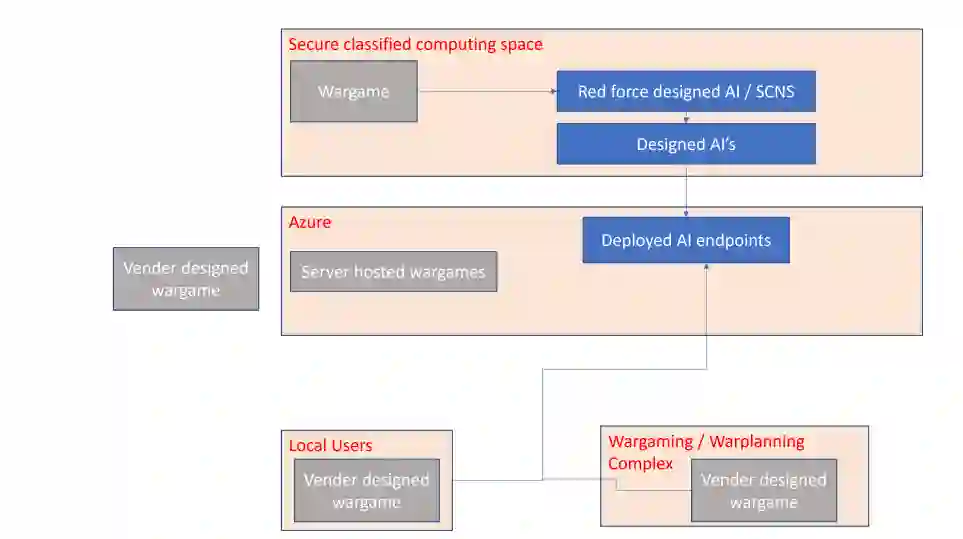
图 4.1. 未来兵棋推演开发者与用户在云和本地实例中的关系
人工智能(AI)在过去几十年中取得了显著进步。最近在深度学习和强化学习(RL)方面取得的进步使人工智能模型在各种视频游戏中的表现超过了人类。随着美国国防部(DOD)继续投资开发用于兵棋推演和战争规划应用的人工智能模型,许多方面都有了改进。
本研究调查了现代机器学习(ML)技术的应用,以提高兵棋推演的功效。这项研究表明,即使在没有图形处理器(GPU)的情况下,并行化也能大幅缩短 RL 问题的训练时间,而且对平均得分的影响微乎其微。这一发现强调了并行处理框架对未来 RL 训练工作的重要性。本研究利用 Ray 框架来协调 RL 训练的并行化,并评估了两种算法:近端策略优化(PPO)和重要性加权行为者学习者架构(IMPALA),包括使用和不使用 GPU 加速的情况。这项研究成功地表明,在保持总体平均性能的同时,训练时间可以减少一到两个数量级。
本研究的第二部分探讨了将本地训练的模型与本地环境解耦的实用方法,展示了将这些模型部署到云环境的可行性。采用的模型是利用开源框架开发的,并部署在微软 Azure 云平台上。这项研究成功地将训练有素的 RL 模型部署到云环境中,并集成到本地训练和评估中。
最后,本论文证明了贝叶斯技术可以集成到 RL 模型中,从而有可能提高人机协作的价值。这是通过将贝叶斯方法纳入模型架构,并在运行时利用这些实施层的独特属性来实现的。这项研究取得了成功,并展示了如何将人工智能移动选择的确定性措施合成并呈现给人类。
总之,这项研究强调了并行化的重要性,为基于云环境的训练模型提供了概念验证,并证明了将贝叶斯方法纳入人工智能模型以改善人机协作的可行性,从而为推进 ML 和兵棋推演技术做出了贡献。




