
Neurips 2024 让大语言模型像人类专家一样使用代码解决图分析推理任务
- 论文链接: (https://arxiv.org/abs/2409.19667/)
- GitHub链接: (https://github.com/BUPT-GAMMA/ProGraph)
背景与动机
图是现实世界中十分常用的数据结构(例如社交网络和推荐系统等),让大语言模型(后文简称大模型)学会处理图的能力,是迈向更高级通用智能的关键一步。近期,许多研究者提出将大模型扩展到需要图理解和分析的场景,然而我们认为现有研究存在以下主要缺点:
- 现有工作解决问题的过程完全基于大模型的逐步推理。但即使在思维链(CoT)的帮助下,当前大模型的推理深度仍然很浅。这意味着当图分析任务难度较大时,很容易出现幻觉或推理错误,导致任务失败。
- 现有工作需要在提示(prompt)中对图结构进行描述,受限于上下文长度限制,无法适用于大规模图数据的处理。
- 对于Llama等开源模型,仍然缺乏面向图分析推理场景的指令微调数据集,导致结果并不理想。
- 对于ChatGPT等闭源模型,也需要构建面向图分析推理场景的外部知识库而不是仅通过提示工程来提高模型的表现。
核心思路:为解决上述不足,我们模仿人类专家解决问题的思路,首次提出让大语言模型通过编写代码来解决图分析推理问题的方法:例如在百万级节点的图中计算最短路时,人类专家不会把整个图装进大脑做逐步推理,而是会调用NetworkX等Python库使用几行代码快速准确地解决问题。具体而言,在模型进行图分析任务时,我们引导模型编写代码并调用相关Python库,之后我们提取并执行模型回答中的相关代码来获得答案。这种基于编程的解决方式可以从文件中读取图数据,从而避开大模型上下文长度的限制,应用于任意规模的图数据分析。 为了更好地提高大模型编写代码解决图分析问题的表现,我们探索了如下方法对模型进行能力提升。
- 对于开源模型,我们构造了包含两步思维链推理(先推理应该使用的API,再编写代码)的问答数据集,使用指令微调的方式让模型学会编写代码解决问题。
- 对于闭源模型,我们收集了包括NetworkX在内6个Python库的API文档,然后使用检索增强生成(RAG)技术,让模型在回答问题前先熟悉文档信息,然后再基于文档编写代码,从而提高模型的表现。
- 我们分析了不同模型在编写代码方面的错误原因,未来可以基于这些分析,进一步提高开源模型和闭源模型编写代码解决图分析问题的能力。
模型框架
问题处理流程
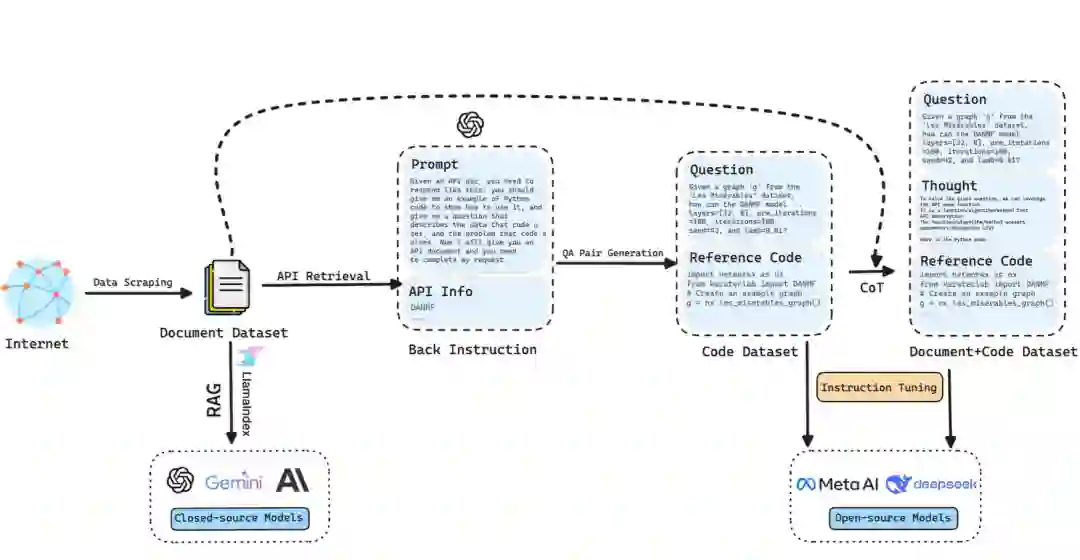
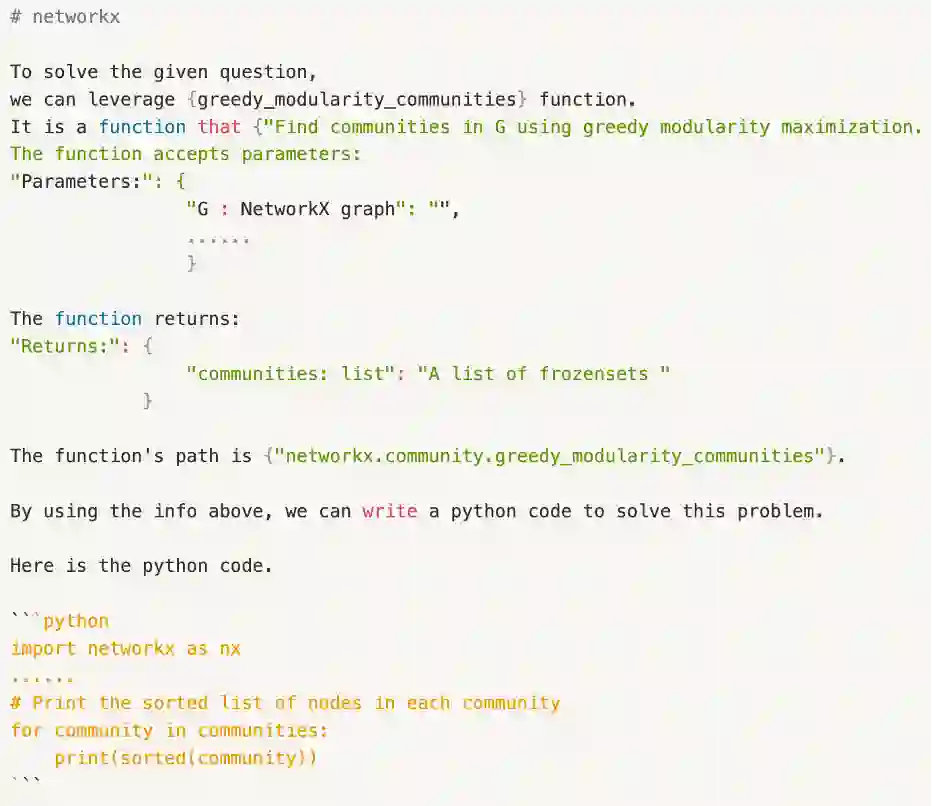
图2 两步推理思考过程示例
基准构造

实验设置
- 数据集:ProGraph
- 模型:Llama-3-8B-Instruct, Deepseek-Coder-7b-Instruct-v1.5, GPT-4o, GPT-4-turbo, GPT-3.5, Gemini-Pro-1.5, Gemini-Pro-1.0, Claude-3-Haiku, Claude-3-Sonnet, Claude-3-Opus
- 评测方法:用代码执行通过率(pass rate)衡量模型编写代码的基本能力,用正确率(accuracy)衡量模型解决问题的能力。
- 微调模型框架:alignment-handbook
- 微调模型数据集:LLM4Graph
实验结果
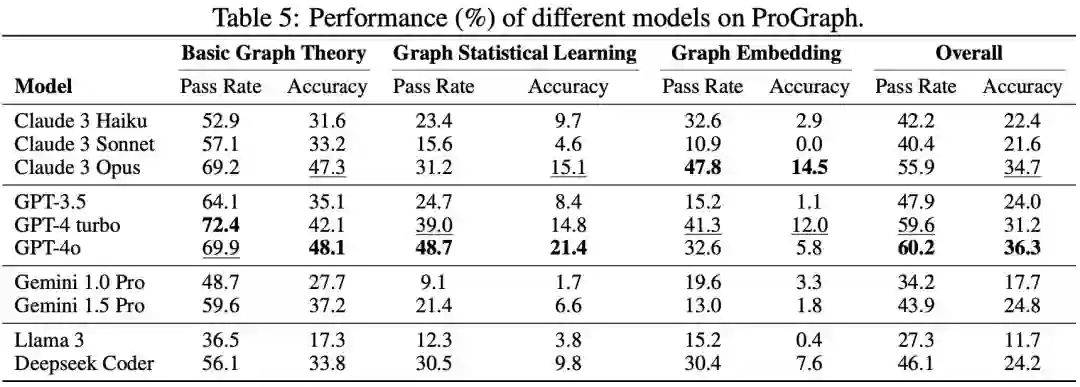
基准实验
开源模型和闭源模型的性能提升
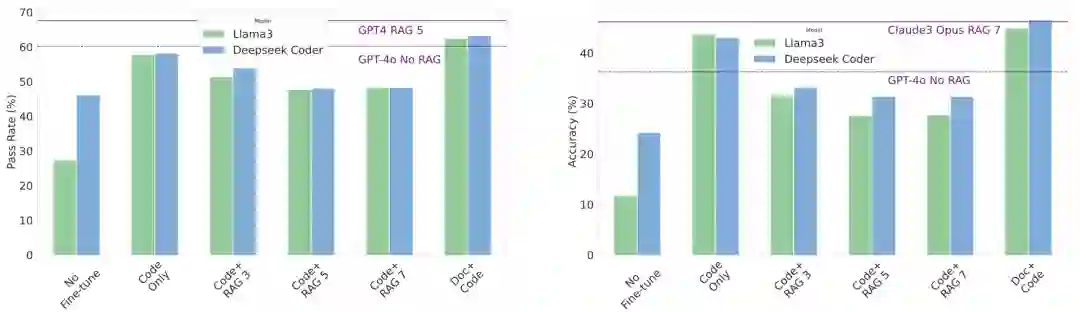
图4 使用本文构建的数据集对开闭源大模型的性能提升 通过我们提出的数据集和方法对大模型进行增强后,我们可以看到闭源模型的性能获得了一定提升,开源模型的性能有了非常显著的提高,验证了本工作的有效性。
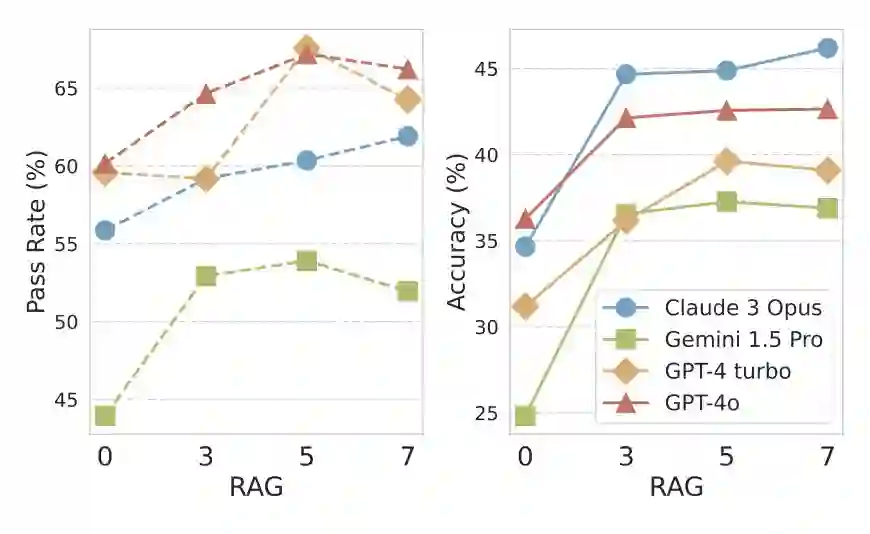
**闭源模型RAG分析
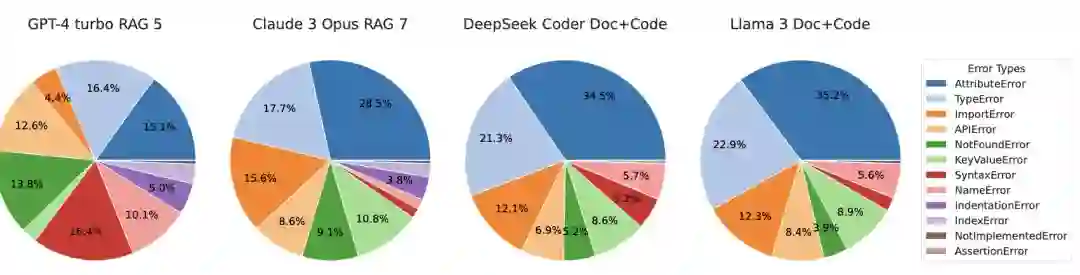
**Python代码错误类型分析
总结
在本文中,我们首次提出通过编程来提升大模型解决图分析推理任务的能力,并使用主流的开源模型和闭源模型进行研究。我们提供了新的基准数据集ProGraph,用来衡量模型解决复杂图分析推理任务的能力,也构建了用于对开源模型进行指令微调的LLM4Graph数据集。实验表明检索增强生成(RAG)和指令微调等方式可以有效利用我们构造的数据集,提升现有大模型的性能。
