

论文链接:https://arxiv.org/pdf/2402.07197.pdf 代码链接:https://github.com/alibaba/GraphTranslator
引言
图模型(GM)如图神经网络(GNN),利用节点特征和图结构来学习表征并预测,在多种领域表现出色,但GM通常局限于预定义任务如节点分类,难以适应新的类别和任务。而大型语言模型(LLM)如ChatGPT,在处理开放式任务和理解自然语言指令方面显示了巨大潜力,推动了跨模态研究的发展。最近,将LLM应用于图的工作可分为两类,如下图(a)-1和(a)-2所示:(1)利用LLM以其海量知识增强节点的文本属性,然后通过GM生成预测;(2)或者是将节点以token或文本的形式,直接输入给LLM来作为独立的预测器。然而,这些方法无法同时解决处理预定义的任务和开放式任务。这就很自然地提出了一个问题:「我们能否在图学习领域建立一个既能解决预定义任务又能解决开放式任务的模型?」
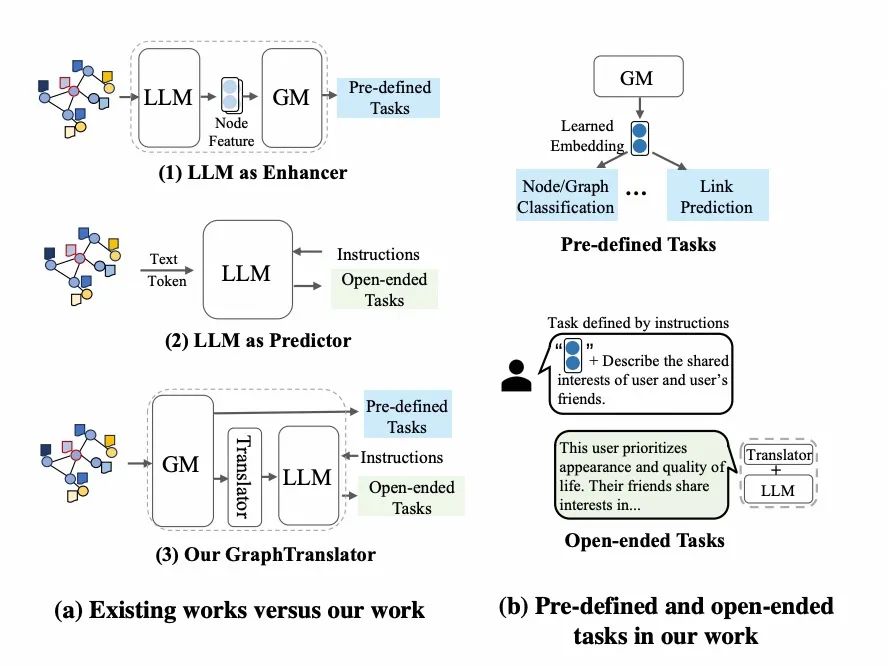
本文提出一个名为GraphTranslator的框架,结合预训练的图模型(GM)与大型语言模型(LLM)来处理预定义和开放式任务。GraphTranslator中的**「Translator」模块负责将图节点嵌入转换为LLM可理解的token嵌入,通过学习graph queries来提取语言信息并适配LLM。为应对数据对齐挑战,我们开发了「Producer」**模块,利用LLM生成节点嵌入和文本描述的配对数据,并文本化节点信息。训练后,带有Translator的LLM能处理各种开放式任务。
方法
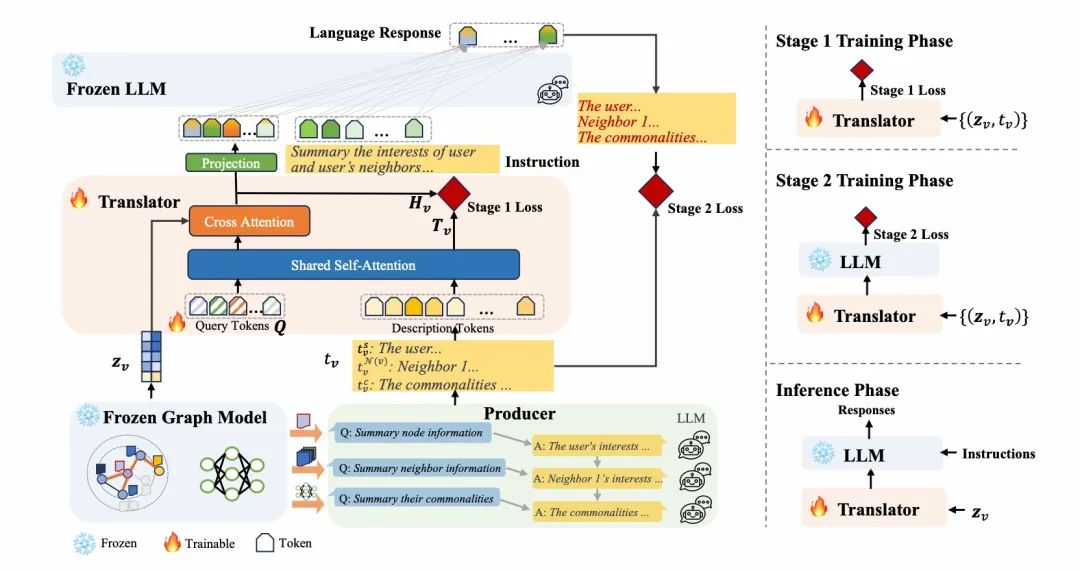
我们提出的GraphTranslator的主要目标是将图模型与LLM对齐,以便利用LLM的能力去执行开放式任务。具体而言,GraphTranslator由几个模块组成:
冻结的GM和LLM
- 给定一个TAG ,典型的图神经网络被表示为,其中是一组可学习的参数,是节点特征。以GraphSAGE[1]为例,通常情况下,GraphSAGE在目标节点周围采样一个固定大小的邻居,然后通过以下方式连接节点的前一层嵌入 与聚合的邻域向量: 最后,预训练的GM 编码了的局部图信息,并产生了节点嵌入。
- LLM在广泛的文本语料库上进行训练,获得大量的知识。我们使用了ChatGLM2-6B[2],这是一个开源的双语(Chinese-English)语言模型。
Producer模块
为了训练不同模态的数据与LLM进行对齐,需要高质量的对齐数据。例如,计算机视觉领域LLM需要{图像,描述文本},而图模型LLM则需{图表征,描述文本}。因此,我们设计了一个流程来引导LLM创建图节点描述,涵盖三个方面:
- 「节点信息文本」:总结节点属性并生成描述,反映节点嵌入中的信息。
- 「邻居信息文本」:采样一阶邻居节点,整合它们的信息以便总结。
- 「共性信息文本」:根据节点和邻居信息文本整合共性,推断节点间的相似性。
Translator模块
为解决GM与LLM之间的模态差异,我们引入了Translator模块将节点嵌入转换为token表示。受到BLIP2[3]的启发,我们采用两阶段训练方法逐步缩小Graph与LLM的差距。 第1阶段:训练Translator进行GM和文本的对齐。 我们提出了三个目标以对齐节点嵌入和节点文本描述:
- 对比目标:通过计算与之间的相似度,并选择最高得分来最大化二者的互信息。
- 生成目标:根据节点嵌入生成描述文本,并优化生成文本与实际节点描述之间的交叉熵损失,使得query tokens 能捕获更多与相关的细节。
- 匹配目标:细粒度对齐通过将每个节点嵌入与[CLS]标记拼接并输入二分类器来学习,计算所有查询的logits平均值作为匹配得分。
第2阶段:训练Translator进行GM和LLM的对齐。 我们使用线性层将Translator模块的输出,即token embedding ,投影到与LLM的词嵌入相同的维度。然后通过生成式学习,利用对齐数据对Translator参数进行调优。通过这种方式,节点嵌入可以与预训练的LLM词嵌入对齐。
实验
我们在真实世界的数据集上进行了实验,包括工业数据集淘宝和ArXiv数据集。
Zero-Shot实验性能比较
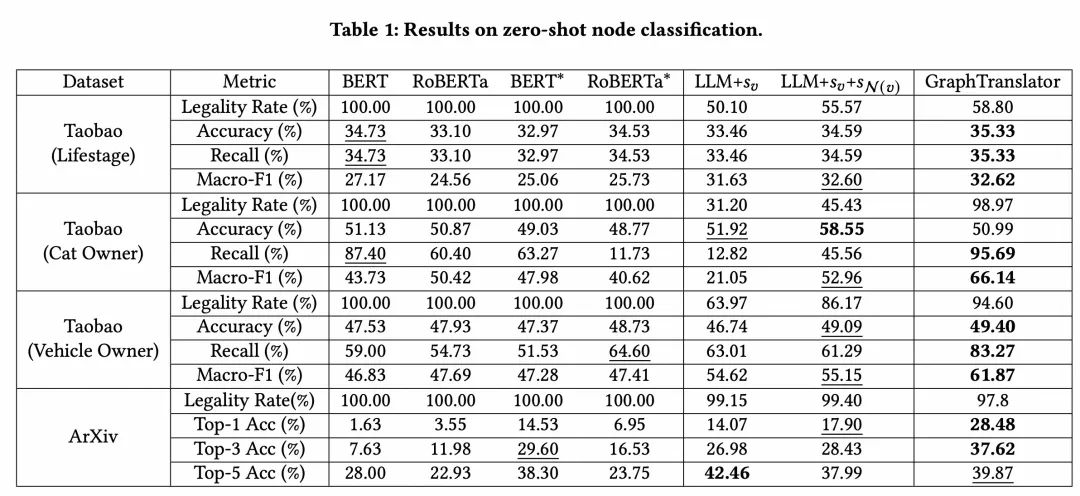
在Taobao和ArXiv的实验中,我们的GraphTranslator模型取得了优于大部分基准模型的性能,证明它有效地利用了LLM的能力。相较于基于BERT的方法,GraphTranslator更擅长处理需求复杂的zero-shot任务。相比直接使用LLM的方法,GraphTranslator通过将节点嵌入转换成软提示,减少了处理大量堆叠信息的噪声和复杂性,提升了性能。 我们的模型在LLM基础上提高了检出率,尤其在正例召回率方面有显著增长。GraphTranslator通过整合并压缩节点和邻居属性信息,提炼出Graph嵌入,使得LLM更容易理解和跟随指令,这在工业应用中非常重要。例如,在淘宝数据集上,GraphTranslator能够识别与“猫”相关的隐式产品,并将其显式总结为猫相关产品,从而更准确地识别正例。
消融实验
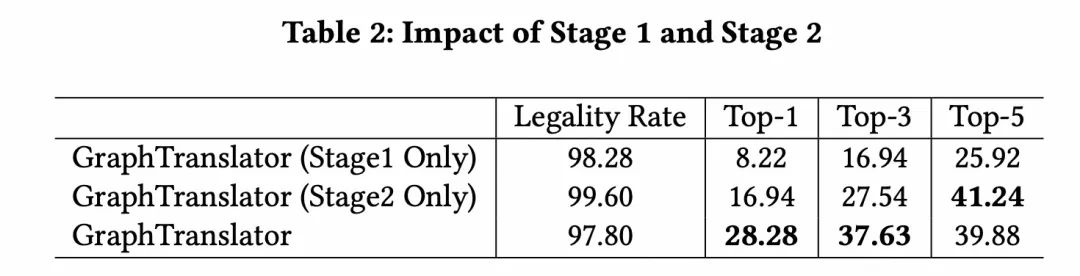
为验证我们的GraphTranslator训练策略,我们将其与只完成“阶段1训练”和“阶段2训练”的变体对比。结果表明,仅阶段1可以有效对齐图嵌入和文本,但未映射到LLM的语义空间,导致理解语义信息的能力不足。仅阶段2虽连接了图嵌入与LLM,但缺乏对节点嵌入和文本的深入理解,性能不理想。结合两阶段训练的GraphTranslator为LLM提供对图信息的全面理解,取得了最优结果。
GQA实验
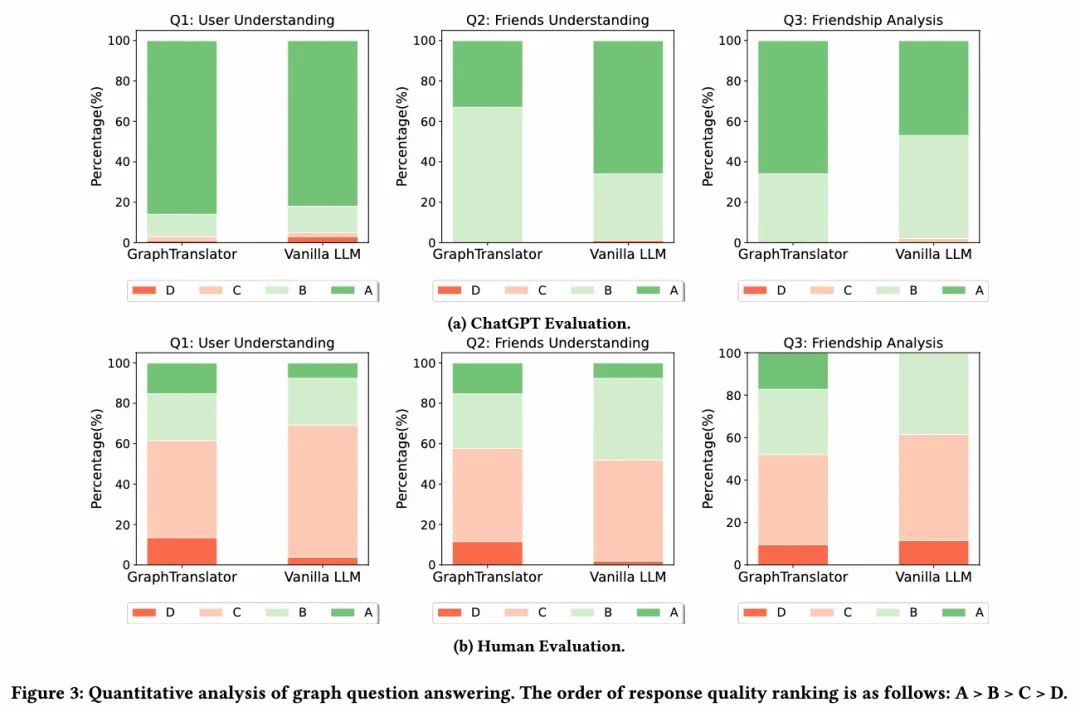
我们在淘宝数据集上进行了基于Graph的问答实验,以探索GraphTranslator在开放式应用中的潜力和商业价值。通过模拟多轮对话的LLM,测试了GraphTranslator在处理未知图节点表征的信息提取、理解和推理能力。为此,我们从100个图节点构建了一个评估集,并设计了三个问题:
- Q1:用户兴趣概述。
- Q2:朋友间共同兴趣汇总。
- Q3:分析用户之间的友谊原因。
GraphTranslator为第一个问题生成软提示,而将用户及其邻居的属性文本直接提供给ChatGLM2-6B进行比较。利用人类评估者和ChatGPT进行开放式问题的定量分析,我们采用四级评分系统来评价回答的准确性和相关性。
- 评分-A:答案正确简洁,信息正确,推理准确。
- 评分-B:答案是合理的,有小错误或不完美。
- 评分-C:答案与问题相关,但内容有明显错误或不准确。
- 评级-D:该回答不相关或完全无效。
观察比较结果显示,GraphTranslator在使用未知图节点嵌入作为LLM提示时,共获得了210个A级评分,超过了直接输入原始文本的Vanilla LLM的203个A级评分,显示出其优越性能。此成果得益于GraphTranslator根据Producer生成的低噪声文本进行训练,使其能从节点嵌入中提取高质量信息。特别是在解释朋友关系的问题3中,GraphTranslator展现了其在理解图谱和提取基于节点嵌入信息的能力,证明了其对图结构理解。
总结与展望
本文提出GraphTranslator框架,结合图模型(GM)与大型语言模型(LLM),通过Translator模块将节点嵌入转换成token,以消除模态差异并使GM能处理开放式任务。Producer模块将节点信息文本化以生成对齐数据,支持模型训练。我们在真实数据集上验证了GraphTranslator在zero-shot节点分类中的有效性,并展示了其在总结、理解和推理Graph信息方面的潜在商业价值。 尽管展示了GraphTranslator在开放式任务上的潜力,但未来还有一些方面可以继续探索:
- 首先,Producer在确定Translator质量中至关重要,可以考虑加入更多节点拓扑信息以减少信息丢失。若更大规模的LLM和新技术,如Chain-of-Thought,可能会提高模型性能。
- 实验中,zero-shot分类任务有标签进行定量分析,而GQA任务只通过案例展示性能。设计评估数据集和相应指标,对开放式任务(如图理解、解释和多轮对话)进行全面定量评估,对未来研究很重要。
[1] Hamilton W, Ying Z, Leskovec J. Inductive representation learning on large graphs[J]. Advances in neural information processing systems, 2017, 30. [2] https://github.com/THUDM/ChatGLM2-6B [3] Li J, Li D, Savarese S, et al. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models[C]//International conference on machine learning. PMLR, 2023: 19730-19742.

