

基础模型的崛起已经改变了机器学习研究,推动了揭示其内部机制的努力,并开发出更高效、更可靠的应用以实现更好的控制。尽管在解释大规模语言模型(LLMs)方面已取得显著进展,但多模态基础模型(MMFMs)——如对比视觉-语言模型、生成视觉-语言模型和文本到图像模型——在可解释性上提出了超越单模态框架的独特挑战。尽管已有初步研究,但LLMs与MMFMs的可解释性之间仍存在显著差距。本综述探索了两个关键方面:(1)将LLM可解释性方法适应到多模态模型;(2)理解单模态语言模型与跨模态系统之间的机制差异。通过系统回顾当前的MMFM分析技术,我们提出了一种结构化的可解释性方法分类法,比较了单模态与多模态架构中的洞察,并突出了关键的研究空白。

1. 引言
多模态基础模型(MMFMs)的快速发展与广泛应用——尤其是图像和文本模态的融合——已经推动了众多实际应用的实现。例如,文本到图像模型(Rombach等,2022;Ramesh等,2022;Podell等,2023)促进了图像生成和编辑,生成式视觉-语言模型(VLMs)(Zhu等,2023;Agrawal等,2024)支持视觉问答(VQA)或图像描述等任务,而对比(即非生成式)VLMs,如CLIP(Radford等,2021),则广泛用于图像检索。随着多模态模型的不断进步,人们对理解其内部机制和决策过程的需求也日益增加(Basu等,2024a)。机制可解释性不仅对解释模型行为至关重要,还对启用下游应用(如模型编辑(Basu等,2024a)、减少虚假相关(Balasubramanian等,2024)、以及提高组合泛化能力(Zarei等,2024))具有重要意义。 机器学习中的可解释性,LLMs和多模态模型的可解释性是一个广泛且依赖上下文的概念,因任务、目标和利益相关者需求的不同而有所变化。在本综述中,我们采用Murdoch等(2019)提出的定义:“提取并阐明模型所学习的相关知识、机制、特征和关系的过程,无论这些知识是编码在其参数中还是通过输入模式表现出来,从而解释模型是如何以及为什么生成输出的。”该定义强调了提取和理解模型知识,但“相关知识”的定义取决于应用的背景。例如,在记忆编辑应用中,可解释性使得可以精确地修改内部表示而不会干扰模型的其他功能;而在安全性场景中,它有助于突出信号对抗性输入的输入特征和激活。通过这种视角,本综述探讨了可解释性方法,研究它们如何揭示模型机制、促进实际应用并揭示关键的研究挑战。 尽管在单模态大规模语言模型(LLMs)(Meng等,2022a;Marks等,2024)方面,关于可解释性的研究取得了显著进展,但对MMFMs的研究仍然相对滞后。鉴于大多数多模态模型都是基于变换器(Transformer)的,出现了几个关键问题:LLM的可解释性方法能否适应多模态模型?如果能,它们是否能提供类似的见解?多模态模型与单模态语言模型在机制上是否存在根本的差异?此外,分析跨模态交互等多模态特有过程时,是否需要全新的方法?最后,我们还探讨了可解释性的实际影响,提出问题——多模态可解释性方法如何增强下游应用? 为了解答这些问题,我们进行了一项全面的综述,并引入了一个三维的多模态模型机制可解释性分类法:(1)模型家族——涵盖文本到图像扩散模型、生成式VLMs和非生成式VLMs;(2)可解释性技术——区分从单模态LLM研究中适应的技术与专门为多模态模型设计的方法;(3)应用——分类多模态机制见解增强的实际任务。 我们的综述综合了现有的研究,并揭示了以下见解:(i)基于LLM的可解释性方法可以通过适度调整扩展到MMFMs,特别是在将视觉和文本输入类似对待时。(ii)出现了新的多模态挑战,如如何将视觉嵌入转化为人类可理解的形式,这需要全新的专门分析方法。(iii)尽管可解释性有助于下游任务,但在多模态模型中,像幻觉缓解和模型编辑这样的应用相比语言模型仍然较为欠缺。这些发现可以为未来多模态机制可解释性研究提供指导。 最近,Dang等(2024)提供了一个关于MMFMs的可解释性方法的广泛概述,涵盖了数据、模型架构和训练范式。另一项并行工作(Sun等,2024)从历史视角回顾了多模态可解释性方法,涵盖了2000年至2025年的研究。尽管具有启发性,我们的工作在重点和范围上有所不同。具体来说,我们的工作考察了现有的LLM可解释性技术如何适应不同的多模态模型,分析了单模态和多模态系统在技术、应用和研究发现上的关键差异。 我们的贡献总结如下:
- 我们提供了一份关于多模态基础模型的机制可解释性的全面综述,涵盖了生成式VLMs、对比VLMs和文本到图像扩散模型。
- 我们引入了一个简单直观的分类法,有助于区分单模态和多模态基础模型中的机制方法、发现和应用,突出了关键的研究空白。
- 基于LLMs和多模态基础模型之间的机制差异,我们识别了多模态可解释性中的基本开放挑战和局限性,并为未来的研究提供了方向。
2. 分类法
在我们的综述中,我们提出了一个易于理解的分类法,用于从三个维度对机制可解释性技术进行分类:(i)维度1提供了对各种多模态模型家族的机制见解,包括非生成式VLMs(例如CLIP)、文本到图像模型(例如Stable-Diffusion)和多模态语言模型(例如LLaVa)。我们在第3节描述了本文研究的架构;(ii)维度2分类了技术是否用于语言模型(第4节)或是专门为多模态模型设计的(第5节);(iii)维度3将这些机制方法的见解与下游实际应用(第6节)相链接。分类法在图1中进行了可视化。特别是,见解和应用的分布与第4、5、6节相对应。 我们相信这种简单的分类将有助于读者:(i)理解语言模型与多模态模型在机制见解和应用方面的差距,以及(ii)识别机制可解释性(及其应用)尚未充分探索的多模态模型。 3 模型架构细节
在本节中,我们介绍了本综述涵盖的多模态模型的三个主要类别,包括(i)对比(即非生成)视觉-语言模型,(ii)生成视觉-语言模型,以及(iii)文本到图像扩散模型。我们选择这三个家族,因为它们涵盖了当前社区使用的大多数最先进的架构。 非生成视觉-语言模型 非生成视觉-语言模型(如CLIP,Radford等,2021;ALIGN,Jia等,2021;FILIP,Yao等,2021;SigCLIP,Zhai等,2023;DeCLIP,Li等,2022;LLIP,Lavoie等,2024)通常包含一个基于语言模型的文本编码器和一个基于视觉模型的视觉编码器。这些模型特别适用于现实世界的应用,如文本引导的图像检索、图像引导的文本检索和零样本图像分类。 文本到图像扩散模型 最先进的文本引导图像生成模型主要基于扩散目标(Rombach等,2022;Ho等,2020),该目标预测在前向扩散过程中添加的噪声,使其能够在反向扩散过程中逐渐将随机高斯噪声去噪为干净的图像。一个扩散模型通常包含一个文本编码器(如CLIP)和一个基于CNN的U-Net(Ronneberger等,2015)用于去噪以生成图像。具有此目标的早期文本到图像生成模型变体包括Stable-Diffusion-1(Rombach等,2022)(在压缩的潜在空间中执行扩散过程)和Dalle-2(Ramesh等,2022)(在图像空间中执行扩散过程,而不是在压缩的潜在空间中)。最近,SD-XL(Podell等,2023)通过使用更大的去噪UNet和改进的条件(如文本或图像)机制,改进了早期的Stable-Diffusion变体。最近的模型如Stable-Diffusion-3(Esser等,2024)通过(i)使用修正流公式,(ii)可扩展的Transformer架构作为扩散骨干,以及(iii)使用强大的文本编码器集合(如T5,Raffel等,2020;Chung等,2022),获得了比以前的Stable-Diffusion变体更强的图像生成结果。除了图像生成,文本到图像模型还可以应用于图像编辑(Hertz等,2022)和风格迁移(Zhang等,2023)。 生成视觉-语言模型 在我们的论文中,我们研究了最常见的生成VLMs,这些模型通过桥接模块将视觉编码器(如CLIP)连接到大型语言模型。这个桥接模块(如几个MLP层,Liu等,2023a;或Q-former,Li等,2023b)然后在大规模图像-文本对上进行训练。Frozen(Tsimpoukelli等,2021)是最早利用大型语言模型进行图像理解任务(如少样本学习)的工作之一。后续工作如MiniGpt(Zhu等,2023)、BLIP变体(Li等,2023b)和LLava(Liu等,2023a)通过修改训练数据的规模和类型以及底层架构,改进了Frozen。最近,许多工作集中在策划高质量图像-文本对,涵盖各种视觉-语言任务。Owen(Yang等,2024a)、Pixtral(Agrawal等,2024)和Molmo(Deitke等,2024)是一些最近的多模态语言模型,专注于高质量的图像-文本策划数据。多模态语言模型具有各种现实世界的应用,如VQA和图像字幕。 注意。我们承认能够同时进行图像生成和多模态理解的统一Transformer多模态模型的出现,如Xie等(2024a);Team(2024);Dong等(2024)。然而,由于缺乏对这些模型的机制可解释性研究,我们将它们排除在讨论之外。此外,另一种模型架构变体,旨在生成交错的图像和文本,如GILL(Koh等,2024),将MLLM和扩散模型结合到一个系统中。我们将根据其分析的组件对此类模型进行分类。
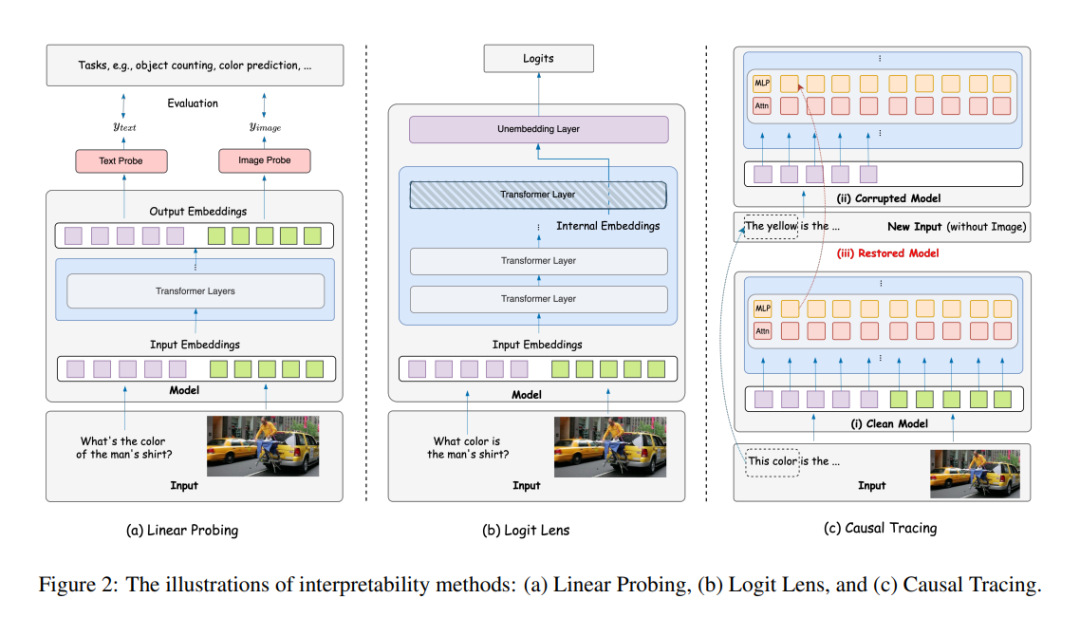
4 多模态模型的LLM可解释性方法
我们首先研究了最初为大型语言模型开发的机制可解释性方法及其对多模态模型的适应性,重点关注现有LLM可解释性技术如何为多模态模型提供有价值的机制见解。 具体来说,我们首先讨论诊断工具(线性探测,第4.1节;Logit Lens,第4.2节),这些工具被动地映射模型表示中编码的知识及其在层中的分布。然后,我们介绍因果干预方法(因果追踪和电路分析,第4.3节),这些方法主动扰动模型状态,以揭示知识存储的位置以及多模态模型中特定预测的产生方式。这些见解随后启发了以表示为中心的表示分解方法(第4.4节),通过数学方法将激活分解为可解释的组件,揭示模型知识的构建块。这种结构理解直接为行为控制范式提供了信息:通用任务向量(第4.5节)利用显式的任务驱动算术来编辑模型输出,而稀疏自编码器(作为其无监督对应物,第4.6节)提供了机器发现的特征基础,用于细粒度操作,将分析与应用联系起来。最后,神经元级描述(第4.7节)将这些解释锚定在经验现实中,通过微观激活模式(如概念特定神经元)验证宏观假设,并确保机制保真度。 线性探测
探测通过在冻结的LLM表示上训练轻量级分类器(通常是线性探测器)来评估它们是否编码语言属性,如语法、语义和事实知识(Hao等,2021;Liu等,2023b;Zhang等,2023a;Liu等,2023c;Beigi等,2024)。线性探测的图示如图2(a)所示。这种方法已扩展到多模态模型,引入了新的挑战,如解耦每个模态(即视觉或文本)的相对贡献。为了解决这些挑战,Salin等(2022)开发了探测方法,专门评估视觉-语言模型如何合成和合并视觉输入与文本数据以增强理解,而Dahlgren Lindstrom等(2020)研究了图像-字幕配对中视觉-语义嵌入中语言特征的处理。与LLMs中上层主要编码抽象语义(Jawahar等,2019;Tenney等,2019)不同,多模态探测研究(Tao等,2024;Salin等,2022)表明,多模态模型中的中间层更有效地捕捉全局跨模态交互,而上层通常强调局部细节或文本偏差。此外,尽管LLMs中的探测应用集中在特定语言分析上,但多模态模型中的探测范围扩展到更多样化的方面。例如,Dai等(2023)研究了视觉-语言模型中的对象幻觉,分析了图像编码如何影响文本生成准确性和令牌对齐。 主要发现和差距。线性探测的主要缺点是需要监督探测数据和训练单独的分类器来理解层中的概念编码。因此,通过多模态探测数据策划和训练跨不同多模态模型的单独分类器进行扩展是一个挑战。 Logit Lens
Logit Lens是一种无监督的可解释性方法,用于通过检查输出的logits值来理解LLMs的内部工作原理。如图2(b)所示,该方法进行逐层分析,通过使用解嵌入投影矩阵将中间表示投影到词汇空间,跟踪每层的logits,以观察预测如何在网络中演变。通过将中间表示解码为输出词汇上的分布,它揭示了网络在每个阶段的“思考”内容(Belrose等,2023)。在多模态模型的背景下,研究表明,与最终层相比,早期层的预测通常对误导性输入表现出更强的鲁棒性(Halawi等,2024)。研究还表明,异常输入会改变预测轨迹,使该方法成为异常检测的有用工具(Halawi等,2024;Belrose等,2023)。此外,对于简单示例——模型可以从初始层自信地预测结果的情况——正确答案通常出现在早期层,从而通过自适应早期退出实现计算效率(Schuster等,2022;Xin等,2020)。此外,Logit Lens已扩展到分析多个输入。Huo等(2024)将其应用于研究前馈网络(FFN)层中的神经元激活,识别专门用于不同领域的神经元以增强模型训练。进一步的研究整合了上下文嵌入以改进幻觉检测(Phukan等,2024;Zhao等,2024a)。此外,“注意力透镜”(Jiang等,2024b)引入了研究视觉信息处理的方法,揭示了幻觉令牌在关键层中表现出较弱的注意力模式。 主要发现和差距。除了多模态语言模型,logit-lens还可以潜在地用于机制性地理解现代模型,如统一理解和生成模型(Xie等,2024a;Team,2024)。 因果追踪
与被动诊断工具不同,因果追踪分析(Pearl,2014)植根于因果推理,研究在对中间变量(中介)进行主动干预后响应变量的变化。图2(c)展示了因果追踪应用于基于Transformer的生成VLM的示例。该方法已广泛应用于语言模型,以精确定位负责特定任务的网络组件——如FFN层。例如,Meng等(2022a)证明了LLMs中的中层MLPs对于事实回忆至关重要,而Stolfo等(2023)识别了数学推理的重要层。基于此技术并使用监督探测数据集,Basu等(2023)发现,与LLMs不同,视觉概念(如风格、受版权保护的对象)在扩散模型的噪声模型中分布在各个层中,但可以在条件文本编码器中定位。此外,Basu等(2024b)识别了编码艺术风格和一般事实等概念的关键交叉注意力层。最近的工作还将因果追踪扩展到机制性地理解生成VLMs的VQA任务(Basu等,2024a;Palit等,2023;Yu和Ananiadou,2024c),揭示了在VQA任务中指导模型决策的关键层。 扩展到电路分析。虽然因果追踪有助于识别特定任务的单个“因果”组件,但它不会自动导致提取模型的底层计算图的子图,该子图对任务具有“因果”性。在这方面,语言建模中有许多工作致力于提取任务特定电路(Syed等,2023;Wang等,2024a;Conmy等,2023a)。然而,将这些方法扩展到获取任务特定电路仍然是MMFMs的一个开放问题。 主要发现和差距。尽管因果追踪已广泛用于分析LLMs中的事实性和推理,但其在多模态模型中的应用仍然相对有限。将该方法扩展到更新、更复杂的多模态架构和多样化任务仍然是一个重要的挑战。 表示分解
在基于Transformer的LLMs中,如图3所示,表示分解的概念涉及分析模型的内部机制,特别是将单个Transformer层分解为核心有意义的组件,旨在理解Transformer的内部过程。在单模态LLMs中,研究主要将模型的架构和表示分解为两个主要组件:注意力机制和多层感知器(MLP)层。大量研究工作集中在分析这些组件,以了解它们对模型决策过程的个体贡献。研究发现,虽然注意力不应直接等同于解释(Pruthi等,2019;Jain和Wallace,2019;Wiegreffe和Pinter,2019),但它提供了对模型操作行为的重要见解,并有助于错误诊断和假设开发(Park等,2019;Voita等,2019;Vig,2019;Hoover等,2020;Vashishth等,2019)。此外,研究表明,Transformer MLP层中的前馈网络(FFNs)作为键值存储器,编码和检索事实和语义知识(Geva等,2021)。实验研究建立了FFN输出分布修改与后续令牌概率之间的直接相关性,表明模型的输出是通过每层的累积更新精心制作的(Geva等,2022a)。这一核心特性是识别与特定任务相关的语言模型电路的基础(Syed等,2023;Wang等,2024a;Conmy等,2023a)。 在多模态模型中,表示分解在分析模态处理和各层特定属性方面发挥了重要作用。Gandelsman等(2024a);Balasubramanian等(2024)利用监督探测数据集,提出了一种分层分解方法——跨越层、注意力头和令牌——以提供对模型行为的细粒度见解。
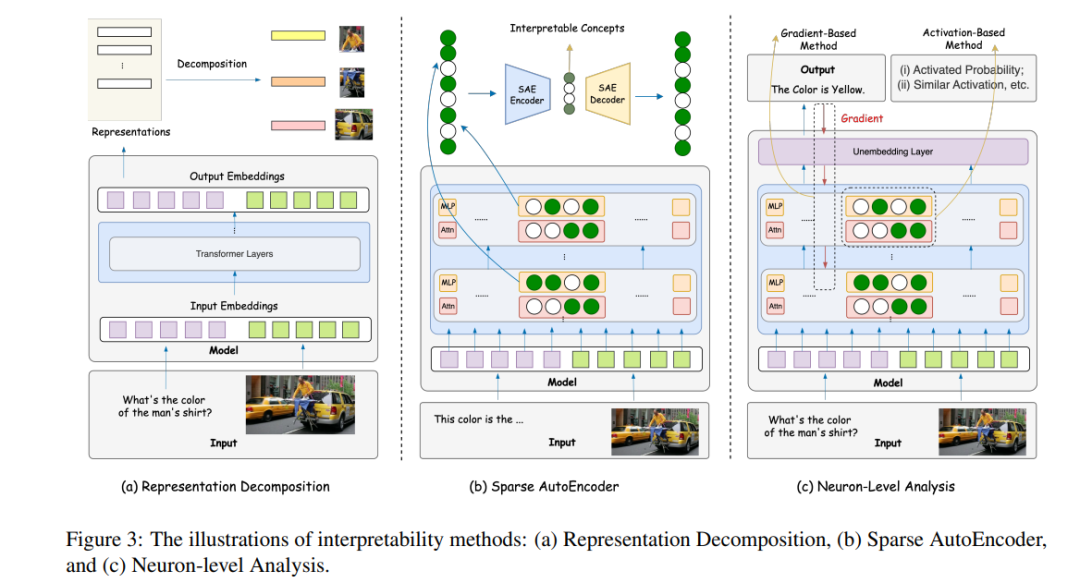
5. 专门针对多模态模型的可解释性方法
许多近期的研究提出了针对多模态模型的内部机制解释分析方法。与第4节中介绍的基于LLM(大型语言模型)的方法不同,这些方法仅为多模态基础模型设计和应用。这些方法包括:用于用人类可理解的语言注释嵌入或神经元的技术(第5.1节和第5.2节);利用跨注意力层等独特的多模态架构组件以获得更深层的见解(第5.3节);开发量身定制的多模态模型数据归因方法,例如文本到图像扩散模型(第5.4节);以及特定的可视化方法(第5.5节)。
6. 基于机制见解的多模态模型应用
在本节中,我们重点介绍受第4节和第5节中可解释性分析方法启发的下游应用。首先,我们在6.1节介绍上下文学习,接着是模型编辑(6.2节)和幻觉检测(6.3节)。然后,我们在6.4节总结了在多模态基础模型中提高安全性和隐私的应用,并在6.5节讨论了提高组合能力的应用。最后,我们在6.6节列出了其他几种应用类型。 7. 工具和基准
在LLMs领域,已有许多可解释性工具涵盖了注意力分析(Nanda 和 Bloom,2022;Fiotto-Kaufman等,2024)、SEA分析(Joseph Bloom 和 Chanin,2024)、电路发现(Conmy等,2023a)、因果追踪(Wu等,2024)、向量控制(Vogel,2024;Zou等,2023)、logit镜头(Belrose等,2023)和token重要性(Lundberg 和 Lee,2017)等。然而,针对MMFMs的可解释性工具较为狭窄。Yu和Ananiadou(2024d);Stan等(2024)主要聚焦于生成式VLMs中的注意力机制。Aflalo等(2022)提出了一种工具,用于可视化生成式VLMs的注意力和隐藏状态。Joseph(2023)提出了一种针对视觉变换器(Vision Transformers)的工具,主要集中于注意力图、激活补丁和logit镜头。此外,对于扩散模型,Lages(2022)提供了一种可视化生成图像过程中的内部扩散步骤的工具。 统一的可解释性基准也是一个非常重要的研究方向。在LLMs中,Huang等(2024b)提出了一个基准,用于评估可解释性方法在解耦LLMs表示方面的效果。Thurnherr和Scheurer(2024)提出了一种新方法,用于生成LLMs的可解释性测试平台,节省了手动设计实验数据的时间。Nauta等(2023);Schwettmann等(2024)也提供了LLMs可解释性的基准。然而,目前尚未有针对多模态模型的基准,这是未来的重要研究方向。 总体来说,与LLMs领域中的全面工具和基准相比,多模态基础模型的工具和基准相对较少。提供一个全面、统一的评估基准和工具是未来的研究方向。
8. 主要开放挑战
尽管机制可解释性是语言模型中一个成熟且广泛的研究领域,但对于多模态模型而言,它仍处于早期阶段。本节总结了该领域中的关键开放挑战,重点关注利用机制见解的下游应用。这些挑战包括解释扩散变换器(Diffusion Transformers)的内部层次,用于诸如模型编辑等任务;将机制见解扩展到超出视觉问答(VQA)或简单图像生成的任务;开发多模态模型的顺序批次模型编辑技术——包括扩散模型和多模态语言模型;探索稀疏自编码器及其变体在控制和引导多模态模型中的有效性;设计基于机制见解的透明数据归因方法;以及通过更深的机制理解改进多模态上下文学习。此外,扩展机制可解释性技术以分析统一的视觉-文本理解和生成模型(例如Xie等,2024a)也是一个开放的研究方向。
9. 结论
我们的综述回顾了多模态基础模型(MMFMs)中的机制理解方法,包括对比性VLMs、生成式VLMs和文本到图像扩散模型,重点关注下游应用。我们引入了一种新颖的分类法,区分了从语言模型适应过来的可解释性方法和为多模态模型设计的可解释性方法。此外,我们还比较了语言模型和多模态模型的机制见解,识别了理解上的差距及其对下游应用的影响。