随着大型语言模型(LLMs)的快速发展,使策略模型与人类偏好保持一致变得愈发重要。直接偏好优化(DPO)作为一种不依赖强化学习(RL)的替代方法,逐渐成为对齐的有前途的途径,替代了基于人类反馈的强化学习(RLHF)。尽管 DPO 在多方面取得了进展,并且其内在的局限性也备受关注,但目前文献中尚缺乏对这些方面的深入综述。在这项工作中,我们对 DPO 的挑战和机遇进行了全面回顾,涵盖了理论分析、变体、相关偏好数据集和应用。具体而言,我们根据关键研究问题对近期的 DPO 研究进行了分类,以全面了解 DPO 的现状。此外,我们提出了多个未来研究方向,以为研究社区提供有关模型对齐的见解。
1 引言
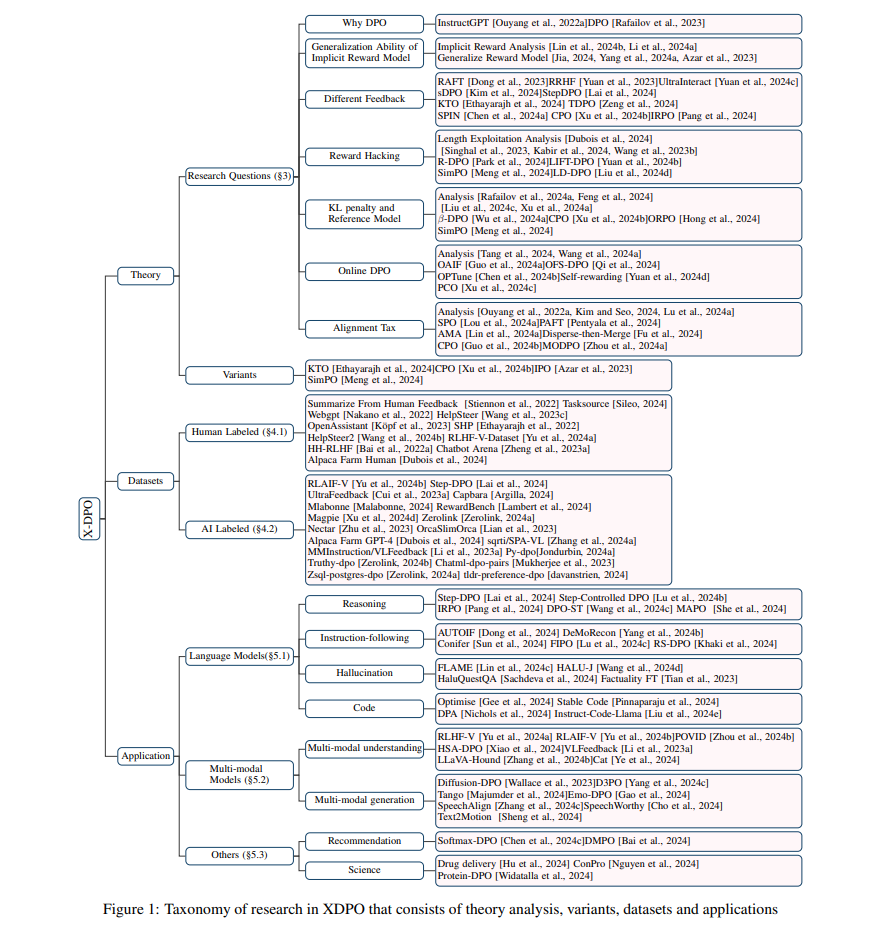
通过使用预测下一个词的目标,基于大规模、高质量语料库进行预训练,耗费大量计算资源,大型语言模型(LLMs)[OpenAI, 2022; Touvron等, 2023a; OpenAI, 2024a; Jiang等, 2023]将广泛的世界知识内化于其内部参数中,展现了令人印象深刻的语言理解和生成能力。此外,LLMs 已经扩展到支持多模态输入,包括语言和视觉,从而催生了大型视觉语言模型(LVLMs)[OpenAI, 2023a; Liu等, 2024a; Team等, 2023; Bai等, 2023]。这些基础模型作为通用解决方案,在广泛的语言和视觉语言任务中表现优异,标志着向人工通用智能(AGI)迈出了重要的一步。 随着这些基础模型规模的扩大和性能的提升,它们仍然难以完全遵循用户的指令(显式目标)并实现“有帮助、诚实、无害”(隐式目标),这归因于预训练阶段使用的下一个词预测任务的目标不完全对齐[Leike等, 2018; Askell等, 2021; OpenAI, 2023b]。因此,在典型的后训练阶段,会进行偏好优化(例如,从人类反馈中进行强化学习,RLHF),在响应级别上对预训练的语言模型进行对齐,以确保它们与用户的意图保持一致,并且保持有帮助、诚实和无害[Ouyang等, 2022a; Dai等, 2024; Sun等, 2023]。RLHF 首先在收集的人工偏好数据上训练显式奖励模型。随后,RLHF使用强化学习算法(例如,近端策略优化(PPO; Schulman等, 2017a])微调策略模型(即目标微调的LLM),以生成能够最大化由奖励模型评分的响应奖励的响应,但不偏离参考模型太远,受KL散度约束。然而,RLHF需要精心调整超参数和大量计算资源来维持强化学习训练的稳定性。此外,一些研究还指出与此显式奖励建模相关的一些挑战,例如奖励滥用[Casper等, 2023]、奖励错误指定[Pan等, 2022]和分布外泛化问题[Tien等, 2023]。 为了避免上述RLHF的限制,提出了多种不依赖强化学习的偏好优化方法。Yuan等[2023]、Dong等[2023]、Liu等[2024b]、Song等[2024]提出从策略模型中采样多个响应,并使用经过良好训练的奖励模型进行评分。然后,在没有使用强化学习算法的情况下,直接在最优的响应(称为拒绝采样)或通过应用排序损失微调策略模型。另一方面,从RL中带有KL约束的奖励最大化目标出发,直接偏好优化(DPO; Rafailov等, 2023)推导出其学习目标,特别是基于离线偏好数据的简单最大似然目标,直接在策略模型和参考模型上进行建模,从而绕过了显式奖励模型训练阶段,并消除了强化学习优化的需要。实际上,DPO的优化目标等同于Bradley-Terry模型[Bradley和Terry, 1952a],其中隐式奖励函数由策略模型本身参数化。与RLHF相比,DPO在多种应用中表现出稳定、高效且计算轻量的优势[Rafailov等, 2023; Ethayarajh等, 2024; Ivison等, 2024]。 最近的一些研究表明,尽管避免了计算成本高昂的强化学习,DPO仍然面临一些重大挑战。例如,DPO中的隐式奖励建模可能导致偏向分布外响应的策略[Xu等, 2024a; Saeidi等, 2024],离线DPO在经验上不如在线对齐方法[Ivison等, 2024],经过对齐的模型可能会经历所谓的“对齐成本”[Lin等, 2024a; Lu等, 2024a]。因此,近期提出了多种改进版的DPO,包括KTO[Ethayarajh等, 2024]、IPO[Azar等, 2023]、CPO[Xu等, 2024b]、ORPO[Hong等, 2024]、simPO[Meng等, 2024],以及其他方法[Lu等, 2024b; Xiao等, 2024; Zeng等, 2024]。随着DPO的快速发展,迫切需要一篇综合性综述,帮助研究人员识别该领域中的新兴趋势和挑战。我们观察到一些关于LLM对齐的同时进行的研究与我们的工作相关[Ji等, 2023; Wang等, 2023a; Shen等, 2023]。然而,现有的综述文章主要关注LLMs的整体对齐,包括指令微调和RLHF。它们涉及DPO的部分不足以捕捉这一领域当前快速发展的态势。此外,这些综述往往关注于语言模型的对齐,未能提供对DPO特定的应用和数据集的深入介绍。 为了弥补这一空白,我们在本文中对DPO的最新进展进行了全面综述,涵盖了相关的偏好数据集、理论分析、变体和应用。具体而言,我们根据以下研究问题对当前的DPO研究进行分类:
- 隐式奖励建模的效果。DPO通过建立从奖励函数到最优策略的直接映射,避免了训练显式奖励模型。因此,研究人员已经研究了DPO中隐式奖励建模的泛化能力[Lin等, 2024b; Li等, 2024a; Yang等, 2024a; Jia, 2024]。
- KL惩罚系数与参考模型的影响。RL和DPO的优化目标都涉及KL散度正则化,它限制了策略模型保持在参考模型的特定范围内。因此,最近的一些研究探讨了KL惩罚系数和参考模型选择的影响[Liu等, 2024c; Xu等, 2024a; Feng等, 2024; Rafailov等, 2024a]。
- 不同反馈的效果。DPO使用点对点奖励和成对偏好数据提供奖励信号。然而,获得高质量的成对偏好数据既昂贵又耗时,影响了可扩展性。此外,实例级优化可能未充分利用偏好数据的潜力。因此,一些研究使用其他形式的反馈(例如,列表级、二元、分步、词级等)作为优化的奖励信号[Dong等, 2023; Yuan等, 2023; Ethayarajh等, 2024; Zeng等, 2024; Chen等, 2024a; Xu等, 2024b]。
- 在线DPO。与在线RLHF相比,DPO利用预收集的偏好数据,属于离线偏好优化方法。一些研究强调了在线和离线算法之间的性能差距[Tang等, 2024; Wang等, 2024a]。为了解决这一问题,最近的研究探索了DPO的迭代和在线变体,以及有效收集新偏好数据集的策略[Xu等, 2024c; Guo等, 2024a; Yuan等, 2024a; Chen等, 2024b]。
- 奖励滥用。奖励滥用是强化学习中的一个长期问题,其中策略获得高奖励,但未能实现实际目标[Dubois等, 2024; Singhal等, 2023]。近期研究发现,无论是RLHF还是DPO,奖励滥用都普遍存在,策略利用潜在的捷径(例如响应长度和风格)开发特定的响应模式以“欺骗”奖励模型[Kabir等, 2024; Wang等, 2023b; Park等, 2024]。为克服这一限制,提出了一些方法以避免此类弱点被利用[Park等, 2024; Yuan等, 2024b; Meng等, 2024; Liu等, 2024d]。
- 对齐成本。偏好优化的目标是使模型与人类偏好保持一致。然而,先前的研究发现了所谓的“对齐成本”现象,即在对齐目标上的改进可能导致与基线模型相比的性能下降[Ouyang等, 2022a]。因此,一些研究调查了对齐成本并提出了减少其影响的方法[Lin等, 2024a; Lou等, 2024a; Guo等, 2024b]。
我们希望这篇综述能够帮助研究人员抓住该领域中的新趋势和挑战,探索DPO在对齐LLMs和多模态LLMs(MLLMs)中的潜力,并为构建更具可扩展性和普适性的DPO做出贡献。具体而言,我们认为未来的研究应优先开发更先进的DPO变体,这些变体能够:(i)超越实例级反馈,捕捉更细粒度和准确的奖励;(ii)通过数据、学习目标和奖励展示出与在线RLHF相比具有竞争力或更强的泛化能力;并且(iii)促进复杂应用的发展,如深度推理系统(例如OpenAI o1 [OpenAI, 2024b])、混合模态模型(例如Chameleon [Team, 2024])。 本文其余部分的组织结构如下。(§ 2)介绍了RLHF和DPO的背景知识。(§ 3)介绍了DPO的研究问题和不同变体。DPO使用的数据集和应用分别在(§ 4)和(§ 5)中介绍。(§ 6)讨论了DPO的机遇和挑战。最后在(§ 7)中给出了简短的结论。