大语言模型(Large Language Models, LLMs)已经在广泛的任务中展现出强大的泛化能力。推理是 LLMs 解决多步问题和复杂决策的核心。为了支持高效推理,近期研究的关注点正从显式的“链式思维”(chain-of-thought, CoT)提示转向隐式推理,即推理过程在潜在结构中静默展开,而无需输出中间的文本化步骤。隐式推理的优势在于:更低的生成成本、更快的推理速度,以及与模型内部计算更好地对齐。尽管已有综述在推理背景下讨论过潜在表示,但对于推理在 LLM 内部如何展开的专门化、机制层面的梳理仍然缺失。本文旨在填补这一空白,通过引入一个以执行范式为中心的分类体系,将关注点从表示形式转向计算策略。我们将现有方法归纳为三类执行范式,依据其内部计算展开的方式与位置进行划分:潜在优化(latent optimization)、信号引导控制(signal-guided control)、以及层递归执行(layer-recurrent execution)。此外,我们还回顾了支持 LLM 隐式推理存在性的多种证据,包括结构层面、行为层面和表示层面的实证结果。最后,我们系统总结了已有工作在评估隐式推理有效性与可靠性时所使用的指标与基准。我们维护了一个持续更新的项目主页:https://github.com/digailab/awesome-llm-implicit-reasoning。
1 引言
近年来,大语言模型(Large Language Models, LLMs)(Touvron et al., 2023a; Li et al., 2023b; Javaheripi et al., 2023; Abdin et al., 2024; Grattafiori et al., 2024; Hurst et al., 2024; Contributors et al., 2024; Yang et al., 2024a;b; 2025a; Guo et al., 2025; OpenAI, 2025; DeepSeek-AI, 2025) 在广泛的任务中取得了显著进展 (Liu et al., 2025a),涵盖对话生成 (Yi et al., 2024)、推荐系统 (Wang et al., 2024b)、医疗健康 (Qiu et al., 2024)、金融 (Li et al., 2023a)、推理时计算 (test-time compute) (Li, 2025)、表格数据 (Fang et al., 2025b) 以及科学推理 (Yan et al., 2025) 等多个领域,这得益于其庞大的参数规模和大规模训练数据。然而,研究表明,仅仅依赖参数规模的线性增长并不足以解释所有性能提升。在推理过程中,推理时扩展(Test-Time Scaling, TTS)(Zhang et al., 2025b) 揭示了模型的“动态计算”能力,即在推理时投入额外的计算资源以实现更深入的理解与推理。典型的例子包括 o1 (Contributors et al., 2024) 和 DeepSeek R1 (Guo et al., 2025),这类推理模型展现出强大的性能。
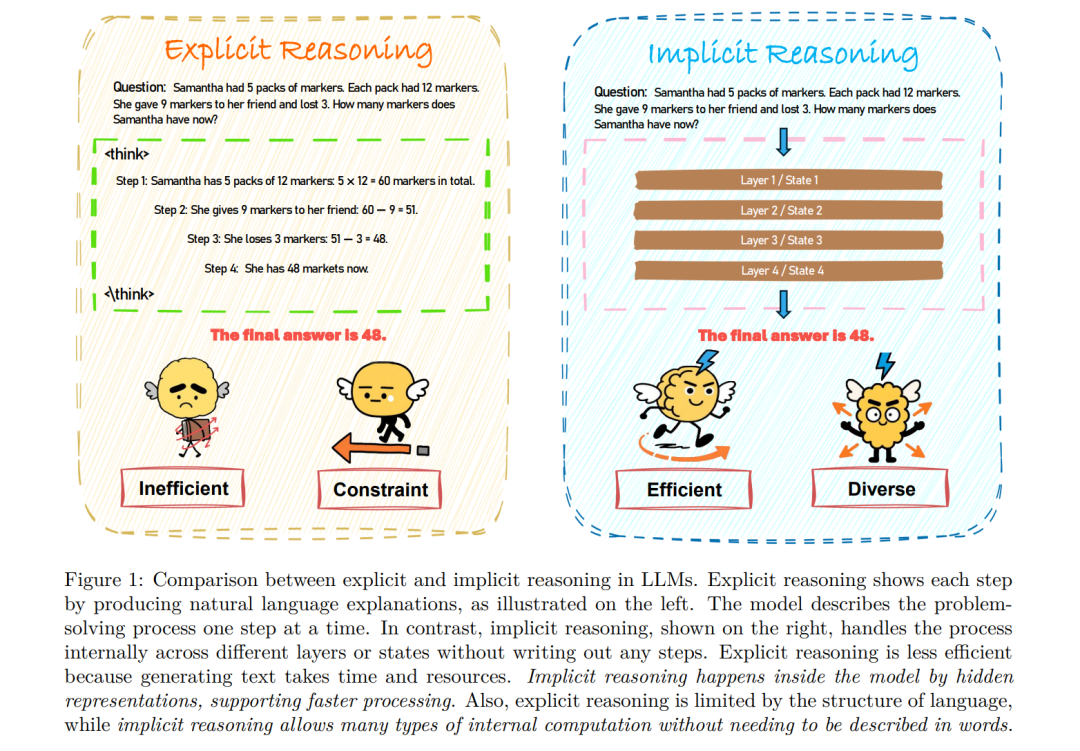
近年来的大多数推理模型依赖于显式的链式思维(Chain-of-Thought, CoT)(Wei et al., 2022)。在这一范式下,模型首先以自然语言“说出”一系列连贯的中间推理步骤 (Sun et al., 2023),然后给出最终答案,从而显著提升复杂问题的准确性。尽管显式推理可以提升可解释性和深度,但它常常导致序列过长,其中包含冗余、无关或不必要的步骤 (Hong et al., 2025),在实际应用中造成计算资源浪费,并增加延迟与成本 (Yue et al., 2025a),如图 1 所示。为此,研究界开始探索如何在保持深度推理能力的同时,提高推理效率,减少“过度思考”的负担 (Sui et al., 2025)。
为应对上述问题,近期研究提出了隐式推理(implicit reasoning)的概念 (Ye et al., 2025a),即在不生成显式推理轨迹的情况下完成多步推理。与显式方法不同,隐式推理通过内部计算来完成,例如基于 token 级 (Tack et al., 2025; Sun et al., 2025)、轨迹级 (Cheng & Van Durme, 2024; Hao et al., 2024)、内部状态级的潜在表示精化 (Deng et al., 2023; Kong et al., 2025),或信号引导控制 (Herel & Mikolov, 2024; Goyal et al., 2024; Pfau et al., 2024; Wang et al., 2024c) 等方式。这种“静默”的推理形式降低了表层复杂性,更符合推理在模型内部展开的方式。尽管这一方向受到越来越多关注,但隐式推理仍然缺乏系统性的理解。
LLM 隐式推理打破了在推理过程中每一步都必须输出 token 的限制,而是在模型的连续表示空间中直接完成推理。这种方法无需将每一步转化为自然语言 token(见图 1),从而避免了多次自回归生成的计算和序列化瓶颈,并可在模型内部以并行方式更高效地展开推理。通过利用潜在嵌入与神经网络层等更高效的内部结构,隐式推理不仅能够更好地利用资源 (Hao et al., 2024; Zhang et al., 2025a),还可以探索更多样化的推理路径 (Xu et al., 2025a; Gozeten et al., 2025),不再受限于解码过程。
然而,尽管兴趣不断增长,现有关于隐式推理的研究仍然零散。已有工作涉及潜在状态建模、紧凑推理轨迹、基于循环的计算以及推理时控制等多个方向,但缺乏统一的概念框架。已有若干综述探讨了更广泛的 LLM 推理 (Ahn et al., 2024; Zhou et al., 2025; Chen et al., 2025a; Li et al., 2025b),但大多集中于显式范式 (Qu et al., 2025; Liu et al., 2025b; Feng et al., 2025; Wang et al., 2025b; Sui et al., 2025),例如 CoT 提示或符号推理,对隐式推理的覆盖不足。少数近期综述涉及潜在形式的推理 (Chen et al., 2025b; Zhu et al., 2025b),但其研究范围与本文差异较大。例如,Chen et al. (2025b) 从 token 级策略、内部机制、分析方法和应用四个角度进行梳理,强调如何将链式思维推理重新编码为潜在形式;而 Zhu et al. (2025b) 则从机制视角出发,关注架构递归、时间隐藏状态和逐层可解释性。 为整合零散的研究并澄清这一新兴范式,本文从功能视角出发,对 LLM 隐式推理进行系统性综述。我们按照内部计算展开的方式与位置对现有方法进行组织,提出了一个由三类执行范式组成的分类体系(§3):潜在优化(latent optimization, §3.1)、信号引导控制(signal-guided control, §3.2)以及层递归执行(layer-recurrent execution, §3.3)。除了方法分类之外,我们还分析了支持隐式推理存在性的证据,包括结构层面、行为层面和表示层面的实证分析 (§4)。此外,我们还系统梳理了现有文献中常用的评估指标和基准 (§5),这一方面在以往综述中基本被忽视。通过建立一个连贯的框架,本文旨在统一分散的研究成果,并推动未来在高效、可控、具备认知基础的推理方向上开展进一步探索,同时识别关键挑战并展望有前景的研究方向 (§6)。
本文的主要贡献可总结如下: * 执行视角分类体系:为系统刻画 LLM 隐式推理,我们引入一个功能视角,强调内部计算的展开方式与位置。基于这一视角,我们提出了一个以执行为中心的分类体系,包括三类范式:潜在优化、信号引导控制与层递归执行,并根据推理粒度与控制机制进一步细化子类。 * 隐式推理证据整合:我们并行探讨了隐式推理的实证证据,综合了结构分析、行为特征和基于表示的分析方法,为执行中心分类体系提供经验支撑。 * 系统化评估综述:我们系统回顾了隐式推理研究中常用的评估协议与基准,并指出推进该领域的紧迫挑战,同时展望未来方向,以构建更高效、鲁棒、可解释且与认知对齐的推理系统。