

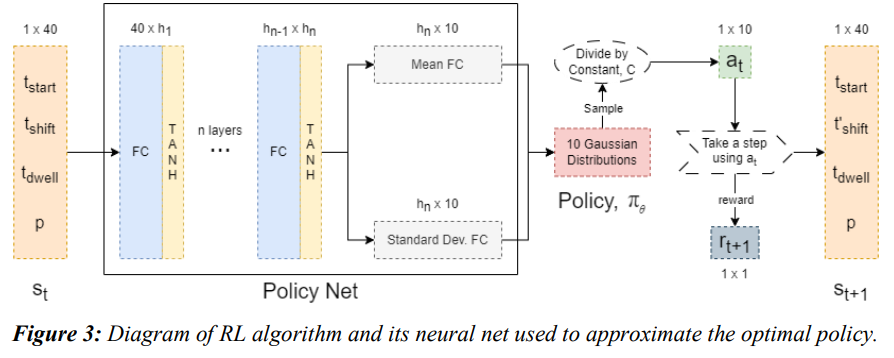
研究了一种雷达任务调度的强化学习(RL)方法,以提高性能成本,同时节省运行时间。雷达任务调度问题被转换为 RL 环境,其中观察空间是雷达任务参数,行动空间是在时间窗口内移动每个任务的值。这种环境中的一个事件与任务序列开始时间的随机移动非常相似。使用了基本的 RL 算法来训练每个任务应向哪个方向移动多少的策略。在 10 个任务序列中使用这种方法,发现成本明显优于最早开始时间(EST)。不过,与其他方法相比,这种方法的执行速度较慢。要改进这一模型,可以创造更好的环境以减少不必要的移动次数,也可以使用不同的模型/算法来代替所使用的基本 RL 算法,还可以调整超参数以提高不同任务序列之间的通用性。
认知雷达使用基于人工智能(AI)/机器学习(ML)的技术,这样雷达就能根据不断变化的环境进行自我调整。所提出的强化学习(RL)算法创新性地将机器学习融入雷达调度,为现实世界中的雷达调度问题提供了成本更低的解决方案。

成为VIP会员查看完整内容
相关内容

Arxiv
224+阅读 · 2023年4月7日



相关VIP内容
相关资讯
相关论文
Arxiv
224+阅读 · 2023年4月7日