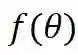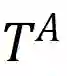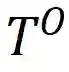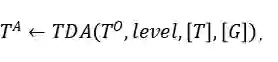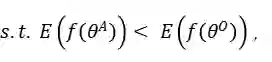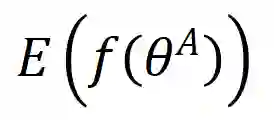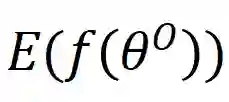面向表格数据的机器学习在多个领域如金融、医疗和教育中广泛应用,但获取大量高质量表格数据仍是一大挑战。表格数据的采集过程资源密集且耗时,且受隐私限制,数据可用性受限。因此,许多研究致力于表格数据增强(TDA),通过生成额外数据来提升模型训练效果。
本次为大家带来浙大数据智能团队最新综述:《生成式AI时代下表格数据增强的进展与展望》。本文回顾了2010年至2024年间70篇重要研究,综述了TDA的技术流程和最新发展。特别是在2023至2024年间,生成式AI技术的加入为TDA带来新的发展机遇。文章构建了一个包括预增强、增强和后增强三个阶段的端到端TDA流程,并系统分析了基于检索和基于生成的增强技术。最后文章总结了TDA的当前趋势和未来方向,并将继续在SuDIS-ZJU的GitHub页面更新相关资源。 论文链接: https://arxiv.org/abs/2407.21523 Git库: https://github.com/SuDIS-ZJU/awesome-tabular-data-augmentation/
0. 摘要
面向表格数据(tabular data)的机器学习(ML)无处不在,在金融、医疗、教育等领域广泛使用。但获取大量高质量的表格数据用于模型训练仍然是一个重大障碍。单表大小适中且独立,使得整个数据收集过程资源密集且耗时。表格数据是大语言模型(LLMs)使用的重要格式之一,现有高质量数据集即将耗尽。同时,表格数据多用于工业界,受隐私限制数据可用性有限。
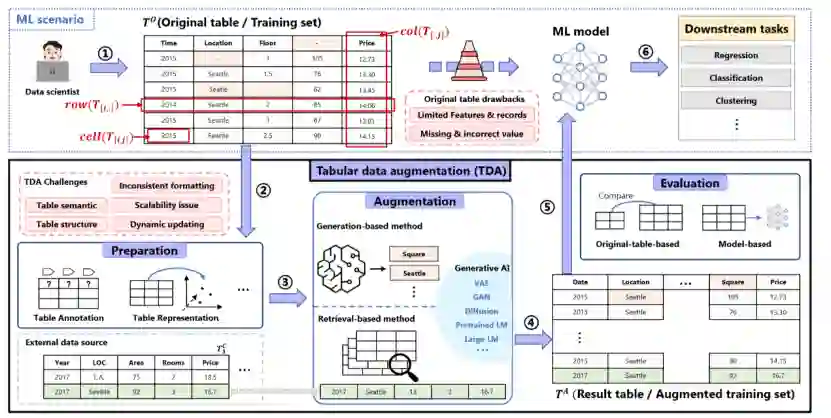
因此,大量工作都致力于研究表格数据增强(tabular data augmentation,TDA)这一任务,用额外的数据增强原始表格,从而促进下游的机器学习任务。图1展示了面向ML的TDA示例,直接使用原表训练ML模型很可能效果欠佳,因此需要进行表增强提升数据质量,表增强主要分成三个步骤:增强准备,增强(基于检索和基于生成),增强后评估。本文选取了从2010年到2024年间发表在重要刊物上的70篇工作,以对TDA的整个技术环节进行详细的论述。此外,近年来生成式人工智能(generative AI)也开始进军于TDA领域(23-24年出现了16篇相关文章)。本文的目的,是全面地回顾和展望TDA的进展和未来前景,同时特别强调当前生成式人工智能在这一领域的发展态势。
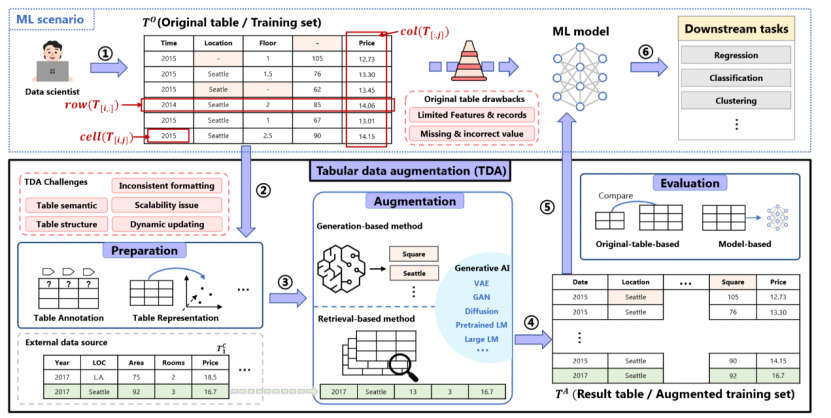
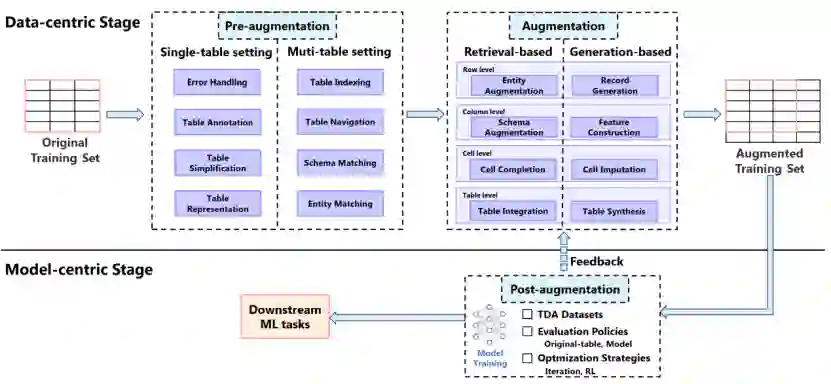
图1. 面向ML的TDA工作示例:① 一位数据研究员的目标是预测房价。由于原始训练集数据不足和大量缺失或错误的值,初始ML模型产生了次优结果。为了提高性能,数据研究员决定使用表增强提高数据质量,用额外的属性(列)、记录(行)和校正值(单元格)增强原表。②在增强之前,准备步骤,如表注释(例如,恢复原表中第4列的缺失列名),以提高TDA过程的有效性。③增强过程可以通过基于检索的方法(例如,从外部数据源检索到表中的第二行)或基于生成的方法来合成新数据。④增强表结合了原始数据和新数据。⑤增强后,通过评估评估TDA过程的有效性。⑥最后,TDA过程生成的增强表使科学家能够训练出更准确的房价预测模型。 具体来说,本文构建了端到端的TDA流程,包括三个主要过程:预增强(pre-augmentation)、增强(augmentation)和后增强(post-augmentation),如图2所示。预增强部分总结了常用的促进后续TDA的准备任务,包括错误处理(Error Handling)、表注释(Table Annotation)、表简化(Table Simplification)、表表示(Table Representation)、表索引(Table Indexing)、表导航(Table Navigation)、模式匹配(Schema Matching)和实体匹配(Entity Matching)。增强部分系统地分析了当前的TDA技术,分为基于检索(retrieval-based)和基于生成(generation-based)的方法,前者检索外部数据,后者生成合成数据。本文根据增强过程的执行粒度(行、列、单元格和表)进一步细分这些技术。后增强部分侧重于TDA的数据集、评估和优化。本文还总结了TDA的当前趋势和未来方向,强调了生成人工智能时代TDA的前景和机会。此外,随附的论文和相关资源将在https://github.com/SuDIS-ZJU/awesome-tabular-data-augmentation/中不断更新和维护。
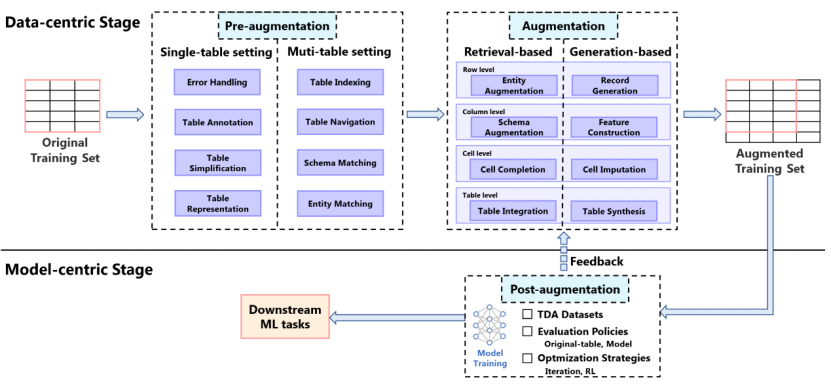
图2. TDA流程图 **
**
1. 引言
1.1 TDA综述的必要性
1)表格数据在机器学习中应用广泛:表格数据,如关系表(relational tables)、网页表(web tables)和CSV文件等,是机器学习中最原始和最基本的数据形式之一,具有出色的结构特性、可读性和可解释性。谷歌数据集搜索平台上超过65%的数据集是表格文件。这种普遍性突显了它在无数领域的关键作用,如金融、医疗、教育。 2)适用于ML的高质量表格数据稀缺:单表一般大小适中且独立于其他表,这使得整个数据收集过程资源密集且耗时。在大型语言模型(LLM)时代,表格数据是LLM使用的重要数据格式之一,现有的高质量表格数据集可能很快就会耗尽。此外,表格数据作为工业界最常用的数据,由于隐私问题,数据的可用性往往受到限制。 3)当前暂无工作对现有的TDA技术进行系统地整理分析:目前TDA领域的研究工作数量众多(从2010年到2024年,本文共收集了70项高度相关的研究),且随着生成式AI的发展,不断有新技术引入(从2023年到2024年,本文共收集了16篇使用生成式AI的工作)。 1.2 TDA的挑战
- 表格的异质性,与图像、文本等同质数据不同,表格数据是异质的,通常同时包含连续型和离散型特征;
- 复杂的结构性,如行列的顺序无关性,表格的层次性(单元格属于行,行属于表),列与列之间的关系(表中的某一列通常仅依赖于其他列的子集);
- 表格的语义信息,表格通常具有一个主题(如Year列在电子产品信息表和在论文发表年份表中的意义不一致);
- 表池中表格数量庞大,有时包含数百万张表格;
- 多表间不一致的形式,池中表由于不同来源等因素,通常具有不一致的属性命名习惯和单元值格式;
- 表池本身的动态性,池中表随着时间的推移而变化。 1.3 本文的贡献:
1)首个关于TDA技术的综述,从任务和表粒度两个视角对现有的70篇经典TDA工作进行分类。首先将TDA技术分为基于检索和基于生成的方法,再基于表粒度(行、列、单元格和表)细分,共形成8个具体的TDA任务,如图2。并对这8个任务进行进一步地分类比较,总结出现有方法的优缺点及未来方向。同时,比较基于检索和基于生成的方法,突出其各自的优缺点。
2)本文提供了一个完整的TDA流程,涵盖了从准备到增强再到评估的整个过程,如图2。本文总结了8个常用的预增强任务,对这些预增强任务进行具体分析,形成分类和优缺点比较。并逐个分析了现有的70篇经典TDA工作都使用了哪些预增强任务,进而总结了这些预增强任务的适用场景。后增强阶段,本文整理了常用的TDA数据集,TDA评估方法以及TDA优化策略。 3)本文特别关注最新的生成式AI技术在TDA领域的进展,涵盖16篇23-24年的工作。并总结了在生成式AI时代,TDA领域的未来趋势和机遇挑战。三大趋势:表表示的增强,检索方法与生成方法的结合,TDA的自动化。并指出五大机遇:多模态的TDA,TDA的效率与可扩展性,领域TDA,TDA的可解释性,TDA的隐私与安全。 4)本文创建了一个TDA相关工作的git库:SuDIS-ZJU/awesome-tabular-data-augmentation (github.com),并会持续更新维护。 1.4 本文总结的TDA趋势与挑战:
三大趋势:
-
表表示的增强,研究人员越来越多地采用更先进的表表示法,以更好地捕捉表中的结构和语义细节 ;
-
检索方法与生成方法的结合,基于检索和生成的方法具有各自的优缺点,鉴于RAG在NLP领域的成功应用,未来趋势可能在于整合这两种方法;
-
TDA的自动化,创建能够有效管理整个TDA过程的端到端自动化TDA系统。 五大机遇:
-
多模态的TDA,表格逐渐包含更广泛的模态(如图像),同时用户需求可能以其他模态提出(如文本);
-
效率与可扩展性,大规模数据池,大规模生成式AI模型的应用;
-
领域TDA,特定领域的数据通常表现出很强的专业性,并具有一些独特的特征;
-
TDA的可解释性,基于生成的方法多缺乏可解释性,同时新进的生成式AI技术也缺乏可解释性。 5)** TDA的隐私与安全**,基于生成的方法合成数据可起到一定隐私保护作用,而最近将LLM引入TDA工作流程的趋势带来了一系列新的隐私和安全挑战。 **
**
2.TDA的定义与分类
给定一个原始表 和一个由θ参数化的特定ML模型
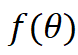
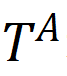
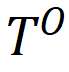
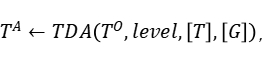
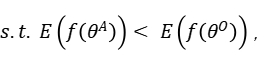
其中level ={行,列,单元格,表}表示TDA操作的粒度,如表1所示; T是基于检索的TDA(使用来自表池的数据来增强原始表)的可选输入,它表示用于信息检索的外部信息源,简称表池;G是基于生成的TDA(直接基于原始表生成新数据)的可选输入,意味着使用某种特定的生成方法。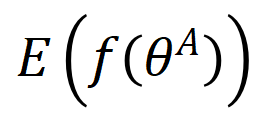
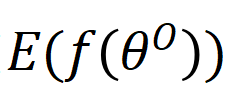
和
数据集上训练的ML模型的经验误差。

表1 基于表粒度的TDA分类法
3.预增强
在TDA流程中,预增强指准备任务,以促进增强的有效性。对于表格数据,常见的问题是缺失或不正确的单元格值和不可靠的元数据(如列名)。对于表池(在基于检索的方法的情况下),随着表数量的增多(百万或更多),在TDA之前进行数据准备至关重要。预增强旨在a.提高原始表和池中表的质量,b.更好地组织表池,以提高加速和可扩展性。这可能涉及一系列任务:
-
错误处理(Error Handling):对表中的脏数据进行预处理,可分为显式和隐式方法。显式错误处理涉及直接检测和纠正错误。隐式错误处理并不直接检测错误,而是增强模型对错误的鲁棒性。
-
表注释(Table Annotation):推断表的元数据(metadata)信息,如列名和列之间的关系。根据现有技术可以分为,基于本体(ontology)的方法,基于监督学习的方法和基于PLM的方法。
-
表简化(Table Simplification):将原始表进行简化,这可以从内容和语义的角度来进行。内容层面,即表采样;语义层面,即表总结。
-
表表示(Table Representation):将表元素(如行、列和单元格)转换为向量,可根据表示内容分为表内容(content)、表上下文(context)和表元数据(metadata)。
-
表索引(Table Indexing):为表元素分配唯一标识符(索引值),允许根据其索引值快速高效地进行查找和检索。根据现有技术可以分为,倒排索引(inverted index)、局部敏感哈希(LSH)和分层导航小世界(HNSW)。
-
表导航(Table Navigation):在表池上建立导航框架,即通过连接相似表来组织表池。根据现有技术可以分为,集群结构(Cluster structure),层次结构(Hierarchical structure)和连接图(Linkage graph)。
-
模式匹配(Schema Matching):评估两列之间的相关性,可以根据匹配内容分为文本匹配、数字匹配,以及元数据匹配。
-
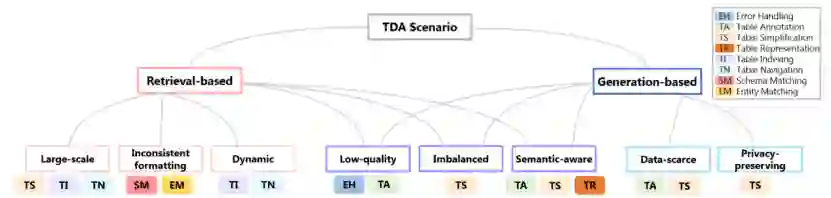
实体匹配(Entity Matching),评估两行之间的相关性。根据现有技术可以分为,基于知识库(KB),基于数据库(DB)和两者结合的混合方法。 同时,本文还总结了不同TDA场景中使用的具体预增强任务,如图3所示。基于检索的TDA通常在拥有大规模数据的表池上进行,从而会出现格式不一致和动态数据等问题。基于生成的TDA通常只需要原表作为输入,可能会遇到数据稀缺问题。同时,基于生成的TDA常用于隐私保护场景。此外,基于检索和生成的TDA方法都面临着一些共同的挑战,例如低质量和不平衡的表。
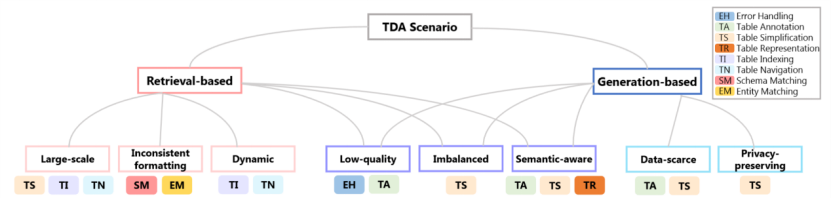
图3. 不同的TDA场景及其适合的预增强任务 **
**
4. 增强
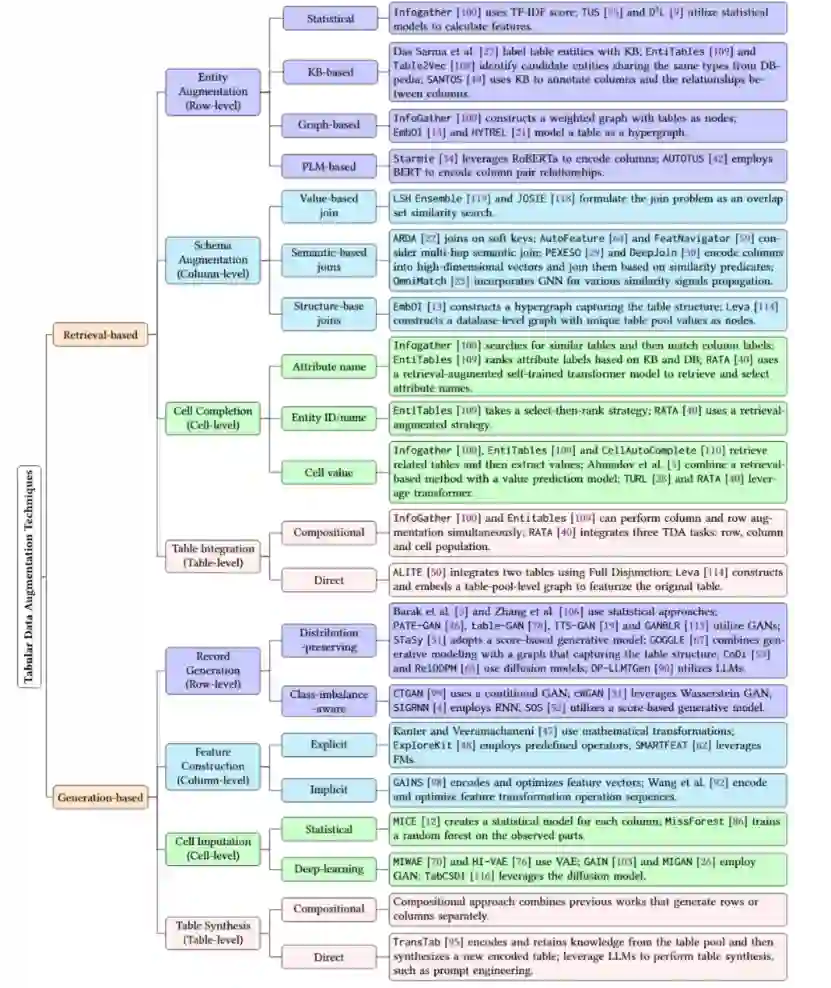
增强是TDA流程的核心过程,旨在使用更多的数据增强原始表,以提升下游的ML任务。TDA技术可分为基于检索和基于生成的方法。基于检索的方法被认为是一种基于原始表(称为查询表)的数据驱动的TDA任务,表池作为额外的输入。这种方法的关键在于正确建模查询表和池中表之间的相似性。基于生成的方法可以有效地利用原始表的上下文(例如统计分布和列对关系)来生成数据进行表增强,不需要额外的数据源。这两种方法都可以根据增强的表粒度进一步细分,最终形成八个具体的TDA任务:
-
实体增强(Entity Augmentation):使用从表池检索到的行增强原表。根据现有技术可以分为,统计方法,基于知识库的方法,基于图的方法和基于PLM的方法。
-
模式增强(Schema Augmentation):使用从表池检索到的列增强原表。根据现有技术可以分为,基于值的连接(value-based joins),基于语义的连接(semantic-based joins)和基于表结构的连接(structure-based joins)。
-
单元填充(Cell Completion): 使用从表池检索到的值填补原表空值。基于单元格的类型可以分为,列名填充,行名/ID填充和单元格填充。
-
表集成(Table Integration),使用从表池检索到的行和列增强原表,可以分为组合型方法(组合前三种方法),和直接型表集成。
-
记录生成(Record Generation):基于原表生成行(记录),根据目的可以分为保留原表记录分布的方法和过采样不平衡样本的方法。
-
特征构建(Feature Construction):基于原表构建列(特征),可以分为显示特征构建(直接变换现有特征,如将“年龄”列从连续型数值列变换成青年中年老年的离散型类别列)和隐式特征构建(通过间接操纵隐藏层中的现有特征向量来生成新特征)。
-
单元填补(Cell Imputation):基于原表生成假设值填补原表中的缺失值,可以根据现有技术分为,统计方法和深度学习方法(如VAE,GAN,diffusion)。
-
表合成(Table Synthesis):基于原表同时生成行和列,可以分为组合型方法(组合前三种方法),和直接型表合成。 图4简要概述了本文所讨论的关键TDA工作及其详细的分类,并对每个TDA工作的特点进行简单介绍。

图4. 基于任务和表粒度的TDA分类,以及每个类别中的关键TDA技术。
同时,本文根据所调研的TDA工作和对TDA技术的两层分类,总结对比了基于检索和基于生成的TDA方法各自的优缺点,并分析了它们共同面临的挑战,如表2。旨在帮助研究人员能够选择最符合其任务和要求的TDA方法。

表2. 对比分析基于检索和基于生成的TDA
5. 后增强
最后,TDA流程包括后增强过程,涉及三个关键方面:TDA数据集、评估策略和优化策略。
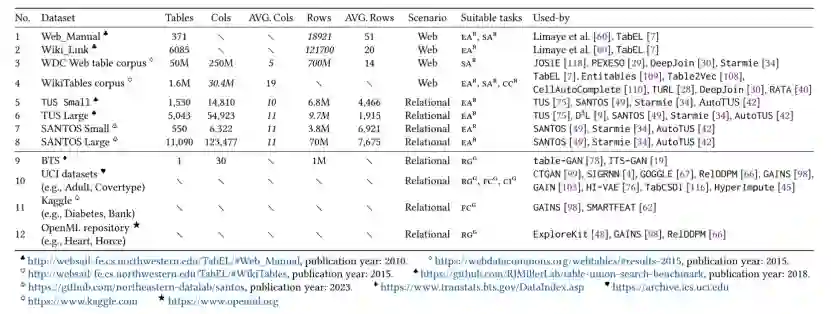
首先,本文详细介绍了与TDA相关的常用数据集以其属性(如表3),并详细阐述了这些数据集各自的特点,最后给出关于TDA数据集相关发现。这些数据集可以大致分为两大类:基于检索的TDA数据集和基于生成的TDA数据集,因为基于检索的TDA需要收集额外的外部表作为表池,而基于生成的TDA只需要原始表作为输入。
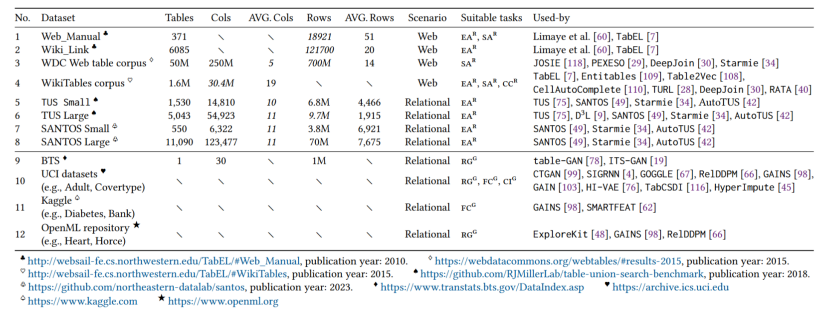
表3 TDA研究中使用的代表性数据集,以及它们的基本属性和适合的特定TDA任务。 然后,本文将评估策略分成两类:a. 基于原始表的评估,将增强表与原始表进行比较(例如,比较它们的统计分布);b. 基于模型的评估,比较在增强数据集与基线数据集上训练的ML模型的性能。并对比这两种策略的优缺点,指出TDA评估的一些机遇。
最后,本文深入探讨了TDA的优化策略。下游机器学习模型可以通过保留提高性能的数据来迭代优化增强结果,直到达到目标精度。更复杂的策略,如基于强化学习(RL)的框架,也可以指导数据优化过程。同样,本文也总结现有TDA优化策略的优缺点与可能的发展方向。
6.总结
本文对面向机器学习(ML)的表格数据增强(TDA)进行了系统地调研,特别突出了近期生成式AI在TDA中的技术突破和最新进展。本文的工作通过构建一个端到端的TDA流程,深挖TDA中涉及的基本步骤:(1)预增强,总结并分析TDA常用的准备技术;(2) 增强,系统比较了当前TDA技术,包括基于检索和基于生成的方法;以及(3)后增强,深入研究TDA后的评估和优化过程。此外,本文还对当前方法的优缺点进行了全面分析,并概述了TDA的未来趋势和机遇。
-End-