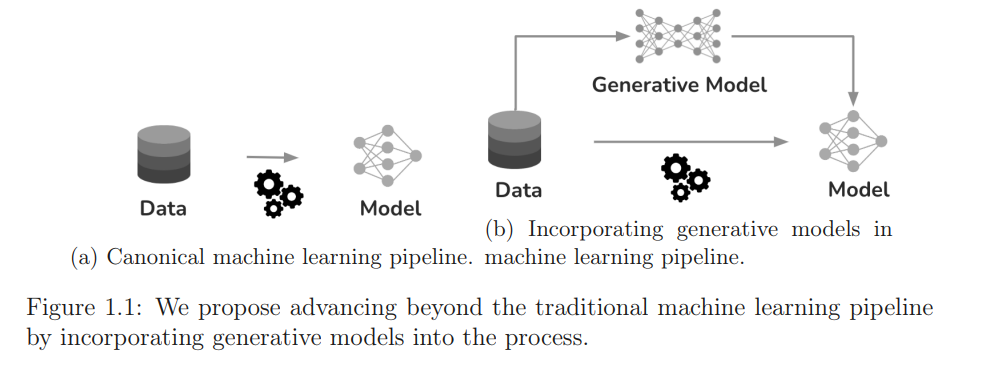
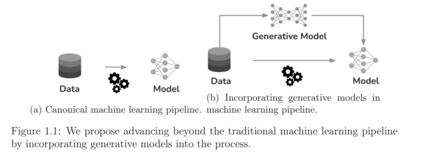
人工智能(AI)的发展迅速,为许多实际应用带来了显著的进步。但是,AI决策的普及也引发了对其潜在安全风险的担忧,因为众所周知AI系统在多个领域都会出现故障,例如自动驾驶、医疗诊断和内容审查。在这篇论文中,我们通过生成模型的角度探讨AI的安全挑战,这是一类能够逼近训练数据集的基础分布并合成新样本的机器学习模型。通过将生成模型与AI安全连接起来,我们揭示了生成模型在解决安全挑战方面的巨大潜力,同时也识别了现代生成模型带来的安全风险。首先,我们重点研究了如何通过将生成模型纳入现有的机器学习流程并合成新的合成图像来提高对抗性强健学习中的泛化能力。我们评估了各种生成模型,并提出了一个新的指标(ARC),基于对抗性扰动的合成数据和真实数据的不可区分性,来准确确定不同生成模型的泛化优势。接下来,我们探讨了生成模型的任务感知知识蒸馏,首先证明了单个合成图像在提高泛化中的不同贡献。为了自适应地采样具有最高泛化效益的图像,我们提出了一种自适应采样技术,引导扩散模型的采样过程以最大化生成的合成图像的泛化效益。然后,我们利用生成模型从低密度区域生成高保真样本,来解决长尾数据分布的不足,这些长尾分布是AI安全中的许多挑战的基础。我们为扩散模型提出了一种新的低密度采样过程,引导该过程走向低密度区域同时保持保真度,并严格证明我们的过程成功地从低密度区域生成了新的高保真样本。最后,我们展示了现有生成模型的一些关键限制。我们首先考虑了异常值检测任务,并展示了现代生成模型在解决它时的不足。考虑到我们的发现,我们提出了SSD,这是一个基于未标记的分布数据的无监督异常值检测框架。我们进一步发现,数百万用户使用的现代扩散模型泄漏了训练数据的隐私,我们从预训练的扩散模型中提取了大量的训练图像。总之,这篇论文解决了多个AI安全挑战,并为新的生成AI范式下的AI系统的安全性和可靠性提供了一个综合框架。