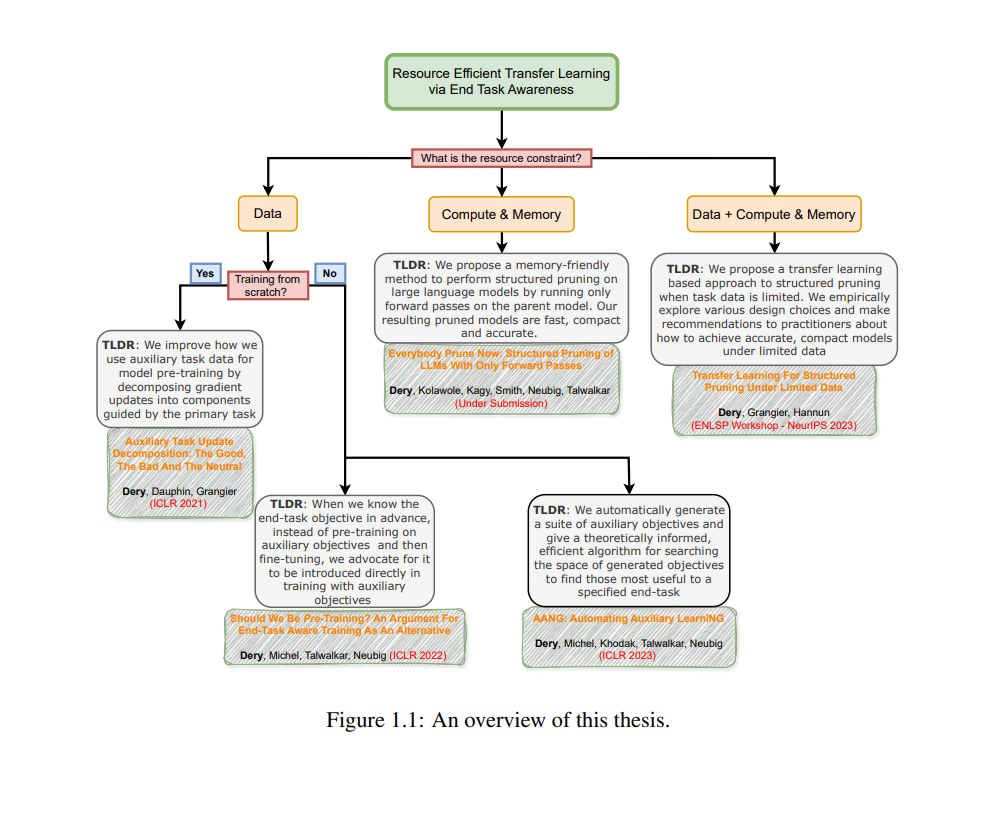
迁移学习是一种机器学习(ML)范式,通过利用其他任务中的“知识”来提高对目标任务的性能。这项技术已成为推动机器学习模型能力边界扩展的关键动力。当前的公式相对简单——在大量迁移任务数据上训练一个大型模型;然后将所学的模型零样本或经过适应性调整后应用于目标下游任务。这篇论文认识到,这些强大的模型并不是在真空中开发的,而是需要大量资源来训练和部署。因此,有许多突出的问题和研究社区被现状所忽视。在这篇论文的第一部分中,我们将专注于数据高效迁移学习的训练时间问题。我们将从一个常见的ML情境出发,论证利用目标下游任务的高级知识来指导迁移学习的不同维度。我们将这种方法称为终任务感知迁移学习。接下来,我们将提出一组新的终任务感知优化算法,这些算法通过偏向数据高效的解决方案来引导学习轨迹,并在终任务上具有较强的泛化能力。我们将以提供一种自动化方法结束这一部分,该方法可以在仅有终任务数据且数据量有限的情况下,构建并搜索与任务相关的迁移目标。 在论文的第二部分中,我们将开发计算和内存高效的迁移学习算法。我们的目标是基于一个已经在迁移任务(或任务集)上预训练的通用大型模型,提供一个小型且高效但仍具有良好性能的任务特定模型,以供部署。我们将以结构化剪枝为主要技术,研究在两种资源受限情况下的剪枝:(1)有限的任务数据,在这种情况下,我们将利用额外的迁移任务来学习剪枝结构,在相同的任务性能下,产生计算和内存更高效的模型;(2)内存受限的环境中,许多经典的剪枝技术因需要基于梯度的优化而导致内存开销过大,从而失效。 本论文的结论部分将通过基于我们的既往工作,提出更多未来在资源高效迁移学习领域的研究方向,并建议一些新的研究分支。 机器学习(ML)模型变得越来越强大,导致它们在许多任务领域(Gururangan等,2020a;Liu等,2022)、数据模态(Team等,2023;McKinzie等,2024)和最终用户应用(Bommasani等,2021;Maslej等,2023)中的广泛采用。可以说,这一惊人增长速度的关键驱动力之一是迁移学习。在迁移学习中,我们通过利用来自不同但希望相关任务的知识,来提高对目标任务(或任务集)的性能(Bozinovski和Fulgosi,1976;Pratt,1992;Ruder等,2019)。我们希望解决的许多终任务数据有限,或者过于复杂,无法通过实际数量的监督样本直接指定或学习。迁移学习不仅通过提供代理数据,还通过利用这些任务与选定迁移任务之间的结构关系,使我们能够高效学习复杂任务(Thrun和Schwartz,1994;Baxter,2000)。 尽管取得了成功,现代实现形式的迁移学习可能资源消耗过大。例如,普遍的预训练后适应范式1。在这种方法中,越来越大的模型首先在越来越多的数据上进行训练,这些模型最终通过微调(Devlin等,2018;Abnar等,2021)、提示(Brown等,2020a;Liu等,2023)或基于人类反馈的强化学习(RLHF)(Christiano等,2017)适应于大量下游任务。GPT-4(Achiam等,2023)作为这一范式下的一个流行模型,据传其参数数量超过1.7万亿2,估计训练时使用了超过10万亿个标记;总共超过1e25次浮点运算(当时约为1亿美元)。尽管这些巨大的训练成本通常被认为可以通过未来的多个终任务摊销,但如此庞大的模型在部署时会带来显著的内存、延迟、计算和能源负担,从而引发了对资源节约程度的真正质疑。 本论文致力于探索资源高效的迁移学习技术。我们认识到,不仅存在广泛的资源受限的ML实践者,还有许多任务在训练和部署时都有内在的资源限制(例如,在边缘设备上执行的任务往往受到内存限制)。即使对于有能力训练和使用大型模型的机构,资源高效的迁移学习也可以带来显著的财务节省,并减少通过二氧化碳排放对环境造成的压力(Ligozat等,2022)。 本论文关注三个主要的资源维度:数据、计算和内存,以及它们在训练和部署时的使用。我们的目标是在训练和测试时实现资源高效的前提下,生成表现出色的模型(包括任务特定的指标,如准确率或F1)。我们将利用的一个基础性见解是,ML实践者通常对模型将用于的终任务有一定程度的先验意识。这种终任务感知使我们能够做出明智的设计决策,从而在资源节约的情况下生成高效且强大的模型。简而言之,本论文基于以下问题陈述: 给定一个特定的终任务T∗,我们如何通过利用一组迁移任务Taux,在资源高效的情况下生成满足T∗各种性能标准的模型? 终任务感知迁移学习的概念本身并不新颖。以往的工作已经在解决复杂规划问题(Stone和Veloso,1994)、提高支持向量机性能(Wu和Dietterich,2004)和构建贝叶斯线性回归的先验(Raina等,2006)等方面探索了不对称迁移。我们感兴趣的是扩展现有文献,并开发适应于新的、深度学习主导的时代(LeCun等,2015;Goodfellow等,2016)的新方法。与以往的工作不同,我们不仅关注提高任务指标,如准确率或困惑度,我们还关注在资源高效的情况下实现这些改进。下面,我们将提供本论文中不同工作部分的高层次概述,并说明它们与我们定义的目标的关系。