【AAAI 2020论文】一种面向推荐的自适应margin对称度量学习方法
导读

介绍

问题定义


方法
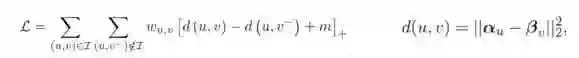
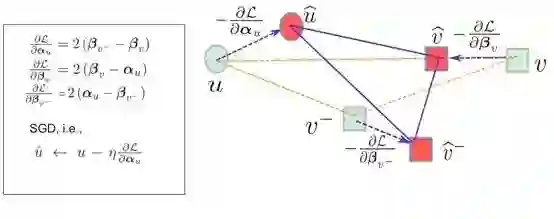

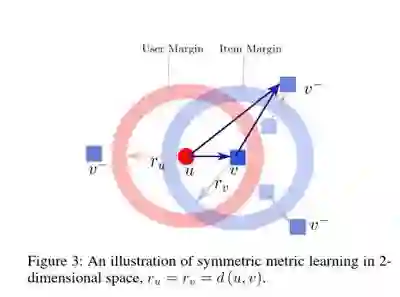
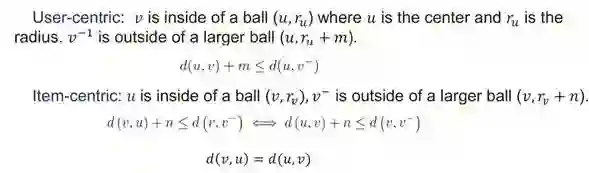
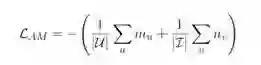
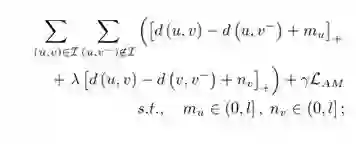
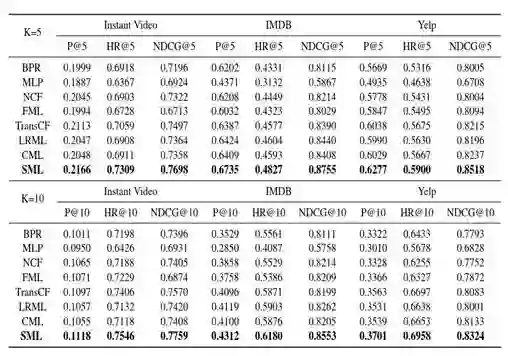
实验

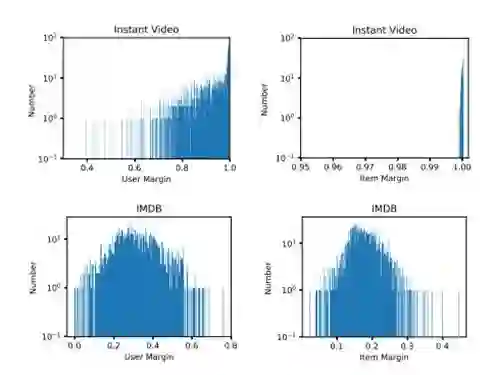
总结
参考文献


登录查看更多
相关内容

Arxiv
6+阅读 · 2018年5月17日


相关VIP内容
相关资讯
相关论文
Arxiv
6+阅读 · 2018年5月17日