

将强化学习(Reinforcement Learning,RL)融入多模态大语言模型(Multimodal Large Language Models,MLLMs)推理能力的研究方向正迅速发展,成为一项具有变革性的前沿课题。尽管多模态大语言模型在传统大语言模型(LLMs)的基础上显著扩展,能够处理图像、音频和视频等多种模态,但在多模态输入下实现稳健推理仍面临重大挑战。本文系统回顾了基于强化学习的多模态推理研究进展,涵盖核心算法设计、奖励机制创新以及实际应用案例。我们重点分析了两大类强化学习范式——无价值函数方法(value-free)和基于价值函数方法(value-based),并探讨了RL如何通过优化推理轨迹与对齐多模态信息来增强推理能力。此外,本文还全面梳理了主流基准数据集、评估方法以及当前研究的局限性,并提出了未来可能的研究方向,以应对稀疏奖励、低效的跨模态推理以及真实场景部署等关键瓶颈。我们的目标是为有志于推进多模态时代RL推理研究的学者提供一个系统而全面的参考指南。
1 引言
大型语言模型(Large Language Models,LLMs)的兴起 [2, 35, 36, 94, 130] 为人工智能领域带来了前所未有的新纪元,展现出卓越的指令遵循能力和少样本学习能力 [10]。然而,实现类人智能不仅需要超越基础感知能力,更需要发展出能够通过上下文理解和自我纠错进行迭代推理的复杂认知能力。受此启发,情境学习(In-context Learning,ICL)技术 [112, 113, 121] 赋予了LLMs逐步推理的能力,这种机制通常被称为“思维链条”(Chain-of-Thought,CoT)推理机制 [9, 109, 114, 146]。OpenAI 的 o1 模型 [45] 在解决推理任务方面表现出色,引发了各领域对推理能力推理时间扩展(test-time scaling)研究的广泛关注。通过在推理过程中引入额外计算以实现“慢思考” [49],该模型进一步提高了对复杂问题的回答准确性。
在LLMs中广泛开展的CoT研究启发下,多模态大语言模型(Multimodal Large Language Models,MLLMs)中的推理任务 [6, 69, 96, 105, 119] 也迅速取得进展。典型的方法包括 Best-of-N、Beam Search 以及蒙特卡洛树搜索(Monte Carlo Tree Search)[13, 99, 108, 125, 132]。这些方法依赖复杂的搜索机制生成大量推理数据,并通过监督微调使模型学习自主推理能力。
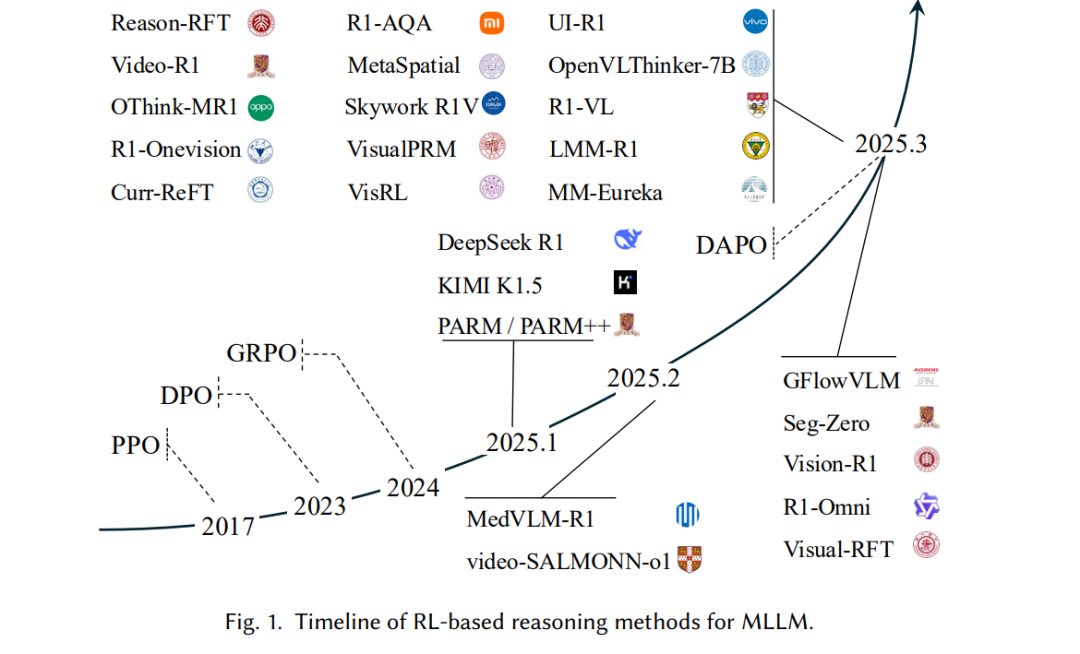
随着强化学习(Reinforcement Learning,RL)理论和技术的进步,DeepSeek R1 [37] 展示了大语言模型如何通过基于规则的简单激励机制和轻量级强化学习算法(如GRPO [85])自主学习复杂推理能力。这种方法使LLMs在无明确监督的情况下自然产生“灵光一现”(Aha Moment),表现为训练过程中模型自我反思并自主延长回答长度。近期研究 [43, 63, 76, 150] 将该方法扩展至MLLMs,并应用于目标识别 [63]、语义分割 [60] 和视频分析 [91] 等领域。这些方法在训练数据有限的情况下显著提升了MLLMs的性能,在域内测试中可媲美监督微调(SFT)方法,在分布外(OOD)评估中更是超越了SFT模型。
然而,正如图1所示,这一迅速发展的趋势也为研究人员带来了诸多挑战。尽管基于RL的方法有效,但大多数仍延续文本思维范式,忽视了在多模态场景中其他模态所扮演的关键角色。此外,当前的RL推理方法主要依赖基于规则的奖励函数与可验证答案,未能覆盖更广泛的泛化场景问题,如无明确答案的问题。 尽管已有多项综述聚焦于MLLMs的推理能力 [54, 110],但尚无文献专门针对MLLMs中基于RL的推理方法进行系统探讨。为填补这一空白,本文系统综述了基于RL的MLLMs推理方法,全面梳理技术发展、方法体系、实际应用与未来方向,旨在为快速演进的MLLM推理研究提供系统化的参考与指导,从而推动该领域的持续创新。
我们首先在第2节介绍MLLMs、思维链条推理机制和强化学习的相关背景。接着在第3节回顾LLMs和MLLMs中RL算法设计及其优化策略;第4至第6节详述RL在MLLMs中推理方法的算法设计、奖励机制与基准评估;最后,第7节探讨当前限制与未来研究方向。 本文从以下四个关键视角出发,系统分析MLLMs中基于强化学习的推理方法: * 探索RL在LLMs与MLLMs中的关键设计与优化策略:重点分析无价值函数方法(value-free)与基于价值函数方法(value-based)的核心理念与改进方向,探讨其在提升训练效率、稳定性与推理性能方面的创新方案,比较各方法优劣与未来优化潜力。 * 分析现有基于RL的推理方法的算法框架、奖励函数设计及模态融合策略:从所使用的强化学习算法、奖励机制(以准确性或结构为导向)及多模态输入整合(包括视觉、音频与时序信息)等维度,对代表性方法进行系统分类。 * 调研评估MLLM推理能力的基准数据集与评估协议:分析数据集的构建流程,包括数据来源、模型输出收集及偏好标注方法,涵盖数学、科学、空间、交互等多种类型的推理任务,并按领域特异性与泛化能力进行组织。 * 识别当前局限并提出未来研究方向:讨论当前面临的挑战,如稀疏与静态的奖励反馈、低效的推理路径与薄弱的跨模态协同等问题,探讨包括层级化奖励建模、视觉引导的CoT生成以及适用于真实多模态智能体的轻量级RL框架等前景方向。

