

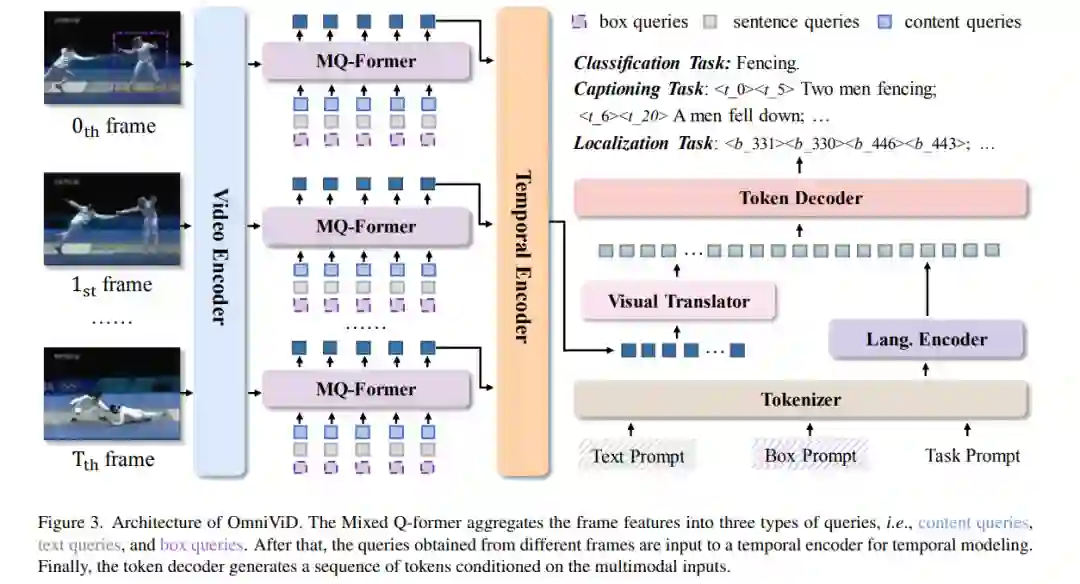
视频理解任务的核心,如识别、字幕生成和跟踪,是自动检测视频中的对象或行动并分析它们的时间演变。尽管共享一个共同目标,不同的任务经常依赖于不同的模型架构和注释格式。相比之下,自然语言处理受益于一个统一的输出空间,即文本序列,这简化了强大的基础语言模型(如GPT-3)的训练,这些模型使用了广泛的训练语料库。受此启发,我们寻求通过使用语言作为标签并额外引入时间和框标记来统一视频理解任务的输出空间。通过这种方式,多种视频任务可以被构想为视频基础的令牌生成。这使我们能够在一个完全共享的编码器-解码器架构中,遵循一个生成框架,处理各种类型的视频任务,包括分类(如动作识别)、字幕生成(覆盖片段字幕生成、视频问题回答和密集视频字幕生成)和定位任务(如视觉对象跟踪)。通过全面的实验,我们展示了这样一个简单直接的想法是非常有效的,并且能在七个视频基准测试上达到最先进或具有竞争力的结果,为更通用的视频理解提供了一个新颖的视角。代码可在 https://github.com/wangjk666/OmniVid 获取。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日

相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日