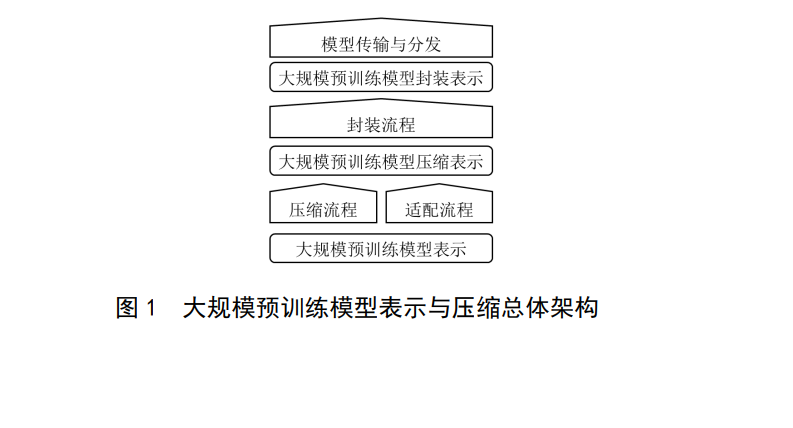
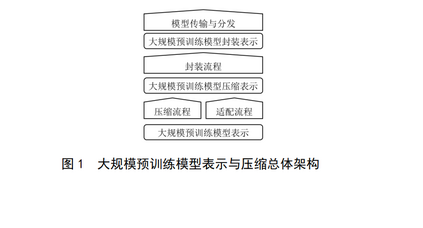
人工智能领域正在发生迅速的范式转变,深度影响了计算机视觉、自然语言处理、机器人、自动驾驶、智慧医疗等领域的发展。大规模预训练模型是人工智能技术体系的重要组成部分,是国民经济各行业应用人工智能的前提。该标准的目标在于提供大规模预训练模型可能涉及的表示和压缩技术方法参考,提升用户对模型的复用效果。使用时,对于大规模预训练模型的表示方法、传输方法应进行必要的支持,对于压缩技术可根据实际应用场景及技术构成做可选支持,具体的支持方法由后续标准进行补充。对于该标准规定的表示方法不要求平台原生支持,可以通过转换、工具包等形式进行支持,同时相关的定义可转化为与特定计算设备、框架匹配的形式和实现。GB/T 42382旨在确立适用于不同种类神经网络的表示方法与模型压缩的规范,拟由三个部分组成: ——第 1 部分:卷积神经网络。目的在千确立适用千卷积神经网络的表示与模型压缩标准。——第 2 部分:大规模预训练模型。目的在于确立适应多种推理平台和计算要求的大规模预训练模型的基本表示方法与加速压缩过程。 ——第3部分:图神经网络。目的在于确立适应多种计算要求的高效图神经网络模型的基本表示方法与压缩加速过程。 本文件的发布机构提请注意,声明符合本文件时,可能涉及到7.3.1.2与《一种基于可微量化训练的视觉Transformer压缩方法及系统》(专利号:2022102951896)、7.2.1与《基于层间特征相似性网络稀疏化方法、装置、介质及设备》(专利号:202210842886.9)、7.4.4与《一种两阶段微调大语言模型代理的方法》(专利号:202410358176)、7.4.5与《一种提高大型语言模型适配多模态任务效率的方法》(专利号:202311290661.8)、7.3.1与《数据处理方法、装置、介质及电子设备》(专利号:202410154029.9)、7.3.2.3.4与《神经网络模型裁剪方法、装置、电子设备及存储介质》(专利号:202210615980.0)、7.2.5与《任务处理方法、装置、电子设备及存储介质》(专利号:202210709171.6)、7.3.1与《基于模型量化的任务处理方法、装置、设备及存储介质》(专利号:202211186183.1)、7.2与《一种特征提取的方法以及装置》(专利号:113065576A)、7.2与《一种注意力模型、特征提取方法及相关装置》(专利号:113627163A)、7.2与《一种数据处理方法及相关设备》(专利号:114897039A)相关的专利的使用。 本文件规定了适应多种计算要求的大规模预训练模型的基本表示方法与加速压缩过程,包括但不限于基于单向架构(Encoder-Only架构)、生成式架构(Decoder-Only架构)、序列到序列架构(Encoder-Decoder架构)的模型。 本文件适用于大规模预训练模型的研制、开发、测试评估过程,以及在端云领域的高效应用。注:对于本文件规定的表示与模型压缩方法不要求机器学习框架原生支持,可以通过转换、工具包等形式支持。