

摘要 — 大型语言模型(LLMs)正在以惊人的速度发展,并已成为学术界、工业界和日常应用中不可或缺的一部分。为了跟上当前的发展态势,本调查深入探讨了LLMs崛起对评估所带来的核心挑战。我们识别并分析了两个关键的转变:(i)从任务特定的评估到基于能力的评估,这一转变围绕知识、推理、指令跟随、多模态理解和安全性等核心能力重组基准;(ii)从手动评估到自动化评估,包括动态数据集创建和“LLM作为评审员”的评分。然而,即使在这些转变之后,仍然存在一个关键的障碍:评估泛化问题。有限的测试集无法与能力似乎无限增长的模型相匹配。我们将从方法、数据集、评估者和度量标准的角度,剖析这一问题以及上述两个转变的核心挑战。鉴于这一领域的快速发展,我们将维护一个持续更新的GitHub存储库(每个章节中都有链接)来众包更新和修正,热忱欢迎贡献者和合作者参与。 关键词 — 大型语言模型、评估、基准、调查
1 引言
大型语言模型(LLMs)在学术界和工业界取得了前所未有的成功,这在很大程度上归功于训练和评估技术的快速进展。作为“质量控制系统”,评估不仅指导技术进步的轨迹,还充当潜在风险的预警机制。最近的推理型LLMs,如OpenAI的o1或DeepSeek-R1,进一步强调了评估的重要性——通过将推理、评估和随后的再推理(即细化或修正)整合到一个单一的思维链(CoT)中,它们的推理质量得到了极大提升。这些进展为评估领域注入了新的活力,产生了越来越多的基准和评估研究。为了跟上这一快速增长的步伐,我们的调查不仅仅是列出或针对特定方面的回顾。相反,我们深入探讨了基础挑战,通过考察LLMs的出现如何重塑评估领域,我们称之为评估泛化问题。
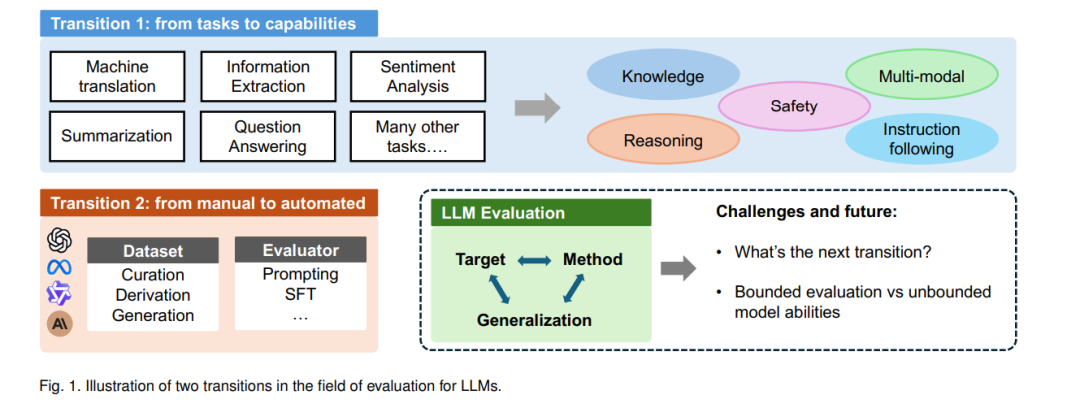
在回顾当前该领域的研究时,我们识别出两个关键转变。如图1所示,评估中的一个转变是从任务特定到基于能力的转变。传统的评估方法专注于特定任务(例如,文本分类、信息抽取)。随着LLMs将各种NLP任务统一为自然语言生成的形式,每个任务的定义及其之间的边界变得越来越模糊。在这一新范式下,每个指令或提示都可以视为一个独立的任务,从而将注意力转向评估解决现实世界需求所需的核心能力。在本调查中,我们识别出五个关键能力:知识、推理、指令跟随、多模态理解和安全性。在第二部分,我们回顾现有的基准并将其归类于这一能力框架中,进一步细分为更详细的子类别。此外,我们讨论了综合评估,评估不同能力之间的相互作用及当前的实时排行榜。这种从基于任务的评估到基于能力的评估的转变使得对模型真实潜力的全面理解成为可能,超越了其在预定义任务中的表现。 评估中的另一个转变是从手动方法到自动化方法,包括数据创建和判断。在数据方面,模型性能的快速发展要求基准更新的频率不断增加,而手动创建过程已变得不可持续,这一点在GSM8K(Grade School Math 8K)上准确率从74%到95%在两年内的飙升中得到了体现。自动化管道可以解决数据集创建中固有的成本和效率挑战。自动化的另一个好处是能够减少数据污染的风险,即测试数据在预训练或后训练过程中不小心暴露,导致性能被高估。为应对这一问题,自动化方法可以成为解决方案之一,它不断更新或细化测试集,被称为动态基准,确保测试数据在前期没有暴露。
在判断方面,如上所述,转向用户提示带来了更多开放式的响应,这提出了更多复杂性:人工判断成本高昂。自动评估器(即“LLM作为评审员”)不仅在提供可靠、高效的评估方面展现出潜力,而且还能生成更详细、更细致的人类响应评估。在第三部分,我们对这些自动化方法进行了全面回顾。
尽管研究人员在上述两个转变中取得了显著进展,但我们认为一个根本的矛盾依然存在:即通过规模法则暗示的训练范式与有限评估实践之间的矛盾。随着模型参数、训练FLOPs和数据量的增加,性能似乎可以无限提升。然而,考虑到效率,评估数据集在实践中无法无限扩展或多样化。也就是说,当前的评估管道无法与模型能力同步扩展。结果是,模型能做什么与我们的测试能覆盖什么之间的差距日益增大。这种紧张关系是LLM评估中的许多已知挑战的根源。例如,以数据污染为例,由于有限的测试数据集只能覆盖模型能力的一个子集,不同模型在评估中可能会获得异质的优势,导致不公平的比较。也就是说,如果模型在训练期间已经遇到并记住了测试样本,它的测量能力将与数据集评估的内容完全对齐,从而给予它一个不一定反映更强实际能力的过度优势。
我们将上述问题——如何利用有限的评估管道来评估一个无限的模型能力——称为评估泛化问题。换句话说,现有的评估往往集中于模型已经展现的能力或能够通过固定的测试集表达的能力,固有地限制了评估范围。因此,在LLM时代,评估的核心挑战是开发能够预测未来或尚未表达的能力的可泛化评估方法。在本调查中,我们从数据集、评估者和度量标准等不同角度,探讨这一挑战并探索潜在的解决方案。例如,一些工作专注于预测性评估,精心创建各种任务以根据小规模模型的表现来估计大规模模型的表现[1]。或者,Cao等[2]提出结合表现和基于新解释性的度量——模型利用指数(MUI),用于评估LLMs在给定数据集之外的潜力。其基本思想类似于人类评估实践:在判断一个人的整体能力时,我们既考虑结果,也考虑所需的努力(即MUI)——相同表现所需的努力较少,表示更高的熟练度。
值得注意的是,LLM评估是一个快速发展的领域。虽然我们已经尽力列出最新的文本中心评估工作,但许多研究仍处于预印本阶段。因此,我们在这里强调的是前瞻性的见解和研究方向。不可避免地,可能会出现一些遗漏或不准确的地方。我们计划维护一个专门的GitHub存储库,并邀请社区帮助我们进行改进;主要贡献者将得到感谢或被邀请作为合作者。
