
原创作者:王洋 指导老师:赵妍妍 转载须标注出处:哈工大SCIR
1. 引言
近年来,混合专家模型(Mixture of Experts, MoE)因其在提升大模型性能与效率方面的独特优势,逐渐成为大型语言模型(Large Language Models, LLM)领域的研究热点。在大型语言模型遵循缩放定律(Scaling Law)[1]进行参数扩张的过程中,计算资源效率与模型表征能力的平衡问题愈发显著。混合专家模型通过条件计算范式,成功实现了参数规模与计算成本在一定程度上的解耦。该架构基于动态稀疏激活的思想,通过多专家网络结构扩展模型容量,借助门控机制实现输入自适应的子网络激活,使得模型在推理时仅消耗少量算力即可利用庞大参数量带来的性能增益。例如,基于MoE架构的DeepSeek-V3[2]拥有惊人的6710亿参数,但在实际推理过程中,每个token仅激活其中的370亿参数,如图1的评估结果所示,其模型性能超过了激活更多参数量的开源模型(如Qwen2.5-72B-Instruct[3]),并能够与主流闭源模型相媲美。然而,MoE的复杂性也带来了专家专业化、训练稳定性、负载均衡等挑战,如何平衡性能与实用性仍是该领域探索的核心方向。
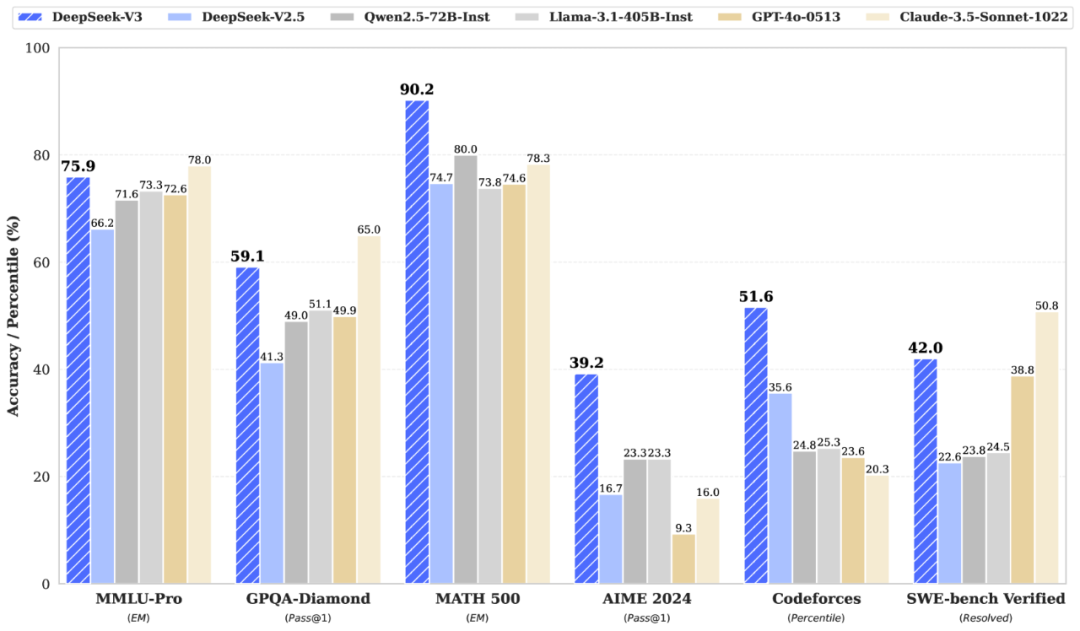
图1:DeepSeek-V3及其他模型在基准测试中的表现[2] 本文将从混合专家模型的背景开始,介绍MoE架构在几个研究问题上的主要研究进展,并讨论了几个值得探索的改进方向。
2. 背景
1991年,混合专家模型的创始论文《Adaptive Mixtures of Local Experts》[4]由Michael Jordan和Geoffrey Hinton等联合发表。论文指出,在多任务的学习过程中,传统的训练方法会导致模型在对特定领域进行参数更新时降低其他领域的性能,为了减少这种任务间的干扰效应,论文提出了混合专家模型的原型,即构建多个独立的专家网络,每个专家仅学习和处理特定场景下的子任务,从而提高了学习效率和模型的泛化能力。 2020年,Gshard[5]首次将稀疏门控的MoE引入transformer[6]架构中,将参数量扩展到600B。 在基于transformer架构的LLM中,MoE主要由两个关键部分构成:
- 专家(Experts):模型中的每个专家都是一个独立的神经网络,专门处理输入数据的特定子集或特定任务,在LLM中通常使用由多个专家构成的专家层替换原有的FFN层,这些专家通常是FFN,但也可以是更复杂的结构,甚至是MoE层本身[7]。
- 门控网络/路由(Router):门控网络的作用是决定每个输入样本应该由哪个专家或哪些专家来处理。它根据输入样本的特征计算出每个专家的权重或重要性,然后根据这些权重将输入样本分配给相应的专家。
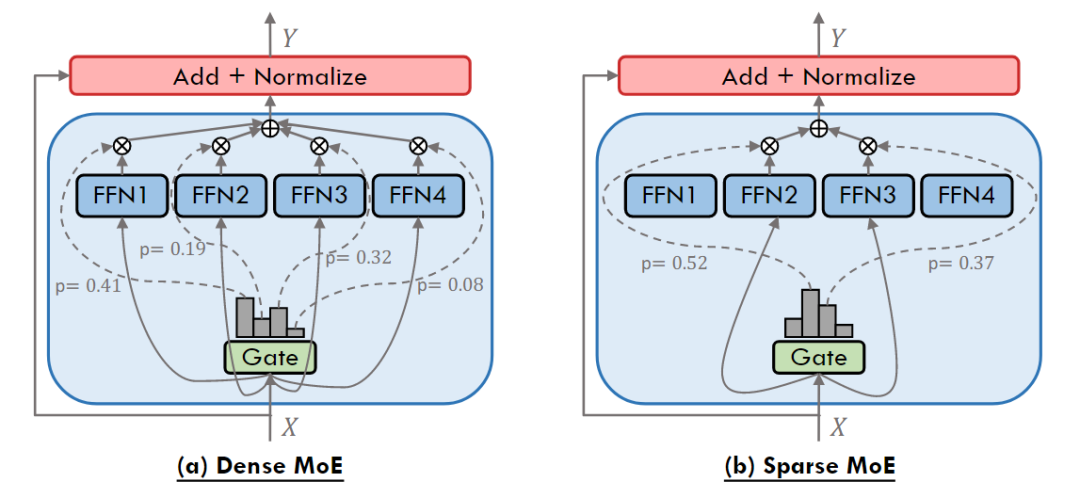
图2:密集激活的MoE层和稀疏激活的MoE层图示[8] 根据门控网络的激活方式,MoE可以大致分为两类,如图2所示:
- 密集激活的MoE(Dense MoE):密集激活的MoE在每次前向传播时激活所有专家网络,通过门控网络为每个专家分配权重,最终输出为所有专家结果的加权和。其门控设计不进行专家筛选,仅通过线性层和Softmax等函数分配权重,因此在训练过程中无需处理负载均衡问题,具有较高的训练稳定性。
- 稀疏激活的MoE(Sparse MoE):稀疏激活的MoE仅选择top-k(通常k=1或2)专家参与计算,其余专家输出置零,通过带噪声的稀疏门控函数实现条件计算。其核心优势在于计算效率随激活专家数线性增长,而非总参数量。
3. 研究进展
3.1 负载均衡问题
负载均衡问题是指在路由过程中,由于输入样本分配不均,导致某些专家模块被过度激活而其他专家利用率不足的现象。这种不均衡会降低计算资源效率,部分专家可能因负载过高而影响处理质量,而闲置专家则无法充分参与训练。
3.1.1 专家容量
GShard[5]中设定了一个阈值,来约束一个专家最多能够处理多少个token,这个阈值便是专家容量(Expert Capacity)。如果被分配到的专家已经达到接收上限,token就会溢出,并通过残差连接传递到下一层,或被完全丢弃。 Switch Transformer[9]中对专家容量进行了进一步研究,并提出了容量因子(Capacity Factor)的概念: 容量因子令模型在期望专家容量的基础上允许一定程度的超载,以此提高模型效果。后续的ST-MoE[10]也强调了容量因子的重要性。 Kim等人[11]通过随机化序列中token的路由优先级,避免模型对序列位置的token产生路由偏好,从而更公平地利用专家容量。 OpenMoE[12]则阐述了一个由专家容量引起的末端token掉队现象:在处理长序列时,前面输入的token把专家容量吃满,后面输入的token更容易被丢弃,导致长序列训练不充分。 类似于专家容量,DeepSeek-V2[13]也采用了设备级别的token丢弃策略,他们为每个设备设置最大容量,避免设备级的负载不均导致计算资源浪费。
3.1.2 负载均衡损失
GShard[5]提出了最早的负载均衡损失函数,称为Aux Loss(Auxiliary Loss),其通常定义为下: 其中, 是专家总数, 表示实际分配给专家 的token比例, 是模型分配给专家 的平均门控概率。 通过硬分配统计得出: 其中, 是批次 中的token总数, 是指示函数(若token x 被分配给专家 i 则为 1,否则为 0), 是门控网络输出的专家概率分布。 是门控概率的软分配平均值: 即对所有token的门控概率在专家 i 上的取值取平均。 当损失最小时(),各专家负载达到最理想的情况,此时将满足两个条件:
- 每个专家的token分配比例 ,即均匀分配;
- 每个专家的门控概率均值 ,即门控权重均衡。
Aux Loss通过惩罚 与 的偏离,鼓励模型平衡专家负载,避免部分专家过载或闲置。由于 基于可微的门控概率计算,损失可通过梯度下降直接优化。在训练中,总损失为主任务损失(如交叉熵)与负载均衡损失的加权和: 其中 为超参数,控制负载均衡的优化强度。 然而,全局统一的忽略了不同层之间的负载差异。Skywork-MoE[14]为此提出了一种创新的自适应辅助损失系数方法,根据各层实时监测的token丢弃率动态调整系数:若某层token丢弃率高,则增加该层的辅助损失权重以强化平衡;反之则降低权重以减少对主任务损失的干扰。 除了上述专家级别的负载均衡损失,DeepSeekMoE[15]也采用了设备级的负载均衡损失,鼓励每台设备都充分参与到计算中。
3.1.3 Loss Free的负载均衡方法
传统的Aux Loss通过引入额外的损失引导路由给出均衡的分数,而在训练中引入任务无关的损失多少会影响主任务表现[16]。DeepSeek-V3[2]通过动态调整路由专家的偏置项实现了一种无负载均衡损失的负载均衡策略: 具体而言,他们为每个专家设置了一个偏置项,系统实时监测每个专家的token分配情况:当某专家在当前批次处理量超出平均水平时,偏置项会在训练步结束时以固定速率递减;反之低负载专家的偏置项则会递增。这种偏置调整仅作用于路由选择阶段,而实际计算时仍采用原始亲和度分数,使得模型能够在不引入额外损失项约束的前提下,通过负反馈机制自动平衡各专家的负载分布,且性能优于仅通过辅助损失实现负载平衡的模型。
3.2 专家专业化
3.2.1 共享专家
在传统路由策略中,分配给不同专家的token可能需要某些共有知识或信息,多个专家可能在各自的参数中不断学习共享知识,从而导致专家参数的冗余。因此,DeepSeekMoE[15]设置了专门用于捕获和整合不同上下文间共有知识的共享专家,令其他路由专家之间的参数冗余问题得到缓解。这种冗余的减少将有助于构建参数效率更高的模型,并增强专家群体的专业化。具体如图3所示,他们隔离了 个专家作为共享专家。无论路由的计算结果如何,每个token都会被确定性地分配给这些共享专家。
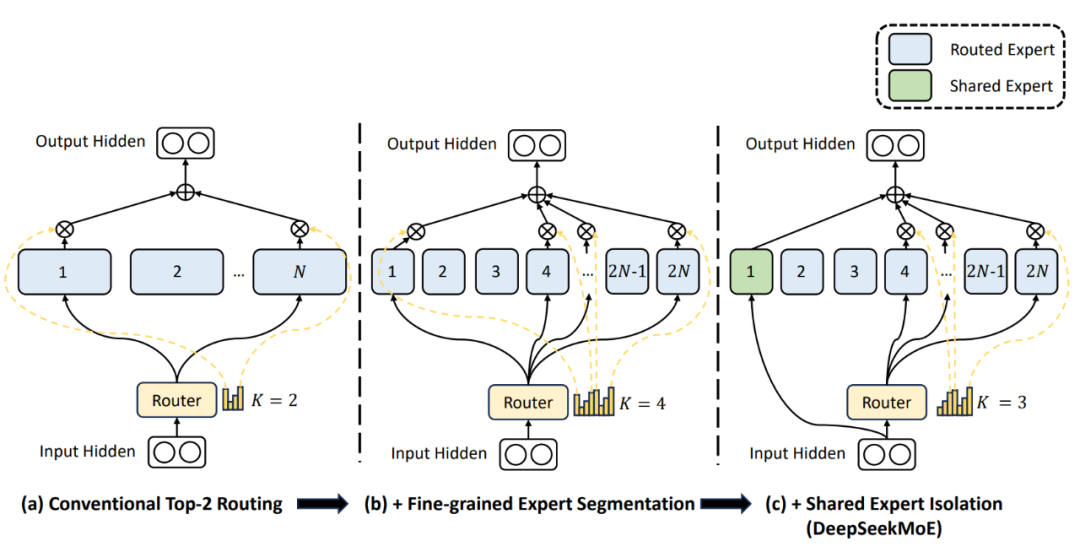
图3:DeepSeekMoE采用的共享专家设计[15] 共享专家方案在后续的工作中被广泛使用[3,12,17-19]。然而在最新的Qwen3[20]中,Qwen团队舍弃了Qwen1.5[17]和2.5[3]一贯采用的共享专家机制也取得了很好的效果,因此,共享专家是否为专家专业化的必要条件仍需要进一步探讨。 3.2.2 细粒度专家 在专家数量有限的情况下,分配给特定专家的token可能涵盖多种类型的知识,这导致专家在参数更新的过程中试图学习差异巨大的不同类型知识,降低了专家专业化程度。因此,DeepSeekMoE[15]提出了细粒度专家的概念,即在不增大整体参数及激活参数的情况下,将专家划分为更多、更小的专家。在细粒度划分下,每个专家更容易聚焦于学习自身专业的知识。 DeepSeekMoE[15]从组合学的角度解释了细粒度划分的优点:以专家数量N=16的情况为例,典型的top-2路由可以产生种可能的专家组合,相较之下,如果将每个专家拆分为4个更细粒度的专家,总专家数量变为64,激活专家数量在同等激活参数量的情况下增至8,可以产生种可能的专家组合,组合灵活性的激增,为实现更精准、更具针对性的知识获取提供了可能性。
3.2.3 异构专家
在传统的MoE模型中,所有专家都采用相同的结构和大小,降低了专家间的区分度与专家的专业化潜力。腾讯混元团队在2024年提出的混合异构专家模型[21]填补了异构专家设计的空白。如图4所示,该研究通过为专家分配差异化的隐藏层维度,构建了能自适应处理不同复杂度语言单元的专家系统,其中小规模专家专注常规特征处理,大规模专家应对复杂语义推理。为优化专家激活策略,他们还提出参数惩罚损失函数(P-Penalty),通过引入专家容量权重因子,有效抑制了训练过程中大专家过度激活的现象,促使模型在保证性能的前提下优先调用轻量级专家。
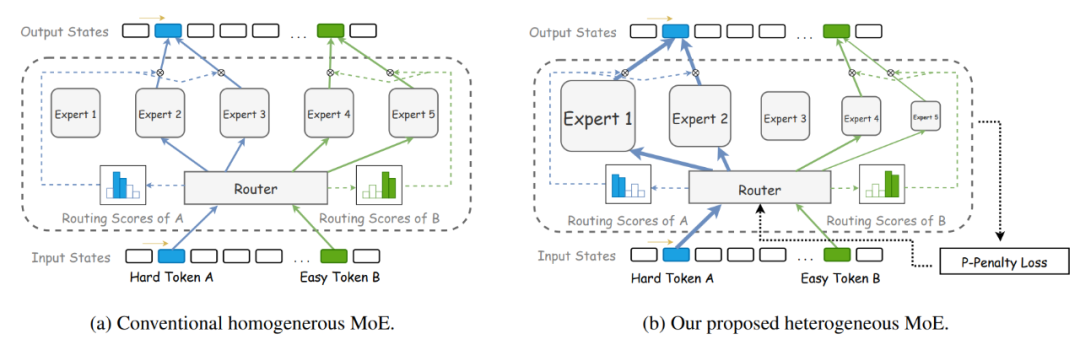
图4:同构专家与异构专家结构图示[21]
3.3 动态路由
Top-k的路由激活方式为每个输入均匀分配固定数量的专家,忽略了任务难度的差异性,可能导致简单任务资源浪费或复杂任务资源不足。为了解决这个问题,多个工作研究了动态路由机制。 Huang等人[22]提出基于置信度的动态路由方法。类似LLM解码阶段的top-p,该方法通过设定阈值动态调整激活专家数量:当最高置信度专家概率超过阈值时仅激活单个专家,否则按概率降序选择专家直至累计置信度总和超过阈值。 AdaMoE[23]和MoE++[24]通过在专家中加入一些零计算成本的专家(空白专家、复制专家及常量专家),在token选中这些零成本专家时,就等效于减少了选择专家的数量,从而在不修改top-k路由架构的基础上间接实现了动态路由。 除了上述方法,还有Ada-K[25]引入新的模块用于预测专家激活数量,该模块通过强化学习中的PPO算法训练,能够在保持模型性能的同时显著降低计算开销。
3.4 MoE后训练
2023年,Shen等人利用FLAN数据集对MoE模型进行了大规模的指令微调[26],其研究发现MoE模型在直接下游任务微调时性能弱于密集模型,但通过引入多任务指令微调后,其泛化能力显著提升,尤其在零样本和少样本场景下表现优异。这项工作揭示了多任务指令微调对MoE专家分工的促进作用。 在MoE的后训练过程中常常出现训练不稳定的问题,具体表现为训练曲线剧烈波动甚至发散。ST-MoE[10]的研究指出,这种不稳定主要源于路由机制中的数值问题:当路由器logit值过大时,softmax计算在低精度(如bfloat16)下会产生显著舍入误差,这会错误分配专家权重并导致梯度爆炸。为此作者提出了辅助损失函数z-loss: 此损失通过惩罚过大的logits来避免极端值的出现,有效缓解了训练中的梯度爆炸和数值精度问题,同时也保持了模型质量。 现有多任务指令微调方法通常静态合并多个领域的指令数据,但固定采样权重忽略了模型训练过程中不同任务重要性的动态变化,导致冗余数据难以有效区分。针对MoE在指令调优中的多任务数据冗余问题,Tong Zhu等人[27]提出了一种基于路由偏好动态调整数据采样权重的创新方法。他们利用MoE模型特有的路由机制,通过统计各数据集在专家层的token分配模式,构建数据集表征并计算L2距离以量化任务间冗余度,进而动态增加差异化显著的数据集采样权重。
3.5 PEFT+MoE
参数高效微调(PEFT)方法旨在降低通用预训练模型适应特定任务时的计算需求,其仅更新少量参数,同时保持基础模型其余部分冻结。然而由于训练参数有限及可能引发灾难性遗忘,PEFT方法在多任务泛化方面仍面临挑战。在此背景下,PEFT+MoE的微调范式应运而出,此范式采用了MoE的门控机制及多专家架构,其中每个专家为单独的PEFT模块。这种结合巧妙利用了MoE的多任务优势及PEFT的高效训练,被许多研究工作所采用[28-35]。MIXLoRA[35]中总结了2024年4月前采用LoRA-MoE方法的工作,如图5所示。
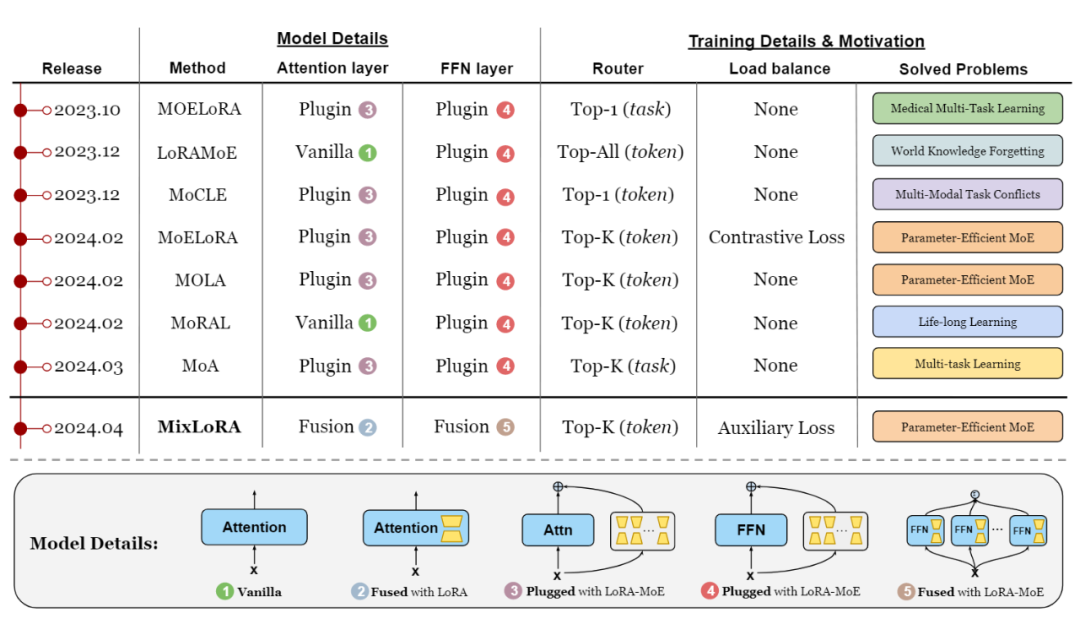
图5:LoRA-MoE相关工作的发布时间、实现细节及目标问题[35]
4. 未来展望
混合专家模型通过独特的参数稀疏化架构,在不显著增加计算成本的前提下实现了模型参数量的扩展,这种新的技术路径使得MoE模型在多项基准测试中展现出卓越性能[2,20,36],并迅速成为学术界与产业界共同关注的前沿方向。基于当前研究进展,本文梳理出以下具有潜力的研究方向。
- 专业化且可解释的专家架构设计。MoE的设计初衷是为了让每个专家专注于某一特定领域,然而 Mixtral 8x7B[36] 在路由分析过程中发现token在专家选择过程中并不存在设想的同领域同专家现象,而是和位置高度相关,相邻位置的token往往会被分配给同一专家。这表明我们仍需在增强专家专业化及可解释性方面进行优化。
- 有利于专家协作且负载均衡的路由方式。MoE架构中,路由决定了专家的激活方式及专家间协作的方式。如何充分利用各专家的知识,如何根据任务难度动态决定专家激活数量,如何避免负载不均衡导致的计算资源浪费,都是MoE在路由设计上需要进一步研究的问题。
- 后训练稳定性和泛化性优化。MoE由于其复杂的结构,相较于Dense模型更容易在后训练的过程中崩溃或过拟合。当前已有研究从token丢弃、辅助损失[10]及多任务指令调整[26-27]等角度改进后训练效果。未来的工作或许可以针对MoE特性,开发新的数据迭代、微调策略。
- 提高计算效率及降低显存占用。MoE的应用很大程度受其巨大的显存需求限制。算法和硬件联合优化MoE的训练及推理速度、降低其显存需求,是MoE架构广泛应用于轻量化端侧设备的必经之路。
5. 总结
从Mixtral 8x7B[36]到GPT-4[37],再到DeepSeek-V3[2],基于MoE架构的大语言模型一次又一次引起了人工智能领域的热潮。本文从混合专家模型的背景知识开始讲起,系统梳理了学术界在负载均衡、专家专业化、动态路由等领域的研究进展,并提出了几点未来可能的研究方向,希望能为相关研究人员提供一些参考,共同推动MoE领域的进步。
6. 参考文献
[1] Kaplan J, McCandlish S, Henighan T, et al. Scaling laws for neural language models[J]. arXiv preprint arXiv:2001.08361, 2020. [2] Liu A, Feng B, Xue B, et al. Deepseek-v3 technical report[J]. arXiv preprint arXiv:2412.19437, 2024. [3] An Yang, Baosong Yang, Beichen Zhang, et al. Qwen2.5 Technical Report[J]. arXiv preprint arXiv:2412.15115, 2024. [4] Jacobs R A, Jordan M I, Nowlan S J, et al. Adaptive mixtures of local experts[J]. Neural computation, 1991, 3(1): 79-87. [5] Lepikhin D, Lee H J, Xu Y, et al. Gshard: Scaling giant models with conditional computation and automatic sharding[J]. arXiv preprint arXiv:2006.16668, 2020. [6] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30. [7] Hugging Face. Mixture of Experts Explained[EB/OL]. (2025-05-26)[2025-05-26]. https://huggingface.co/blog/zh/moe. [8] Cai W, Jiang J, Wang F, et al. A survey on mixture of experts in large language models[J]. IEEE Transactions on Knowledge and Data Engineering, 2025. [9] Fedus W, Zoph B, Shazeer N. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity[J]. Journal of Machine Learning Research, 2022, 23(120): 1-39. [10] Zoph B, Bello I, Kumar S, et al. St-moe: Designing stable and transferable sparse expert models[J]. arXiv preprint arXiv:2202.08906, 2022. [11] Kim Y J, Awan A A, Muzio A, et al. Scalable and efficient moe training for multitask multilingual models[J]. arXiv preprint arXiv:2109.10465, 2021. [12] Xue F, Zheng Z, Fu Y, et al. Openmoe: An early effort on open mixture-of-experts language models[J]. arXiv preprint arXiv:2402.01739, 2024. [13] Liu A, Feng B, Wang B, et al. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model[J]. arXiv preprint arXiv:2405.04434, 2024. [14] Wei T, Zhu B, Zhao L, et al. Skywork-moe: A deep dive into training techniques for mixture-of-experts language models[J]. arXiv preprint arXiv:2406.06563, 2024. [15] Dai D, Deng C, Zhao C, et al. Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models[J]. arXiv preprint arXiv:2401.06066, 2024. [16] Wang L, Gao H, Zhao C, et al. Auxiliary-loss-free load balancing strategy for mixture-of-experts[J]. arXiv preprint arXiv:2408.15664, 2024. [17] QwenLM. Qwen-MoE: A Cost-Effective Alternative to Dense Models with Equivalent Performance[EB/OL]. (2024-04-03)[2024-05-30]. https://qwenlm.github.io/blog/qwen-moe/. [18] Cai W, Jiang J, Qin L, et al. Shortcut-connected expert parallelism for accelerating mixture-of-experts[J]. arXiv preprint arXiv:2404.05019, 2024. [19] Snowflake Arctic [20] Yang A, Li A, Yang B, et al. Qwen3 technical report[J]. arXiv preprint arXiv:2505.09388, 2025. [21] Wang A, Sun X, Xie R, et al. Hmoe: Heterogeneous mixture of experts for language modeling[J]. arXiv preprint arXiv:2408.10681, 2024. [22] Huang Q, An Z, Zhuang N, et al. Harder tasks need more experts: Dynamic routing in moe models[J]. arXiv preprint arXiv:2403.07652, 2024. [23] Zeng Z, Miao Y, Gao H, et al. Adamoe: Token-adaptive routing with null experts for mixture-of-experts language models[J]. arXiv preprint arXiv:2406.13233, 2024. [24] Jin P, Zhu B, Yuan L, et al. Moe++: Accelerating mixture-of-experts methods with zero-computation experts[J]. arXiv preprint arXiv:2410.07348, 2024. [25] Yue T, Guo L, Cheng J, et al. Ada-k routing: Boosting the efficiency of moe-based llms[C]//The Thirteenth International Conference on Learning Representations. 2024. [26] Shen S, Hou L, Zhou Y, et al. Mixture-of-experts meets instruction tuning: A winning combination for large language models[J]. arXiv preprint arXiv:2305.14705, 2023. [27] Zhu T, Dong D, Qu X, et al. Dynamic data mixing maximizes instruction tuning for mixture-of-experts[J]. arXiv preprint arXiv:2406.11256, 2024. [28] Liu Q, Wu X, Zhao X, et al. Moelora: An moe-based parameter efficient fine-tuning method for multi-task medical applications[J]. CoRR, 2023. [29] Dou S, Zhou E, Liu Y, et al. LoRAMoE: Alleviating world knowledge forgetting in large language models via MoE-style plugin[C]//Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024: 1932-1945. [30] Gou Y, Liu Z, Chen K, et al. Mixture of cluster-conditional lora experts for vision-language instruction tuning[J]. arXiv preprint arXiv:2312.12379, 2023. [31] Liu Q, Wu X, Zhao X, et al. Moelora: An moe-based parameter efficient fine-tuning method for multi-task medical applications[J]. CoRR, 2023. [32] Gao C, Chen K, Rao J, et al. Higher layers need more lora experts[J]. arXiv preprint arXiv:2402.08562, 2024. [33] Yang S, Ali M A, Wang C L, et al. MoRAL: MoE Augmented LoRA for LLMs' Lifelong Learning[J]. arXiv preprint arXiv:2402.11260, 2024. [34] Feng W, Hao C, Zhang Y, et al. Mixture-of-loras: An efficient multitask tuning for large language models[J]. arXiv preprint arXiv:2403.03432, 2024. [35] Li D, Ma Y, Wang N, et al. Mixlora: Enhancing large language models fine-tuning with lora-based mixture of experts[J]. arXiv preprint arXiv:2404.15159, 2024. [36] Jiang A Q, Sablayrolles A, Roux A, et al. Mixtral of experts[J]. arXiv preprint arXiv:2401.04088, 2024. [37] Achiam J, Adler S, Agarwal S, et al. Gpt-4 technical report[J]. arXiv preprint arXiv:2303.08774, 2023.
编辑:杨晓亮初审:张羽,赵妍妍复审:冯骁骋终审:单既阳
哈尔滨工业大学社会计算与交互机器人研究中心
理解语言,认知社会 以中文技术,助民族复兴
