
来源:
前言
经过长时间的发展,大量的材料学术文献积累了丰富的科学成果,以文本形式散布在文献中的科学知识一般仍由研究人员手动收集和分析,这通常十分耗时且难以保证信息的完整度。如果将文献中的材料科学信息表示为结构化的知识,再结合知识关联、融合、推理等方法,构建材料知识图谱,可以使研究人员准确而又高效地获取信息,并对过往研究进行脉络梳理,对有潜力的材料进行剖析。
北京大学深圳研究生院新材料学院潘锋教授课题组近年来致力于构建材料知识图谱以及解决其关键科学问题和技术难题,发展了一套高精度且高效的同名消歧以及信息搜索框架,在材料科学领域建立主体(作者)与客体(材料)之间的对应关系,结合机器学习和依赖匹配算法,构建名为MatKG的材料知识图谱,并对锂离子电池正极材料LiFePO4进行自动化分析,生成其发展里程碑,追踪其研究趋势,相关成果已发表于《先进能源材料》(Advanced Energy Materials, DOI:10.1002/aenm.202003580)。
在此基础上,潘锋课题组进一步深入研究材料知识图谱的构建技术和应用潜力,实现了对隐藏在文本中的潜在材料关联的挖掘,进一步实现了材料的推理预测。
近日,他们在《先进功能材料》杂志(Advanced Functional Materials, DOI:10.1002/adfm.202201437)发表题为“Automating Materials Exploration with a Semantic Knowledge Graph for Li-ion Battery Cathodes”的研究论文。该研究提出了一种可实现材料科学知识嵌入的语义表示框架,通过多源信息融合提高材料实体的表示质量以对材料科学文献中的锂离子电池正极材料实体进行精准挖掘并构建正极材料知识图谱,预测高性能锂电池材料。该工作在几乎不需要领域知识的情况下,实现了复杂材料系统的基于文本挖掘的高效知识融合和推理与预测,将助力实现数据驱动的材料研究新范式。
材料科学文本中包含大量非结构化、高度异构形式的材料科学信息,并且材料子领域拥有特定的领域知识,不同子领域之间差异明显,这都对材料科学知识的精准挖掘造成了极大的挑战。由于数据驱动的材料研发新范式的应用价值,构建整合材料特性和应用信息的数据管理平台成为了目前迫切的需求,而基于文本挖掘的材料知识图谱构建及材料推理预测正是解决这一需求的重要手段。
课题组发展了一套名为DATWEM的材料信息语义表示框架,以针对性生成特定子领域的材料实体表示,解决了复杂材料系统中的材料实体挖掘问题。该框架结合BiLSTM和双重注意力机制,通过多源信息融合提高词嵌入的质量,以对材料科学文献中的特定领域材料实体进行精准挖掘。他们将该框架应用于锂离子电池正极材料领域知识图谱的构建:首先对材料科学文本信息进行向量化;接下来使用两个独立的词嵌入模块对两种不同语料库(无机材料语料库和正极材料语料库)分别进行编码,两种语料库编码后的词嵌入和关键词模块的词嵌入随后会被输入DATWEM框架经过双层注意力模块实现多源信息融合,增强材料实体的表示质量;最后量化材料实体之间的相似度以构建锂离子电池正极材料知识图谱。
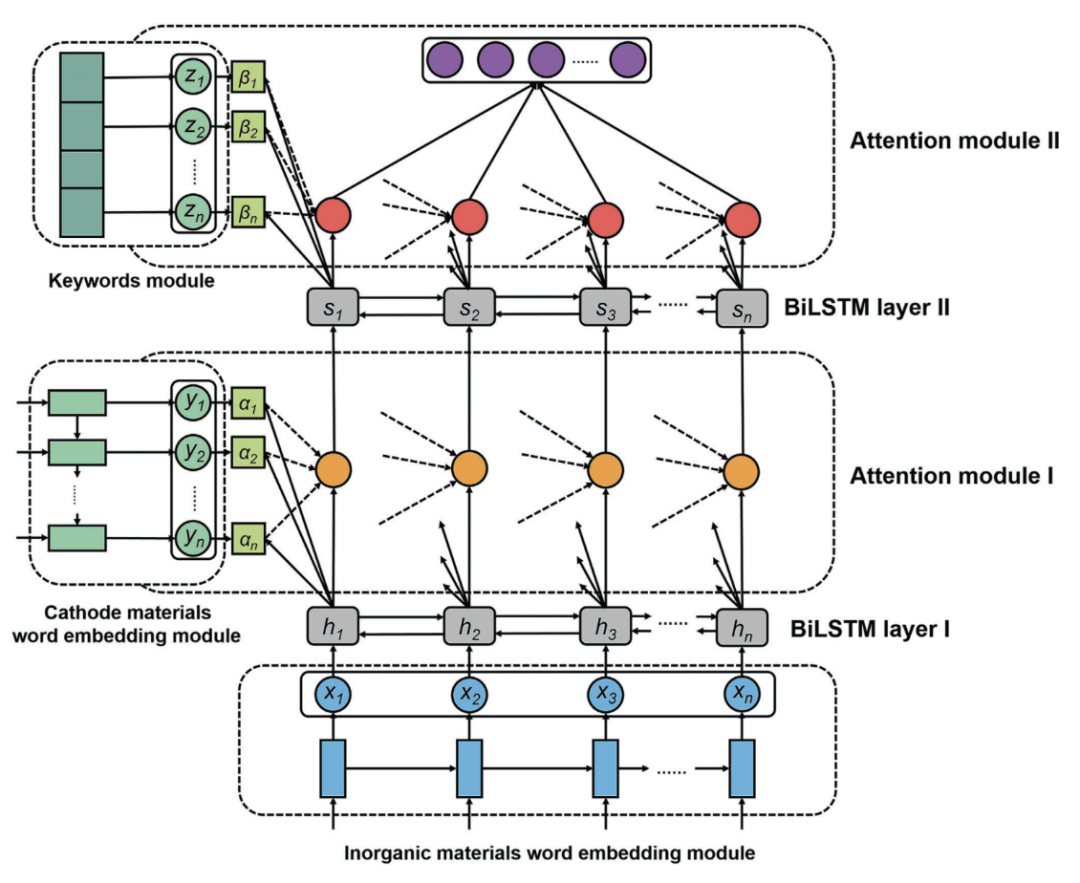
材料知识图谱的构建流程
课题组在该知识图谱的基础上进行潜在正极材料的推理预测,通过无监督聚类对不同材料之间的语义相似性进行可视化,保留与四种代表性正极材料(LiCoO2、LiFePO4、LiMn2O4、Li2MnO3)相关的较大聚类簇。在对已包含在语料库中的正极材料进行过滤后,他们发现了一种潜在的正极材料——Li2TiMn3O8,该材料与典型正极材料LiCoO2通过层状结构这一明显共同特征形成直接连接路径,通过包含适合用于正极材料的可变价元素这一潜在共同特征形成间接连接路径,从而根据直接及间接路径实现了该潜在材料的发现。
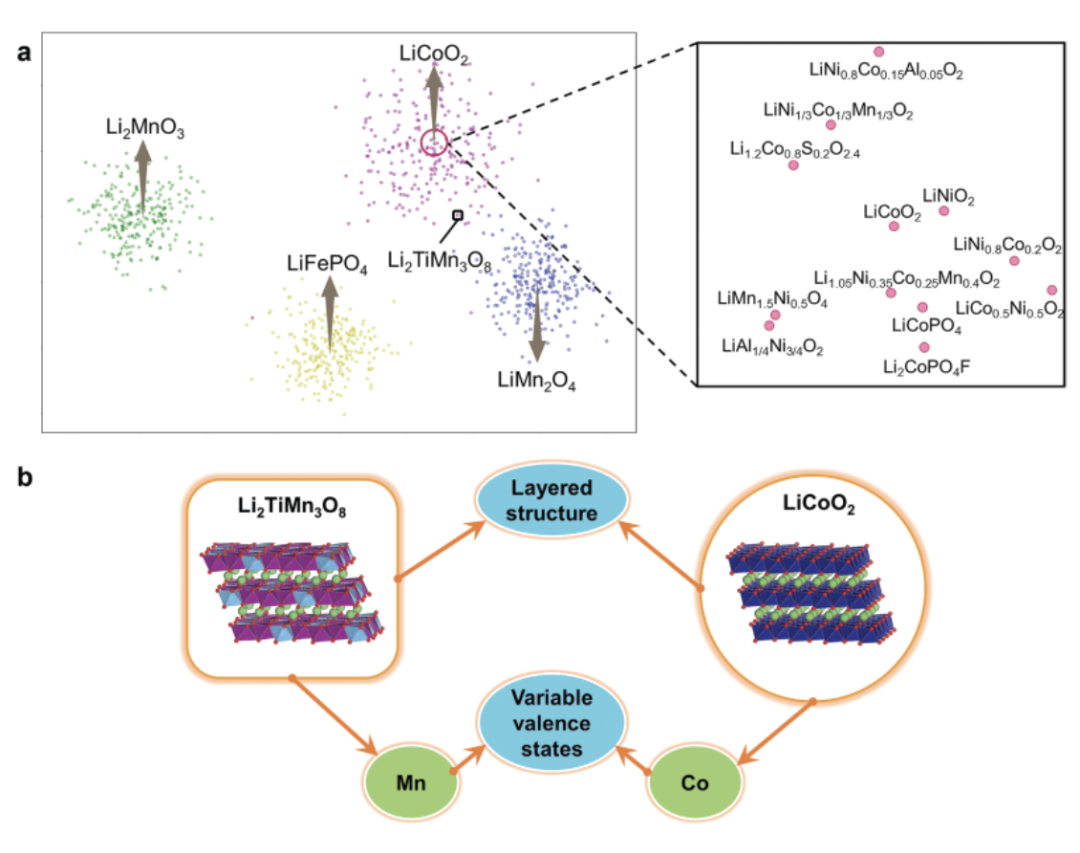
材料知识图谱用于锂电池正极材料的发现

