【知识图谱】大规模知识图谱的构建、推理及应用
随着大数据的应用越来越广泛,人工智能也终于在几番沉浮后再次焕发出了活力。除了理论基础层面的发展以外,本轮发展最为瞩目的是大数据基础设施、存储和计算能力增长所带来的前所未有的数据红利。
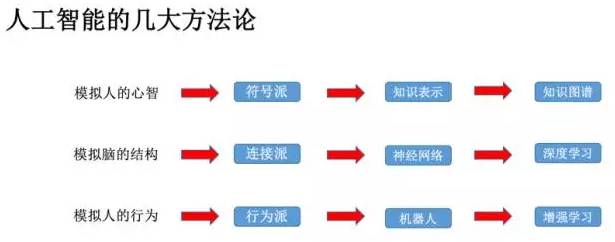
人工智能的进展突出体现在以知识图谱为代表的知识工程以及以深度学习为代表的机器学习等相关领域。
未来伴随着深度学习对于大数据的红利消耗殆尽,如果基础理论方面没有新的突破,深度学习模型效果的天花板将日益迫近。而另一方面,大量知识图谱不断涌现,这些蕴含人类大量先验知识的宝库却尚未被深度学习有效利用。
融合知识图谱与深度学习,已然成为进一步提升深度学习效果的重要思路之一。以知识图谱为代表的符号主义,和以深度学习为代表的联结主义,日益脱离原先各自独立发展的轨道,走上协同并进的新道路。
大规模知识图谱的构建
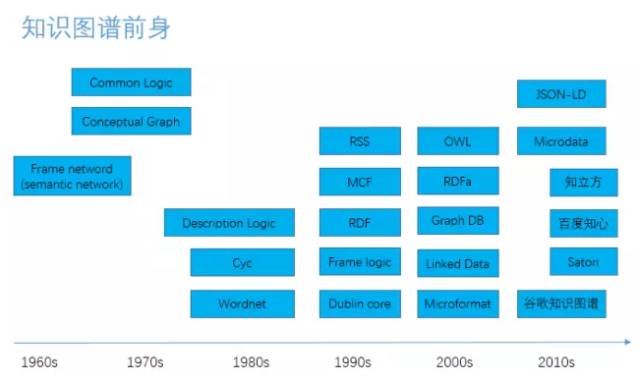
知识图谱自上世纪60年代从语义网络发展起来以后,分别经历了1980年代的专家系统、1990年代的贝叶斯网络、2000年代的OWL和语义WEB,以及2010年以后的谷歌的知识图谱。谷歌目前的知识图谱已经包含了数亿个条目,并广泛应用于搜索、推荐等领域。
知识图谱的存储和查询语言也经历了历史的洗涤,从RDF到OWL以及SPARQL查询,都逐渐因为使用上的不便及高昂的成本,而被工业界主流所遗弃。图数据库逐步成为目前主要的知识图谱存储方式。
目前应用比较广泛的图数据库包括Neo4J、graphsql、sparkgraphx(包含图计算引擎)、基于hbase的Titan、BlazeGraph等,各家的存储语言和查询语言也不尽相同。实际应用场景下,OrientDB和postgresql也有很多的应用,主要原因是其相对低廉的实现成本和性能优势。
由于大规模知识图谱的构建往往会有众多的实体和关系需要从原始数据(可以是结构化也可以是非结构化)中被抽取出来,并以图的方式进行结构化存储,而我们依赖的原始数据往往存在于多源异构的环境中,所以进行海量知识抽取和融合,就成了首要的无法回避的严峻问题。
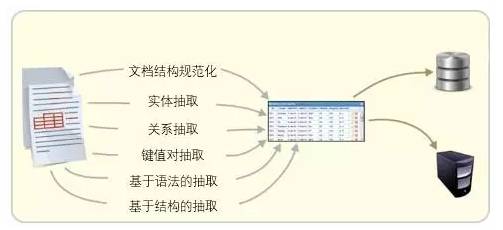
对于结构化的数据转换为图结构是比较容易和相对轻松的工程,所以建议这一步应该首先被完成。
对于复杂的非结构化数据,现阶段进行知识图谱构建的主要方法有传统NLP和基于深度学习模型两类方法,而目前越来越多倾向于使用深度学习来抽取AVP(属性-值对)。
有很多深度学习模型可以用来完成端到端的包括命名实体识别NER、关系抽取和关系补全等任务,从而构建和丰富知识图谱。
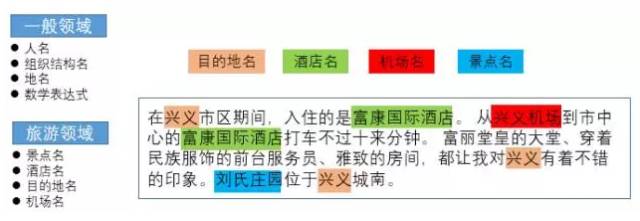
命名实体识别(Named Entity Recognition, NER)是从一段非结构化文本中找出相关实体(triplet中的主词和宾词),并标注出其位置以及类型,它是NLP领域中一些复杂任务(如关系抽取、信息检索等)的基础。
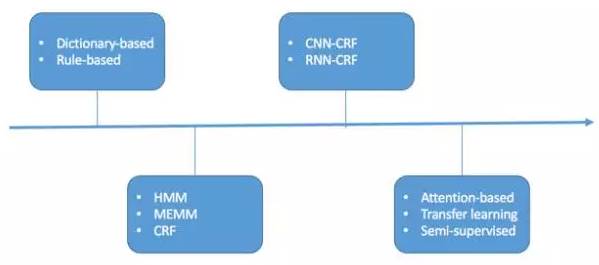
NER一直是NLP领域的热点,从早期基于字典和规则的方法,到传统机器学习的方法,再到近年来基于深度学习的方法,NER方法的大致演化如下所示。
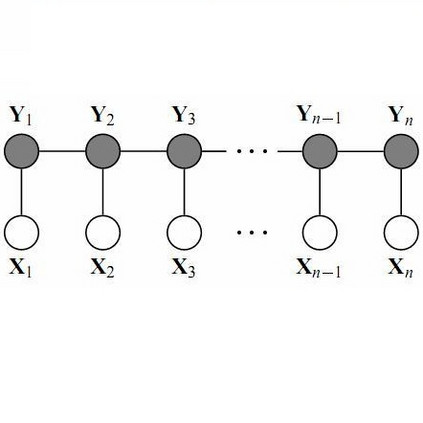
在机器学习中,NER被定义为序列标注问题。不同于分类问题,序列标注问题中的预测标签不仅与输入特征有关,还与之前的预测标签有关,也就是预测标签之间存在相互依赖和影响。
条件随机场(Conditional Random Field,CRF)是序列标注的主流模型。它的目标函数不仅考虑输入的状态特征函数,还包含了标签转移特征函数。在训练的时候可以使用SGD学习参数。在预测时,可以使用Vertibi算法求解使目标函数最大化的最优序列。
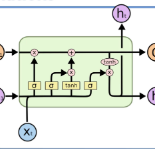
目前常见的基于深度学习的序列标注模型有BiLSTM-CNN-CRF。它主要由Embedding层(词向量、字向量等)、BiLSTM、tanh隐藏层以及CRF层组成(对于中文可以不需要CNN)。我们的实验表明BiLSTM-CRF可以获得较好的效果。在特征方面,由于秉承了深度学习的优点,所以无需特征工作的铺垫,使用词向量及字向量就可以得到不错的效果。
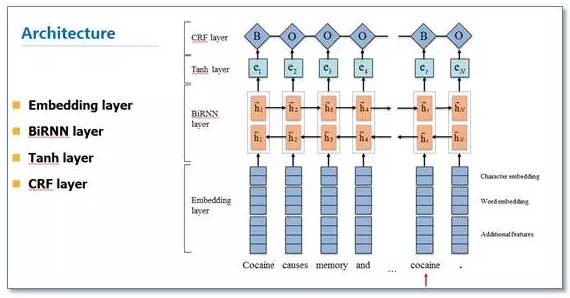
近几个月来,我们也在尝试使用Attention机制,以及仅需少量标注样本的半监督来进行相应的工作。
在BiLSTM-CRF的基础上,使用Attention机制将原来的字向量和词向量的拼接改进为按权重求和,使用两个隐藏层来学习Attention的权值,这样使得模型
可以动态地利用词向量和字向量的信息。同时加入NE种类的特征,并在字向量上使用Attention来学习关注更有效的字符。实验效果优于BiLSTM-CRF的方法。
这里之所以用了大量篇幅来说NER的深度学习模型,是因为关系抽取模型也是采用同样的模型实现的,其本质也是一个序列标注问题。所以这里不再赘述。
知识图谱构建中的另外一个难点就是知识融合,即多源数据融合。融合包括了实体对齐、属性对齐、冲突消解、规范化等。对于Open-domain这几乎是一个举步维艰的过程,但是对于我们特定旅游领域,可以通过别名举证、领域知识等方法进行对齐和消解,从技术角度来看,这里会涉及较多的逻辑,所以偏传统机器学习方法,甚至利用业务逻辑即可覆盖大部分场景。
知识图谱schema是知识的分类体系的表现,还可以用于逻辑推理,也是用于冲突检测的方法之一,从而提高知识图谱的质量。
总而言之,构建知识图谱没有统一的方法,因为其构建需要一整套知识工程的方法,需要用到NLP、ML、DL技术,用到图数据库技术,用到知识表示推理技术等。知识图谱的构建就是一个系统工程,而且知识的更新也是不可避免的,所以一定要重视快速迭代和快速产出检验。
知识图谱的推理
在知识图谱构建过程中,还存在很多关系补全问题。虽然一个普通的知识图谱可能存在数百万的实体和数亿的关系事实,但相距补全还差很远。知识图谱的补全是通过现有知识图谱来预测实体之间的关系,是对关系抽取的重要补充。传统方法TransE和TransH通过把关系作为从实体A到实体B的翻译来建立实体和关系嵌入,但是这些模型仅仅简单地假设实体和关系处于相同的语义空间。而事实上,一个实体是由多种属性组成的综合体,不同关系关注实体的不同属性,所以仅仅在一个空间内对他们进行建模是不够的。

因此我们尝试用TransR来分别将实体和关系投影到不同的空间中,在实体空间和关系空间构建实体和关系嵌入。对于每个元组(h,r,t),首先将实体空间中的实体通过Mr向关系r投影得到hr和tr,然后是hr+r ≈tr。特定的关系投影能够使得两个实体在这个关系下真实地靠近彼此,使得不具有此关系的实体彼此远离。

知识图谱推理中还经常将知识图谱表示为张量tensor形式,通过张量分解(tensor factorization)来实现对未知事实的判定。常用于链接预测(判断两个实体之间是否存在某种特定关系)、实体分类(判断实体所属语义类别)、实体解析(识别并合并指代同一实体的不同名称)。
常见的模型有RESCAL模型和TRESCAL模型。
RESCAL模型的核心思想,是将整个知识图谱编码为一个三维张量,由这个张量分解出一个核心张量和一个因子矩阵,核心张量中每个二维矩阵切片代表一种关系,因子矩阵中每一行代表一个实体。由核心张量和因子矩阵还原的结果被看作对应三元组成立的概率,如果概率大于某个阈值,则对应三元组正确;否则不正确。
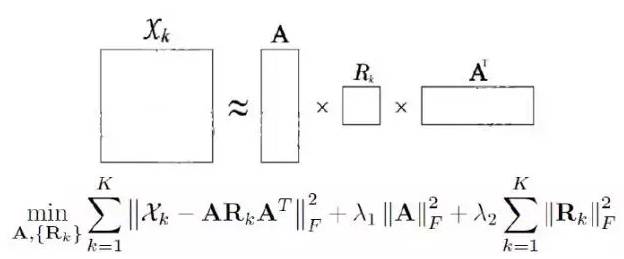
而TRESCAL则是解决在输入张量高度稀疏时所带来的过拟合问题。
路径排序算法也常用来判断两个实体之间可能存在的关系,比如PRA算法。本文不展开描述。
大规模知识图谱的应用
知识图谱的应用场景非常广泛,比如搜索、问答、推荐系统、反欺诈、不一致性验证、异常分析、客户管理等。由于以上场景在应用中出现越来越多的深度学习模型,因此本文主要讨论知识图谱在深度学习模型中的应用。
目前将知识图谱用于深度学习主要有两种方式:
一种是将知识图谱的语义信息输入到深度学习模型中,将离散化的知识表示为连续化的向量,从而使得知识图谱的先验知识能够称为深度学习的输入;
另外一种是利用知识作为优化目标的约束,指导深度学习模型的学习过程,通常是将知识图谱中的知识表示为优化目标的后验正则项。
知识图谱的表示学习用于学习实体和关系的向量化表示,其关键是合理定义知识图谱中关于事实(三元组h,r,t)的损失函数fr(h,t),其总和是三元组的两个实体h和t的向量化表示。通常情况下,当事实h,r,t成立时,期望最小化fr(h,t)。

常见的有基于距离和翻译的模型。
基于距离的模型,比如SE模型,其基本思想是当两个实体属于同一个三元组时,它们的向量表示在投影后的空间中也应该彼此靠近。所以损失函数定义为向量投影后的距离

其中矩阵Wr1和Wr2用于三元组中头实体h和尾实体t的投影操作。
基于翻译的模型可以参考前述的TransE, TransH和TransR模型。其通过向量空间的向量翻译来描述实体与关系之间的相关性。
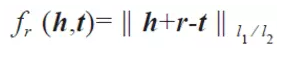
当前的知识图谱表示学习方法都还存在各种问题,这个领域的发展也非常迅速,值得期待。
知识图谱的表示转换后,根据不同领域的应用,就可以和各种深度学习模型相结合,比如在自动问答领域,可以和encoder-decoder相结合,将问题和三元组进行匹配,即计算其向量相似度,从而为某个特定问题找到来自知识图谱的最佳三元组匹配。也有案例在推荐系统中,通过网络嵌入(network embedding)获取结构化知识的向量化表示,然后分别用SDAE(Stacked Denoising Auto-Encoder)和层叠卷积自编码器(StackedConvolutional Auto-Encoder)来抽取文本知识特征和图片知识特征,并将三类特征融合进协同集成学习框架,利用三类知识特征的整合来实现个性化推荐。
随着深度学习的广泛应用,如何有效利用大量先验知识,来大大降低模型对大规模标注语料的依赖,也逐渐成为主要的研究方向之一。在深度学习模型中融合常识知识和领域知识,将是又一大机遇和挑战。
来源:携程技术中心
延展阅读:DeepMind 关系推理网络大揭秘(附论文)
将门创投
来源:Medium
论文>>https://arxiv.org/pdf/1706.01427.pdf
什么是关系推理(Relational Reasoning)?
用最简单的话来解释,关系推理可以学习并理解不同事物(概念)之间的联系。这可以看做是智能的本质特征之一。下面是作者给出的示意图解释了关系推理的内涵:

模型通过观察不同主体的外形、大小、颜色后,可以回答主体之间不同关系的问题。
一些之前的文章,对于理解这个网络有很大的帮助:
Inferring and Executing Programs for Visual Reasoning
https://arxiv.org/abs/1705.03633
Simple Baseline for Visual Question Answering
https://arxiv.org/abs/1512.02167
Neural Module Networks
https://arxiv.org/abs/1511.02799
以及视觉数据集CLEVR
http://cs.stanford.edu/people/jcjohns/clevr/
关系网络(Relational Networks)
在这篇文章中,作者呈现出了一种可以用于提取事物间关系性的神经网络(就像卷积神经网络可以用来提取图像特征一样):
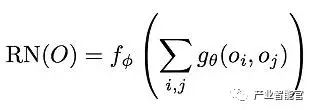
等式1. 关系网络的定义
相关解释:
关系网络对于O(是一系列你希望学习他们相关性的主体)来说是一个函数fɸ;
gθ 是用于计算两个物体之间相关性的函数;
Σ i, j 计算所有可能的物体对之间的关系并相加。
神经网络和函数
在我们学习神经网络、bp算法等时候经常会忘记神经网络的本质其实就是一个简单的数学函数。我们上面解释的函数其实描述的就是神经网络,更准确的说,其中包含两个神经网络:
gθ 用于计算物体之间的关系;
fɸ 用于计算所有物体关系的和,并最终计算模型的输出;
在最简单的情况下gθ ,fɸ可以是多层感知机。
关系神经网络十分灵活
论文的作者将关系神经网络看做是一个模块。它可以接收编码过的物体并学习物体之间的关系,更重要的是它可以作为模块插入到卷积神经网络CNN和长短时记忆网络LSTM中去。
CNN可以用图像进行学习,这使得这项技术应用更为广泛。毕竟利用图像进行推理比利用一系列定义好的物体进行推理更为方便和实用。
同样LSTM可以用来理解输入序列的含义。那么使用这种技术可以使得LSTM可以直接接收自然语言的句子而不是一系列编码过的序列。
作者为我们提供了一些示例来演示如何将关系网络与卷积神经网络以及长短时记忆网络结合起来,建立能学习物体间相互关系的端到端神经网络。

图2.0 端到端的关系推理网络
相关解释
首先利用标准的卷积神经网络从图像中抽取特征。得到了每一个物体用一个特征矢量表示,如上图中的黄色矢量所示。
同时利用LSTM来处理问题,并生成问题的特征矢量,得到了问题的基本内涵。
这时我们需要稍微修改一下先前的公式,并在其中加入了一项新的q。
在LSTM条件下的相关性网络。
其中而外加入的q代表LSTM输出的最终状态,现在的相关性变成了q条件下的相关性了。
随后CNN中提取出特征的“物体”与LSTM提取出的矢量被用于训练相关性网络。每一个物体和对应的LSTM矢量成对的输入到神经网络中用于训练gθ。
最后将gθ加起来作为fɸ的输入,来训练用于最终回答问题的神经网络。
Benchmarks
作者在论文中展示了了这一模型在多个数据集上的有效性。其中CLEVR数据集包含了很多个不同形状、大小和颜色的物体。对模型的提问类似于这样:
“图中圆柱和立方体是同一种材料吗?”

作者在论文中表示这一模型的精度要远高于其他的模型,这主要是由于这一模型就是为采集物体间相关性而设计的。这一模型达到了>96%的准确率,而利用注意力模型的仅仅只有75%的准确率。

结 论
关系网络十分适用于学习不同主体间相关性。它不仅表现在数据的有效性上,更表现在可以广泛用于CNN和LSTMs等网络中的灵活性上。希望这篇文章能为各位呈现深度学习最新的发展状况。
-END-

新一代技术+商业操作系统:
AI-CPS OS
在新一代技术+商业操作系统(AI-CPS OS:云计算+大数据+物联网+区块链+人工智能)分支用来的今天,企业领导者必须了解如何将“技术”全面渗入整个公司、产品等“商业”场景中,利用AI-CPS OS形成数字化力量,实现行业的重新布局、企业的重新构建和自我的焕然新生,在行业、企业和自身三个层面勇立鳌头。
分辨率革命:这种力量能够使人在更加真实、细致的层面观察与感知现实世界和数字化世界正在发生的一切,进而理解和更加精细地进行产品控制、事件控制和结果控制。
复合不确定性:数字化变更颠覆和改变了领导者曾经仰仗的思维方式、结构和实践经验,其结果就是形成了复合不确定性这种颠覆性力量。主要的不确定性蕴含于三个领域:技术、文化、制度。
边界模糊化:数字世界与现实世界的不断融合成CPS不仅让人们所知行业的核心产品、经济学定理和可能性都产生了变化,还模糊了不同行业间的界限。这种效应正在向生态系统、企业、客户、产品快速蔓延。
给决策制定者和商业领袖的建议:
超越自动化,开启新创新模式:利用具有自主学习和自我控制能力的动态机器智能,为企业创造新商机;
迎接新一代信息技术,迎接人工智能:无缝整合人类智慧与机器智能,重新
评估未来的知识和技能类型;
制定道德规范:切实为人工智能生态系统制定道德准则,并在智能机器的开
发过程中确定更加明晰的标准和最佳实践;
重视再分配效应:对人工智能可能带来的冲击做好准备,制定战略帮助面临
较高失业风险的人群;
开发人工智能型企业所需新能力:员工团队需要积极掌握判断、沟通及想象力和创造力等人类所特有的重要能力。对于中国企业来说,创造兼具包容性和多样性的文化也非常重要。
子曰:“君子和而不同,小人同而不和。” 《论语·子路》云计算、大数据、物联网、区块链和 人工智能,像君子一般融合,一起体现科技就是生产力。
如果说上一次哥伦布地理大发现,拓展的是人类的物理空间。那么这一次地理大发现,拓展的就是人们的数字空间。在数学空间,建立新的商业文明,从而发现新的创富模式,为人类社会带来新的财富空间。云计算,大数据、物联网和区块链,是进入这个数字空间的船,而人工智能就是那船上的帆,哥伦布之帆!
新一代技术+商业操作系统(AI-CPS OS:云计算+大数据+物联网+区块链+人工智能)作为新一轮产业变革的核心驱动力,将进一步释放历次科技革命和产业变革积蓄的巨大能量,并创造新的强大引擎。重构生产、分配、交换、消费等经济活动各环节,形成从宏观到微观各领域的智能化新需求,催生新技术、新产品、新产业、新业态、新模式。引发经济结构重大变革,深刻改变人类生产生活方式和思维模式,实现社会生产力的整体跃升。
产业智能官 AI-CPS
用新一代技术+商业操作系统(AI-CPS OS:云计算+大数据+物联网+区块链+人工智能),在场景中构建状态感知-实时分析-自主决策-精准执行-学习提升的认知计算和机器智能;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。


长按上方二维码关注微信公众号: AI-CPS,更多信息回复:
新技术:“云计算”、“大数据”、“物联网”、“区块链”、“人工智能”;新产业:“智能制造”、“智能驾驶”、“智能金融”、“智能城市”、“智能零售”;新模式:“案例分析”、“研究报告”、“商业模式”、“供应链金融”、“财富空间”。
本文系“产业智能官”(公众号ID:AI-CPS)收集整理,转载请注明出处!
版权声明:由产业智能官(公众号ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源。部分文章推送时未能与原作者取得联系。若涉及版权问题,烦请原作者联系我们,与您共同协商解决。联系、投稿邮箱:erp_vip@hotmail.com