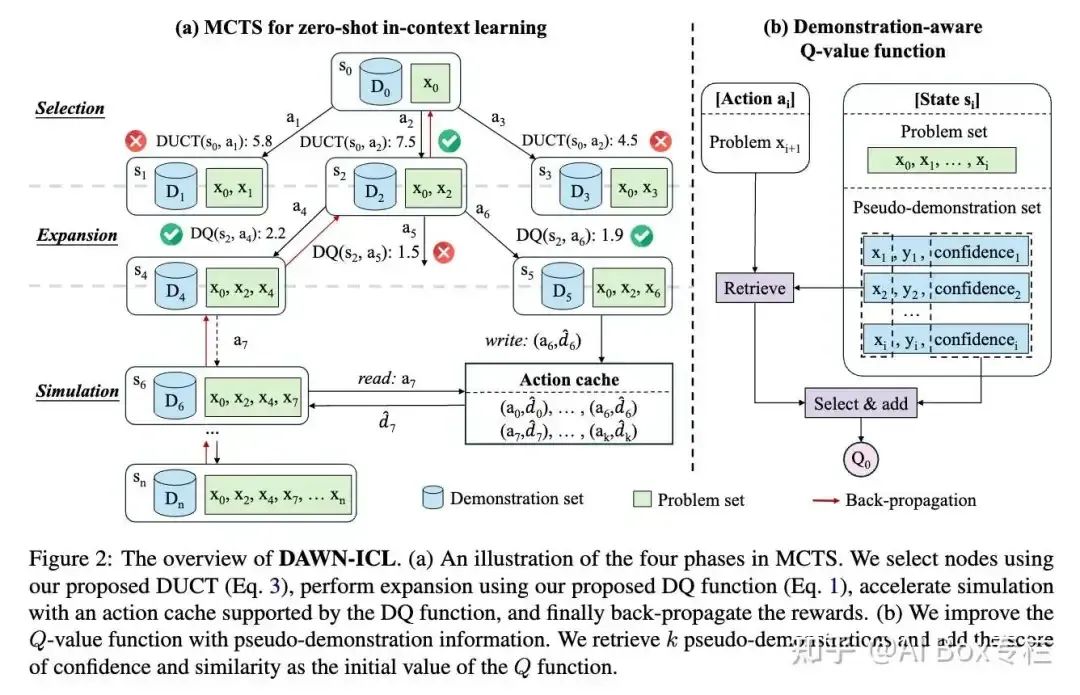
© 作者|李依凡 机构|中国人民大学研究方向|多模态大模型 多模态大模型(Multimodal Large Language Models, MLLMs)在视觉问答、OCR等诸多多模态任务上取得了令人印象深刻的表现。然而,已有MLLMs仍然会生成和视觉内容不一致的回复,即幻觉现象(Hallucination)。为了解决MLLMs的幻觉问题,学术界提出了多种缓解方法。本文将介绍三类主流的多模态幻觉缓解方法,即基于数据、基于解码以及基于人类偏好对齐的幻觉缓解方法。 文章也同步发布在 AI Box 知乎专栏(知乎搜索 AI Box 专栏),欢迎大家在知乎专栏的文章下方评论留言,交流探讨!
基于数据的幻觉缓解方法
数据质量是影响多模态大模型幻觉的重要原因之一。LRV-Instruction[1]注意到已有多模态大模型在回答用户提问时有过度做出肯定回答的倾向,即使问题内容和图像内容并不一致。作者认为这是由于已有的多模态指令数据集大部分只包含了肯定形式的指令,使得模型倾向于迎合用户的问题,而非基于图片内容做出回答。作者进而提出了包含否定形式指令的视觉指令集LRV-Instruction,其否定形式指令的示例如下图所示,具体包括(1)Nonexistent Object Manipulation: 向视觉输入中增加不存在的物体、属性、交互关系等内容,(2)Existent Object Manipulation:修改图片中已存在物体的属性, (3)Knowledge Manipulation:修改指令中知识相关内容。作者基于已有MLLMs架构(如MiniGPT-4)测试了LRV-Instruction的微调效果,发现模型的幻觉现象有所缓解。

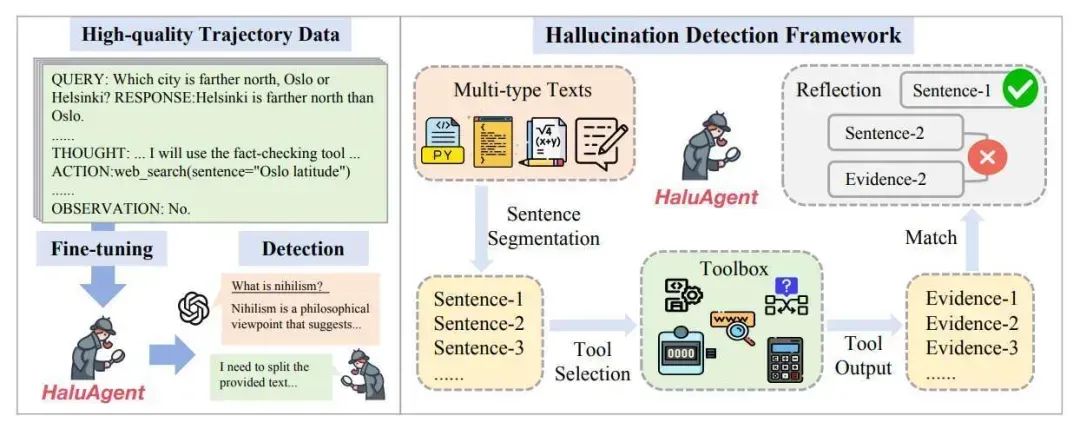
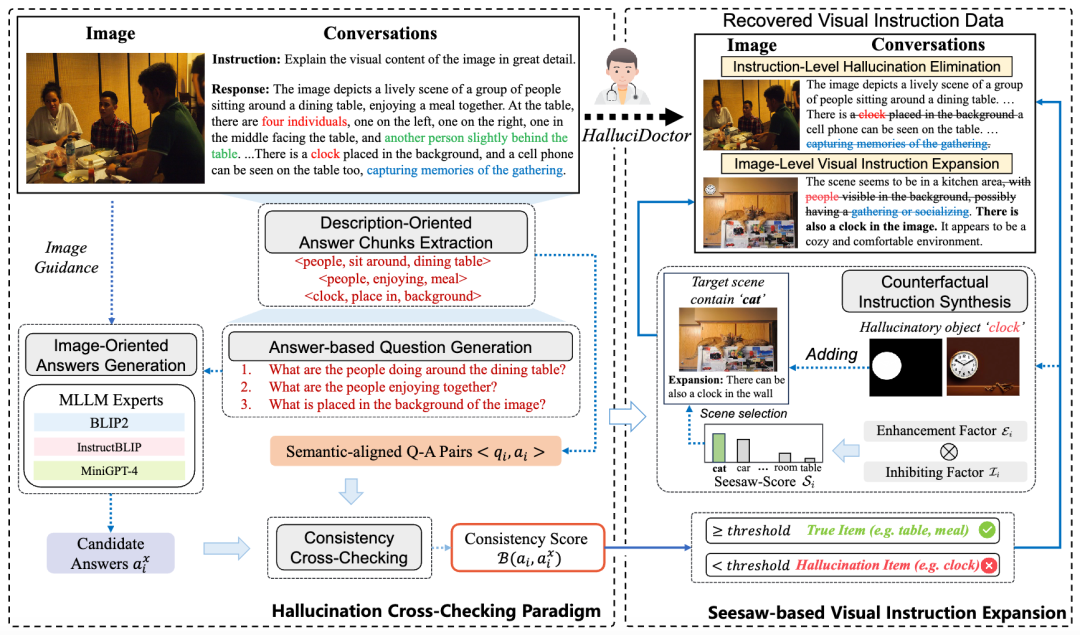
HalluciDoctor[2]通过校准指令微调数据集以缓解MLLMs的幻觉。HalluciDoctor 将首先设计了一种幻觉检测流程,其分为以下三个子过程:(1)答案片段提取:通过文本场景图解析提取所有答案片段,包括对象、关系和属性,作为描述导向的答案。(2)基于答案的问题生成:为每个答案生成对应的多类型细粒度问题。(3)一致性交叉检查:从多个 MLLM 获取面向图像的候选答案,并交叉检查描述导向答案片段与其对应的图像导向答案之间的一致性。随后,HalluciDoctor 将一致性分数低于阈值的语义片段标记为幻觉片段。通过消除这些幻觉错误,同时保持上下文语义不被破坏,从而生成校正后的数据集。作者进一步提出,训练数据中的长尾分布和对象共现是导致幻觉的两个主要因素,并提出了一种反事实视觉指令生成策略来扩展数据集。通过使用这些方法,指令微调数据集可以实现平衡并减少幻觉现象。
基于解码的幻觉缓解方法
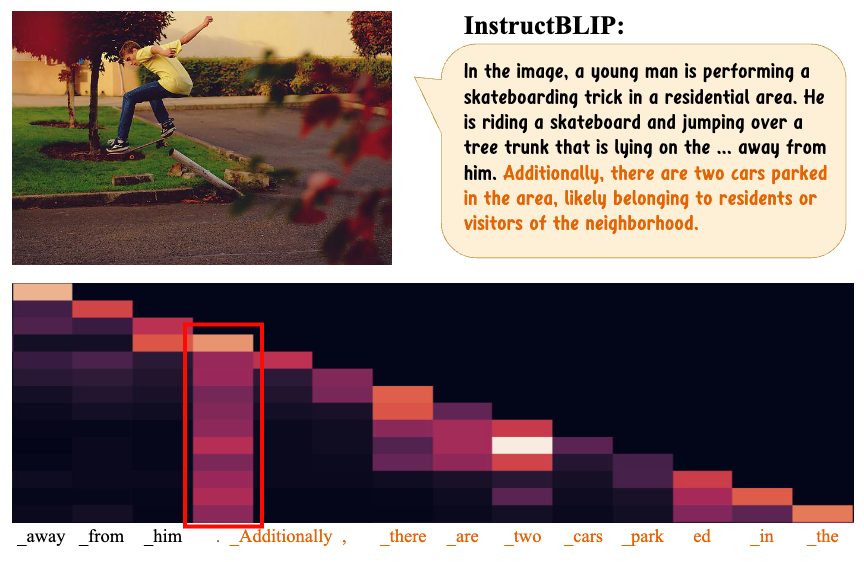
另一些方法专注于干涉模型的解码阶段,这些方法普遍不需要对模型的进一步训练,能够高效地缓解模型的幻觉问题。VCD[3]提出,MLLMs内部的语言先验是导致模型产生幻觉的重要原因之一。而当模型的视觉输入更难以辨认时,模型的生成结果会更依赖语言先验。因此,VCD提出在模型的解码阶段对视觉输入进行失真处理,并将其输出分布和原始输入的输出分布进行对比,从而减少模型对统计偏差和语言先验的过度依赖。 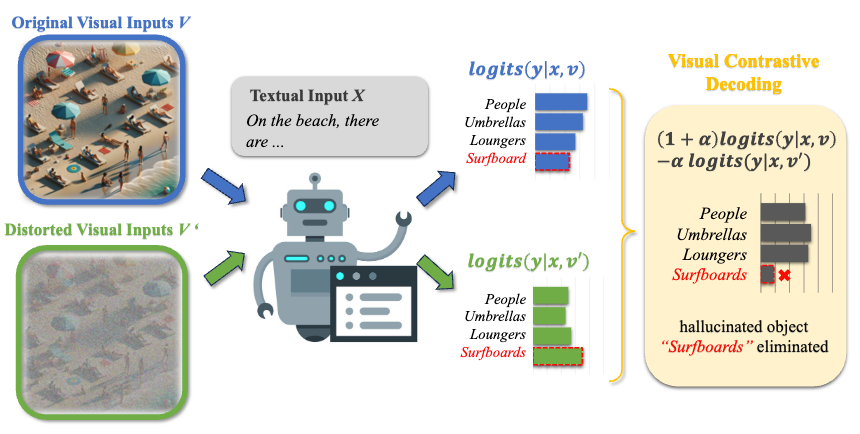
基于人类偏好对齐的幻觉缓解方法
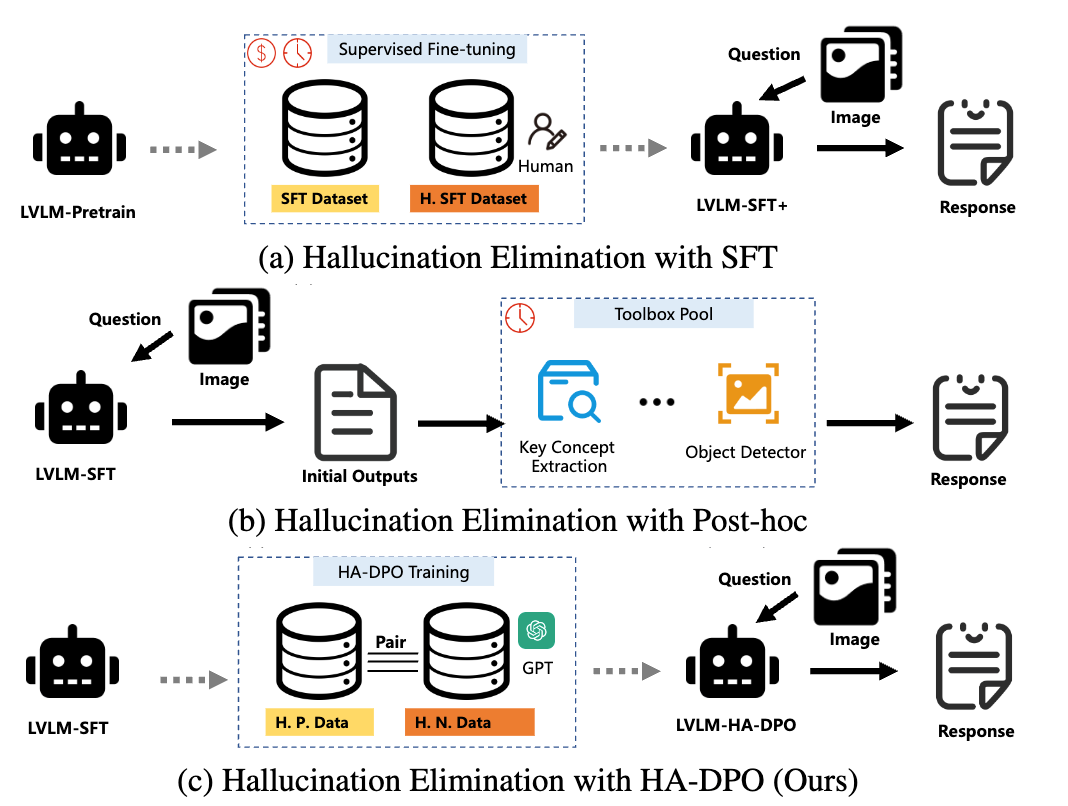
RLHF,DPO等人类偏好对齐算法在LLM上被证明十分有效。一些工作也将其应用于MLLM上用于减少幻觉的产生。HA-DPO[5]将幻觉问题重新定义为偏好选择任务。具体而言,模型在训练中通过对比同一图像的两个回答(一个准确,一个包含幻觉),被优化为倾向选择无幻觉的回答。为了实现这一目标,HA-DPO 首先构建了一个高质量的数据集。具体而言,它首先利用多模态大语言模型(MLLMs)生成与图像对应的描述,然后使用 GPT-4 检测这些描述中是否存在幻觉现象。如果检测到幻觉,描述将被重写。接下来,HA-DPO 使用这些样本对,通过直接偏好优化算法(DPO)训练模型,使其能够区分准确描述和幻觉描述。
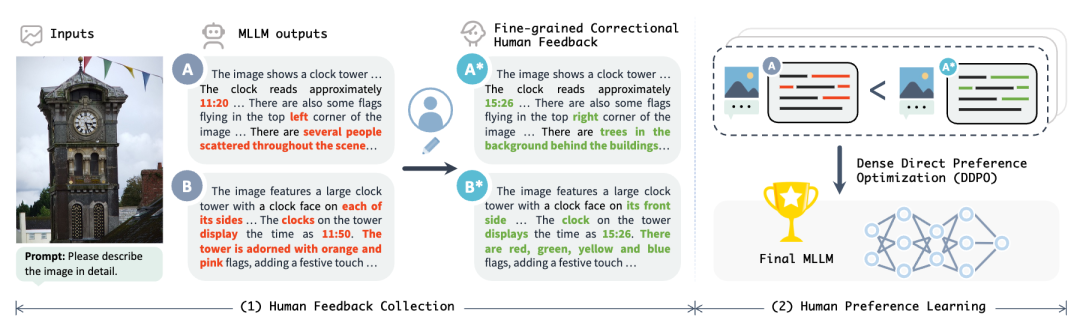
RLHF-V[6]认为多模态场景下的人类偏好优化面临两个挑战:(1)注释模糊性:关于图像内容的回复往往较长且复杂,通常很难决定哪个回应更为优选。此外,即使标注了明确的偏好,最佳回应仍然是未知的。(2) 学习效率:传统的粗粒度的排名反馈使得很难精确地分配对理想行为的奖励。考虑到回应的语言复杂性和多样性,理想的行为通常需要大量的标注数据才能学习。此外,将奖励误分配给与数据相关的非稳健偏差,通常会导致奖励操控和行为退化问题。因此RLHF-V提出在数据层面以细粒度的段级纠正形式收集人类反馈,要求人类注释员直接纠正模型回应中的幻觉段落,从而提供明确、密集且细致的人类偏好反馈。另外作者还针对传统的DPO进行了优化,提出了DDPO,直接使用细粒度的段级偏好优化策略模型,其中幻觉段落会获得更强的反馈。
参考文献 [1]Liu F, Lin K, Li L, et al. Aligning large multi-modal model with robust instruction tuning[J]. arXiv preprint arXiv:2306.14565, 2023. [2]Yu Q, Li J, Wei L, et al. Hallucidoctor: Mitigating hallucinatory toxicity in visual instruction data[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024: 12944-12953. [3]Leng S, Zhang H, Chen G, et al. Mitigating object hallucinations in large vision-language models through visual contrastive decoding[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024: 13872-13882. [4]Huang Q, Dong X, Zhang P, et al. Opera: Alleviating hallucination in multi-modal large language models via over-trust penalty and retrospection-allocation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024: 13418-13427. [5]Zhao Z, Wang B, Ouyang L, et al. Beyond hallucinations: Enhancing lvlms through hallucination-aware direct preference optimization[J]. arXiv preprint arXiv:2311.16839, 2023. [6]Yu T, Yao Y, Zhang H, et al. Rlhf-v: Towards trustworthy mllms via behavior alignment from fine-grained correctional human feedback[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024: 13807-13816.