

多模态大语言模型(MLLMs)为预训练的大语言模型(LLMs)赋予了视觉能力。尽管LLMs中的文本提示已被广泛研究,视觉提示则为更细粒度和自由形式的视觉指令开辟了新天地。本文首次全面调研了MLLMs中的视觉提示方法,重点讨论视觉提示、提示生成、组合推理和提示学习。我们对现有的视觉提示进行分类,并讨论用于自动标注图像的生成方法。同时,我们考察了使视觉编码器与基础LLMs更好对齐的视觉提示方法,涉及MLLM的视觉基础、对象引用和组合推理能力。此外,我们总结了改善MLLM对视觉提示的感知和理解的模型训练及上下文学习方法。本文探讨了在MLLMs中开发的视觉提示方法,并展望了这些方法的未来。
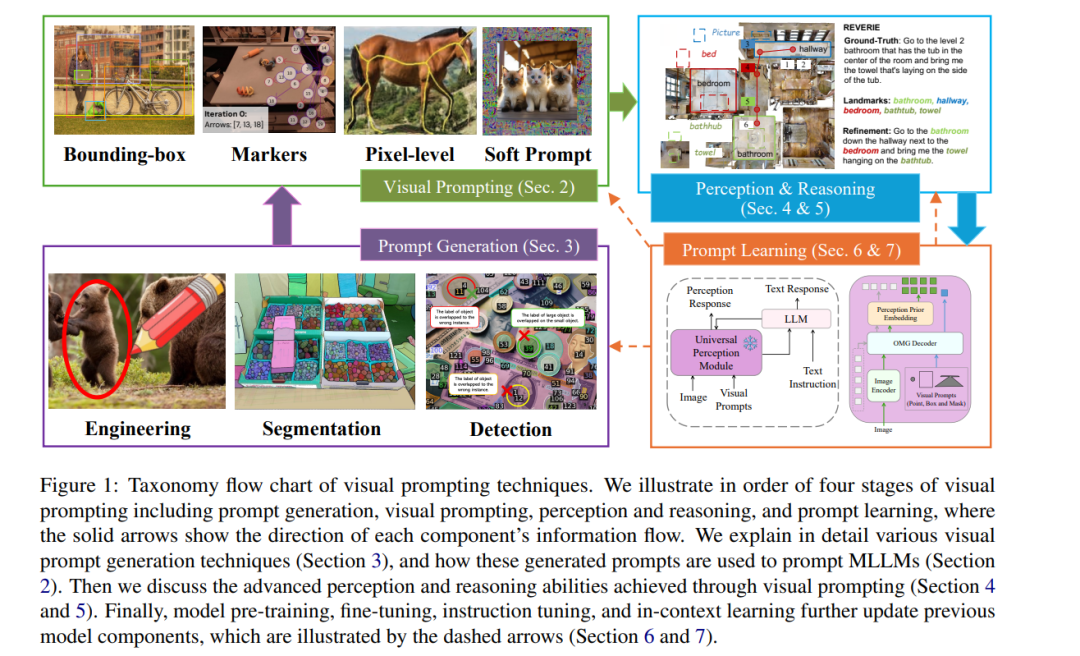
引言
多模态大语言模型(MLLMs)增强了预训练的大语言模型(LLMs)以实现视觉能力,从而在复杂的多模态任务上实现视觉理解和推理。然而,由于使用文本提示描述和指定视觉元素的局限性,传统提示方法在提供准确的视觉基础和详细视觉信息的引用上表现不佳,这可能导致视觉幻觉和语言偏见。 最近,视觉提示方法作为一种新范式应运而生,补充了文本提示,使得在多模态输入上能够进行更细粒度和像素级的指令。由于视觉提示方法可以采取多种形式,且常常在像素级粒度上操作,通用的提示模板可能不适用于不同的图像,这使得实例级视觉提示生成变得必要。因此,我们在第二部分提供了当前视觉提示方法的全面分类,并在第三部分介绍了生成这些视觉提示的方法。
尽管视觉提示方法在增强MLLM的视觉能力方面取得了成功,但一些研究表明,MLLM与视觉提示之间可能存在不一致,因为预训练阶段缺乏异构视觉提示训练数据。这种不一致可能导致MLLM忽视或误解某些视觉提示,从而引发幻觉问题。因此,我们总结了现有的将视觉提示与MLLM感知和推理对齐的努力,以实现更可控的组合推理。此外,我们考察了现有的预训练、微调和上下文学习方法,这些方法从根本上使MLLM与多模态增强提示对齐。现有的LLM提示相关文献主要限于文本提示设计和上下文演示,缺乏对像素级指令和多模态交互的文献覆盖。尽管视觉提示在计算机视觉中也有研究,但相关调研限于视觉任务和视觉骨干模型,而涉及MLLM的多模态感知和推理任务尚缺乏。此外,最近的一项关于“Segment Anything Models”(SAM)的调研探讨了SAM在MLLM中的多种应用,但仅限于SAM模型,缺乏对多样视觉提示方法的全面研究。本文首次对MLLM中的视觉提示进行全面调研,以填补这些空白,扩展对视觉提示生成、多模态提示、感知与推理及提示学习的理解。我们在图1中展示了调研的分类,并总结了我们的贡献如下: * 提供了MLLM中视觉提示和提示生成方法的全面分类。 * 解释了视觉提示如何融入MLLM的感知与推理,促进更可控的组合推理,帮助防止幻觉和语言偏见问题。 * 总结了MLLM与视觉提示对齐的方法,包括模型训练和上下文学习,解决误解问题,并提出更可控组合推理的策略。
2 视觉提示分类
视觉提示是多模态大语言模型(MLLMs)中的重要工具,指导模型解读和处理视觉数据。这些提示(Wu et al., 2024f)可以采取多种形式,如边界框、标记、像素级提示和软提示。它们提供额外的信息,以增强模型的视觉感知能力。通过使用不同的技术处理图像和视频,视觉提示提高了模型在复杂理解和推理任务中的表现。
**2.1 边界框
边界框用于标记图像中的物体或区域,使得 MLLMs 能够提取视觉特征(Lin et al., 2024a)。这些特征帮助模型理解图像内容并与相应文本关联,从而增强细粒度和基于内容的图像理解。先前的研究,如 Shikra Chen et al. (2023b) 和 VTPrompt Jiang et al. (2024),量化边界框以数值表示关键物体,建模输入和输出位置。其他方法针对特定任务修改边界框:A3VLM Huang et al. (2024a) 使用 3D 边界框定位图像中的可操作部分,CityLLaVA Duan et al. (2024) 扩大边界框,而 TextCoT Luan et al. (2024) 将边界框的短边延伸以匹配长边,确保它涵盖整个感兴趣区域。此外,CRG Wan et al. (2024) 用黑色像素遮盖特定区域以减少先验,提供了一种在不增加训练的情况下修正预测的方法。Groma Ma et al. (2024a) 和 InstructDET Dang et al. (2023) 将用户指定的区域(即边界框)编码为视觉标记,通过将其直接整合到用户指令中增强 MLLMs 的定位能力。另一个框架 Lin et al. (2024b) 通过在边界框内整合外部知识的上下文嵌入,进一步增强 MLLMs 的定位能力,为各种 MLLMs 提供视觉提示以提升细粒度认知能力。
**2.2 标记
与边界框类似,视觉标记是视觉数据(如图像或视频)中的特定元素,用于突出、识别或引起对特定特征或区域的注意。它们通常用于指示与任务相关的图像特定部分。先前的研究 Shtedritski et al. (2023) 表明,训练于大规模网络数据的模型可以集中于特定的视觉标记,例如红圈,以突出所需区域,而不是围绕它们裁剪图像。AutoAD-ZeroXie et al. (2024) 提出了一种两阶段的无训练方法,通过在框架中“圈定”字符并对每个身份进行颜色编码来整合字符信息。最近,Set-of-Mark (SoM) 提示(Yang et al., 2023)直接在图像上覆盖视觉标记,帮助模型生成基于特定图像区域的答案。ViP-LLaVACai et al. (2024) 通过整合诸如涂鸦和箭头等任意视觉提示,扩展了这一点,使用微调模型来识别这些标记。Liao et al. (2024) 还利用 SoM 技术引入反馈,将其转化为文本或视觉标记,以改善语义基础。SoM-LLaVA Yan et al. (2024) 提出了一种通过逐项列出项目并全面描述图像中所有标记项目的方法,以增强 SoM 的标签关联。其他方法,如 ToL Fan et al. (2024b) 和 OWG Tziafas 和 Kasaei (2024),为框架中的每个段落链接唯一 ID,而 Pivot Nasiriany et al. (2024) 则将 3D 位置投影到图像空间,并在此投影位置绘制视觉标记,以指代输出空间中的空间概念。
**2.3 像素级
先前的方法依赖于粗糙的标记,如彩色框或圆,这导致在准确突出物体时出现歧义。为了解决这个问题,像素级提示(Ma et al., 2024b)使用图像或视频中的单个像素,增强 MLLMs 的语义定位能力。方法如 FGVP Yang et al. (2024a)、EVP Liu et al. (2023b)、DOrA Wu et al. (2024e) 和 CoLLaVO Lee et al. (2024) 利用像素级提示传达语义信息,实现精确的物体定位。OMG-LLaVA Zhang et al. (2024e) 和 VisionLLM Wang et al. (2024b) 将图像标记为像素中心的视觉标记,将视觉任务与语言指令对齐。技术如图像修复(Bar et al., 2022)将视觉标记解码为像素,而 ControlMLLM Wu et al. (2024d) 则建模像素与文本提示之间丰富的语义关系。此外,还有坐标提示方法,如 SCAFFOLD Lei et al. (2024a) 和 AO-Planner Chen et al. (2024a),将输入图像转换为使用度量的坐标,增强 MLLMs 的空间理解和推理能力。
**2.4 软视觉提示
软视觉提示在像素空间中学习并直接应用于图像,使模型能够更有效地适应特定的下游任务。特别地,TVP Zhang et al. (2024g)、BlackVIP Oh et al. (2023) 和 VPGTrans Zhang et al. (2024a) 向图像添加像素级提示,或通过在图像周围添加通用提示,或设计与图像形状相匹配的提示。在学习提示(Rezaei et al., 2024)、WVPrompt Ren et al. (2024) 和 ILM-VP Chen et al. (2023a) 中,任务相关的扰动模式被注入到像素空间中以修改输入样本。此外,ImageBrush Yang et al. (2024b) 通过从图像中提取标记特征来增强语义理解。
3 视觉提示生成
与文本提示不同,视觉提示通常是位置感知的、特定实例的,涉及特定的视觉对象、关系和上下文。目前的方法使用视觉提示生成方法和模型,通过生成图像和视频的视觉提示(如分割、检测和图像修复)来提高 MLLMs 的准确性和理解能力。此外,视觉提示方法的工具链被用于实现多步骤视觉推理和规划。为了创建普遍适用的视觉提示,还开发了可学习的像素值。
**3.1 提示工程
理解人造视觉提示在实际用例中可能非常重要,因为视觉提示在表达个人意图或关注当前视觉证据时尤其有效。早期的探索(Shtedritski et al., 2023)发现,在物体周围画一个简单的红圈可以引导模型的注意力到该区域。此外,MIVPG Zhong et al. (2024) 利用图像或补丁中的实例相关性来丰富详细的视觉证据。 ViP Cai et al. (2024) 引入了一种新颖的多模态模型,能够解码自由形式的视觉提示,使用户能够用自然线索直观地标记图像。这种方法不需要复杂的区域编码,并在区域特定的理解任务上取得了最先进的性能。此外,ViP-Bench Cai et al. (2024) 也被提出用于评估 MLLM 对这种自然工程视觉提示的感知。在领域特定的 CityLLaVA Duan et al. (2024) 框架中,收集并定制了工程视觉提示,以进一步增强微调的 MLLM。
**3.2 视觉分割
分割方法,如 OpenSeeD Zhang et al. (2023b)、SAM Kirillov et al. (2023) 和 SegFormer Xie et al. (2021),用于勾勒和识别图像中的特定区域、物体或结构,从而使模型能够更准确地关注相关的视觉信息。通过预训练的分割模型,外部视觉知识可以转移并整合到 MLLM 的提示中。Yang et al. (2024a) 探索了一种通过图像修复(Bar et al., 2022)方法进行像素级注释的细粒度视觉提示方法。Lin et al. (2024b) 提出了一种指令调优方法,将细粒度分割知识直接整合到空间嵌入图中作为视觉提示,从而增强模型对视觉场景的上下文意识。VAP Chen et al. (2024a) 开发了一种视觉可用性提示方法,通过 SAM Kirillov et al. (2023) 在导航任务中固化视觉元素。DOrA Wu et al. (2024e) 进一步引入 3D 空间和上下文信息,以改善 3D 视觉定位任务。
细粒度的分割信息还增强了 MLLM 的视觉感知和推理能力。OMG-LLaVA Zhang et al. (2024e) 整合了多级视觉提示,使 MLLM 能够从粗到细的视觉感知,获得更全面的视觉理解。Liu et al. (2023b) 提出增强模型理解和处理图像中低级结构元素的能力。He et al. (2024) 进一步将此类视觉提示融入 MLLM 微调,以增强模型在细粒度视觉感知中的能力。CoLLaVO Lee et al. (2024) 提出了一种蜡笔提示方法,通过与图像修复色彩图结合的全景分割方法,更好地区分图像中的多个物体。
**3.3 物体检测
物体检测模型如 SoM Yang et al. (2023)、RCNN Girshick (2015) 和 Omni3D Brazil et al. (2023) 提供精确的物体识别和定位,辅助 MLLM 的视觉定位能力并引导 MLLM 的注意力关注语义上有意义的内容。由 Yan et al. (2024) 开发的 SoM-LLaVA 使用数字标签将视觉对象与文本描述对齐。物体标签使模型能够准确列出和描述这些物体,增强视觉推理和视觉指令跟随能力。InstructDET Dang et al. (2023) 将通用指令融入训练过程中,通过使模型理解和遵循各种引用指令来多样化物体检测。这增强了模型在不同任务上下文中理解用户意图和指令的灵活性。Wan et al. (2024) 提出通过对比区域引导改进视觉语言模型的定位。通过引导模型的注意力到相关区域,MLLM 能够更准确地将视觉区域与相应的文本指令关联。Cho et al. (2024) 扩展视觉语言模型以理解 3D 环境,通过提高空间意识和对三维空间中物体交互的理解。
**3.4 视觉提示工具链
为了通过多步骤或交互推理实现更复杂的多模态理解,几种方法将各种视觉提示方法作为工具链聚合(Wu et al., 2024f),由 MLLM 调用以辅助各个推理子任务。Zhou et al. (2024b) 提出了一个图像思维方法,能够自动确定每个推理步骤的视觉信息提取方法,并将其实现为视觉提示,促使 MLLM 遵循特定的推理路径,实现逐步的多模态推理。Tziafas 和 Kasaei (2024) 专注于通过整合包括开放式分割和物体定位在内的视觉提示方法,调整视觉语言模型以适应开放世界抓取任务。为了实现更可转移和通用的视觉提示,Sheng et al. (2024) 创建了一种更统一的上下文学习方法,将各种上下文视觉提示整合到一个统一的表示空间。MineDreamer Zhou et al. (2024a) 进一步开发了一种多用途的视觉提示生成方法,用于与当前决策意图一致并在视觉上表达下一步目标的虚构视觉场景。
**3.5 可学习和软视觉提示
可学习或软视觉提示用于适应 MLLM 中的视觉编码器,使得视觉提示的使用更加可控和多样化,符合下游任务。这些技术用于具有视觉指令的多模态指令调优。Rezaei et al. (2024) 研究了如何学习视觉提示以指导 ViT 中的注意机制。Li et al. (2023a) 微调 MLLM 以遵循使用可学习视觉提示的零-shot 示范指令。Chen et al. (2023a) 关注通过学习提示更好地将视觉输入映射到相应的标签。对于一些特定和领域导向的问题,Ren et al. (2024) 开发了一种可学习的视觉提示方法,作为图像水印识别图像的版权和所有权。
与此同时,可学习的视觉提示还可以在 MLLM 和下游任务之间进行迁移。VPGTrans Zhang et al. (2024a) 提出了一个可转移的视觉提示生成器,以低成本训练数据点和计算,将预训练的源 MLLM 适应目标 MLLM。Memory-space visual prompt Jie et al. (2024) 在视觉变换器架构的关键和值层注入可学习提示,从而实现高效的视觉语言微调。Wu et al. (2023) 还注入软视觉标记作为视觉组合操作,经过学习以更好地与少量示例组合多模态信息。黑箱视觉提示方法 Oh et al. (2023) 专注于强大的迁移学习,其中视觉提示帮助模型适应新的任务和领域,而无需直接访问模型参数。
4 视觉感知
**4.1 视觉定位与指代
最近的视觉提示工作显著提升了 MLLM 的视觉定位和指代能力。一些研究强调迭代反馈和多模态交互在细化语义定位中的重要性,其他则探索面向对象的感知和视觉关系理解。SoM-LLaVA Yan et al. (2024) 使用 Set-of-Mark 模型标记图像中的所有物体,并要求模型列出所有项目。InstructDET Dang et al. (2023) 和 VTPrompt Jiang et al. (2024) 进一步实现了多模态定位,从文本中提取对象实体及其区域边界框。
使用细粒度视觉定位编码器,多个研究通过视觉线索引导 MLLM 的注意力至图像中的相关区域,从而提高区域指代能力。CRG Wan et al. (2024) 使用对比区域引导,直接将模型的注意力引导到图像中特定的兴趣区域。RelationVLM Huang et al. (2024c) 利用视觉提示增强 MLLM 对物体空间关系的理解与推理。Shikra Chen et al. (2023b) 应用于视觉对话系统,使 MLLM 能够根据对话中的指代线索做出更精确和上下文相关的互动。此外,还有多项工作旨在提供一个综合框架,将不同粒度的视觉提示方法整合在一起,以实现更细粒度和灵活的多模态交互,包括自由形式视觉提示输入 Lin et al. (2024a) 和视觉提示反馈机制 Liao et al. (2024)。
**4.2 多图像和视频理解
为了提高模型对复杂视觉关系的理解,并确保其能够准确引用和描述多图像输入中的对象,多个研究提出了在多图像输入中使用视觉提示的新方法及评估基准。Fan et al. (2024c) 提出了一个包含多面板图像的新基准数据集,以测试 MLLM 在区分面板间对象及导航不同视觉元素方面的能力。Pan et al. (2024) 利用形态标记自编码提升模型在多图像间的视觉定位能力。Li et al. (2023a) 微调 MLLM 以遵循多图像中的上下文示范指令。此外,AIM Gao et al. (2024) 提出动态调整其定位和指代能力,以适应多个图像中的新视觉上下文。
多种方法也被开发,以允许 MLLM 识别特定的兴趣区域,提高其处理复杂和动态视频内容的能力。OmAgent Zhang et al. (2024c) 开发了一种视觉提示方法,通过注释一系列视觉特征,实现视频理解中的任务划分。RACCooN Yoon et al. (2024) 使用视觉提示引导 MLLM 识别视频中的目标区域进行操作。Wu et al. (2024c) 在视频中进行对象定位,使模型能够理解和指代动态场景中的对象。
**4.3 3D视觉理解
最近的研究使用视觉提示来增强 3D 视觉理解。Li et al. (2024) 构建了一个包含指令-响应对的广泛数据集用于 3D 场景,并引入了 3DMIT,以高效地进行提示调优,同时消除 3D 场景与语言之间的对齐阶段。DOrA Wu et al. (2024e) 提出了一个具有顺序感知指代的新型 3D 视觉定位框架。该方法利用 LLM 推断有序的物体序列,以引导逐步特征细化过程。 Cho et al. (2024) 构建了一个名为 LV3D 的大规模数据集,并引入了在该数据集上预训练的新型 MLLM Cube-LLM。Zhang et al. (2024d) 提出了 Agent3D-Zero,采用鸟瞰图像和选择视角的新视觉提示,释放 MLLM 观察 3D 场景的能力。3DAP Liu et al. (2023a) 开发了一种新型视觉提示方法,创建一个 3D 坐标系统和附加注释,以增强 GPT-4V 完成 3D 空间任务的能力。
5 组合推理
本节讨论视觉提示如何增强 MLLM 中的组合和多模态学习,促进视觉规划、推理和行动生成等任务的改善。我们考察视觉提示如何促进复杂的逐步推理、决策制定以及对视觉生成模型的控制,扩展其在多种任务中的能力。我们还回顾了一些边缘应用(附录 9),这些应用可能尚未充分探索,且缺乏足够的解决方案。
**5.1 视觉规划
近期研究表明,视觉提示改善了视觉规划任务。Zhou et al. (2024b) 提出了一个图像思维(IoT)提示方法,促使 MLLM 自动设计视觉和文本步骤,并利用外部图像处理工具生成多模态推理序列,用于辅助 MLLM 完成复杂视觉推理任务。OWG Tziafas 和 Kasaei (2024) 结合分割与抓取合成模型,通过分割、抓取规划和排序解锁基础世界理解。Zhou et al. (2024a) 引入了想象链(CoI)方法,并在 Minecraft 中创建了一个具身代理 MineDreamer。该方法设想执行指令的逐步过程,借助 LLM 增强的扩散模型,将想象转化为精确的视觉提示,支持代理行为的准确生成。BEVInstructor Fan et al. (2024a) 将鸟瞰图表示作为视觉提示融入 MLLM,用于导航指令生成。AO-Planner Chen et al. (2024a) 实现了以可用性为导向的运动规划和行动决策,采用 VAP 方法与高层 PathAgent。
**5.2 逐步推理
为了实现更复杂的图像推理,最近的研究将视觉提示与逐步推理方法结合。Luan et al. (2024) 提出了一种新颖的逐步推理框架,用于文本丰富的图像理解,命名为 TextCoT。该方法包括三个阶段:图像概述以获取全局信息、粗略定位以估计包含答案的部分,以及细粒度观察以提供精确答案。Wu et al. (2024f) 提出了 DetToolChain,解锁 MLLM 在物体检测任务中的潜力。该方法涉及使用“检测提示工具包”,其中包含视觉处理和检测推理提示,并结合多模态检测逐步推理方法,以推理检测提示的顺序实现。
6 模型训练
本节介绍使用视觉提示技术对多模态大语言模型(MLLMs)进行对齐的关键方法,包括预训练、微调和指令调优,旨在统一多模态提示并提高跨任务的可迁移性。除了模型训练技术外,我们还总结了评估数据集(附录8),这些数据集为未来开发更强大的视觉提示方法提供了灵感。
6.1 预训练
为了提升 MLLM 在更细粒度视觉感知或推理任务上的能力,研究集中在设计更好的预训练目标,包括视觉提示。PSALM Zhang et al. (2024h) 扩展了 MLLM 在多种图像分割任务上的能力,通过引入掩膜解码器和灵活的输入架构,统一了单一模型内的多种分割任务,支持通用、指代、交互和开放词汇分割,同时在域内和域外的像素级分割任务上表现出色。OMG-LLaVA Zhang et al. (2024e) 提出了一个统一框架,将图像级、对象级和像素级的推理与理解融合在一个模型中,结合通用分割方法作为视觉编码器,并与 LLM 结合,使用户能够通过多种视觉和文本提示进行灵活互动。VisionLLM v2 Wu et al. (2024a) 引入了一个端到端的通用 MLLM,将视觉感知、理解和生成统一在一个框架内。该模型采用新颖的“超链接”技术将中央 LLM 与任务特定解码器连接,支持跨数百个视觉和视觉-语言任务的信息传输和端到端优化。UrbanVLP Hao et al. (2024) 提出了一个针对城市区域概况的视觉-语言预训练框架,整合了来自卫星(宏观级)和街景(微观级)影像的多粒度信息,克服了以往的局限性。该方法还结合了自动文本生成和校准机制,以生成高质量的城市区域文本描述,增强可解释性。
6.2 微调
Zhang et al. (2024g) 提出了可转移视觉提示(TVP)方法,旨在提高软视觉提示的可转移性,这些提示是在不同 MLLM 之间用于下游任务的小量可学习参数。Lin et al. (2024b) 将细粒度外部知识(如 OCR 和分割)通过视觉提示整合到多模态 MLLM 中,直接将细粒度知识信息嵌入到空间嵌入图中。CoLLaVO Lee et al. (2024) 通过一种名为 Crayon Prompt 的视觉提示增强了 MLLM 的对象级图像理解,该提示源自全景分割模型生成的全景色彩图。CityLLaVA Duan et al. (2024) 引入了一个高效的 MLLM 微调框架,专为城市场景设计,结合了视觉提示工程技术,包括边界框引导、视角选择和全局-局部联合视图。ViP-LLaVA Cai et al. (2024) 被赋予理解任意视觉提示的能力,通过直接将视觉标记叠加到图像上进行训练。ImageBrush Yang et al. (2024b) 提出了一个基于示例的图像操作框架,无需语言提示即可学习视觉上下文指令。
显式视觉提示(EVP)Liu et al. (2023b) 提出了一个统一的方法,用于低级结构分割任务,使用冻结的预训练视觉变换器主干,并引入源自冻结的块嵌入和高频图像成分的任务特定软提示。BlackVIP Oh et al. (2023) 通过一个协调器适应大型预训练模型,以生成软视觉提示,并使用 SPSA-GC 进行高效梯度估计,从而在不同领域实现稳健的少量适应。基于迭代标签映射的视觉提示(ILM-VP)Chen et al. (2023a) 通过双层优化共同优化输入模式和标签映射,从而提高软视觉提示的准确性和可解释性。MemVP Jie et al. (2024) 通过将视觉信息直接注入 MLLM 的前馈网络权重,有效地结合了预训练视觉编码器和语言模型,以应对视觉-语言任务,将其视为附加的事实知识。VPG-C Li et al. (2023a) 通过补全缺失的视觉细节来增强 MLLM 中的视觉提示,更好地理解具有交错多模态上下文的演示指令。它扩展了传统视觉提示生成器,通过 LLM 引导的上下文感知视觉特征提取来创建更全面的视觉提示。
6.3 指令调优
指令调优已被证明能够有效提高文本仅 LLM 和 MLLM 的整体能力,如指令跟随和结构化输出 Ouyang et al. (2022); Wang et al. (2022); Liu et al. (2024a)。对于专注于视觉提示的 MLLM,AnyRef He et al. (2024) 引入了一种统一的指代表示,使 MLLM 能够通过指令调优处理多种输入模态和视觉提示(文本、边界框、图像、音频)。该模型使用特殊的标记和提示来格式化多模态输入,使其能够一致地处理各种指代格式。重新聚焦机制通过结合基础文本嵌入增强掩膜嵌入,提高分割准确性。AnyRef 将视觉和音频编码器与 LLM 结合,使用投影层对不同模态在语言空间中进行对齐。该模型通过文本损失和掩膜损失的组合进行端到端的指令调优,使其能够响应多模态提示生成文本描述和像素级分割。
7 上下文学习与少量学习
除了使用单一数据点作为输入优化性能的方法外,一些工作集中在利用视觉提示增强上下文学习(ICL)。图像思维(IoT)提示 Zhou et al. (2024b) 是一种无训练的方法,通过整合离散的图像处理动作来增强 MLLM 在视觉问答任务上的能力。IoT 使 MLLM 能够自动设计并提取逐步的视觉推理,将其与文本推理结合,提高了准确性和可解释性。CRG Wan et al. (2024) 是一种无训练的方法,通过将模型输出与掩盖特定图像区域的情况进行对比,改善 MLLM 的视觉定位,指导模型关注相关图像区域。AIM Gao et al. (2024) 使任何 MLLM 能够通过将演示中的图像信息聚合到相应文本标签的潜在空间中,执行高效的 ICL,这减少了内存成本,通过在聚合后丢弃视觉标记,近似多模态 ICL 提示仅包含单个查询图像。I2L Wang et al. (2024a) 将演示、视觉线索和推理结合为单一图像,通过 ICL 增强多模态模型在复杂任务上的表现。I2L-Hybrid 通过在每个任务实例中自动选择 I2L 和其他上下文学习方法扩展了这一方法。
通过视觉提示的少量学习也能在最低计算成本和更好的数据效率下提高 MLLM 的能力。CoMM Chen et al. (2024b) 提出了一个高质量一致的交错图像-文本数据集,旨在增强 MLLM 的生成能力,并调查其上下文学习能力。M2oEGPT Sheng et al. (2024) 提出了一个 ICL 框架,通过多模态量化和统一嵌入,使得在通用标记嵌入空间中联合学习多模态数据,结合自回归变换器与专家混合(MoEs)进行稳定的多任务共训练。Partial2Global Xu et al. (2024a) 通过基于变换器的列表排序器选择视觉 ICL 中的最佳上下文示例,比较多个备选样本,并使用一致性感知排名聚合器实现全局一致的排名。Hossain et al. (2024) 为语义分割中的基础类和新类引入可学习的视觉提示,并提出了一种新类-基础类因果注意机制,使新提示能够在不降低基础类性能的情况下被基础提示上下文化。Emu2 Sun et al. (2024) 是一个训练 MLLM 以预测多模态序列中下一个元素的模型。其统一架构使得强大的多模态上下文学习能力得以实现,使其能够快速适应新任务,仅需几个示例。
结论
在本次调研中,我们首次全面回顾了多模态大语言模型(MLLMs)中的视觉提示方法。我们对各种视觉提示技术进行了分类,并讨论了它们的生成过程,考察了这些技术如何融入 MLLMs,以增强视觉推理和感知能力。我们的工作还分析了现有的训练和上下文学习方法在视觉提示中的应用。最后,我们提出了未来的研究方向,鼓励利用视觉提示来改进 MLLM 的组合推理能力。