本教程提供了关于推理时引导和对齐方法的深入指南,用于优化扩散模型中的下游奖励函数。
虽然扩散模型因其生成建模能力而广受欢迎,但在生物学等领域的实际应用中,通常需要生成最大化特定度量的样本(例如稳定性、蛋白质的亲和力、接近目标结构)。在这些场景中,扩散模型不仅可以生成逼真的样本,还可以在推理时明确地最大化所需的度量,而无需微调。本教程探讨了此类推理时算法的基础方面。我们从统一的视角回顾了这些方法,展示了当前的技术——例如基于序贯蒙特卡洛(SMC)的引导、基于价值的采样和分类器引导——旨在近似软最优去噪过程(即强化学习中的策略),将预训练的去噪过程与价值函数结合,作为前瞻函数,从中间状态预测终极奖励。 在此框架下,我们提出了几种在文献中尚未涉及的新算法。此外,我们还讨论了:(1)结合推理时技术的微调方法,(2)基于搜索算法(如蒙特卡洛树搜索)的推理时算法,这些方法在当前研究中关注较少,以及(3)语言模型和扩散模型中推理时算法的联系。本教程中关于蛋白质设计的代码可在 https://github.com/masa-ue/AlignInversePro 获取。 关键词:扩散模型,推理时对齐,基于模型的优化,强化学习,分类器引导,序贯蒙特卡洛,树搜索,蛋白质设计
介绍
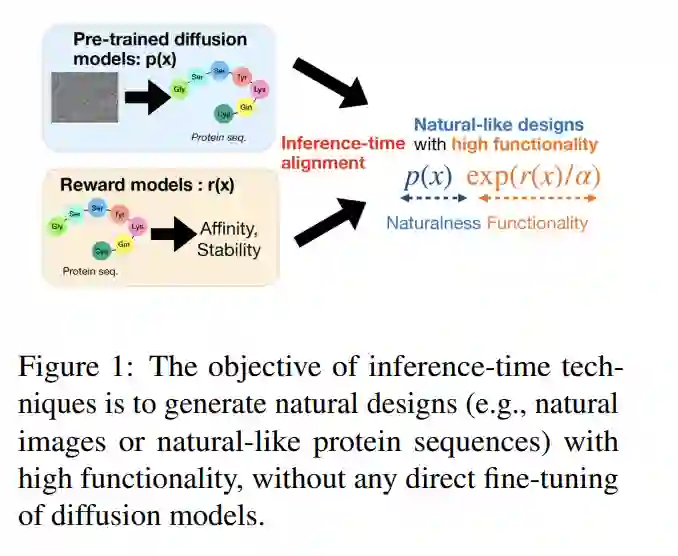
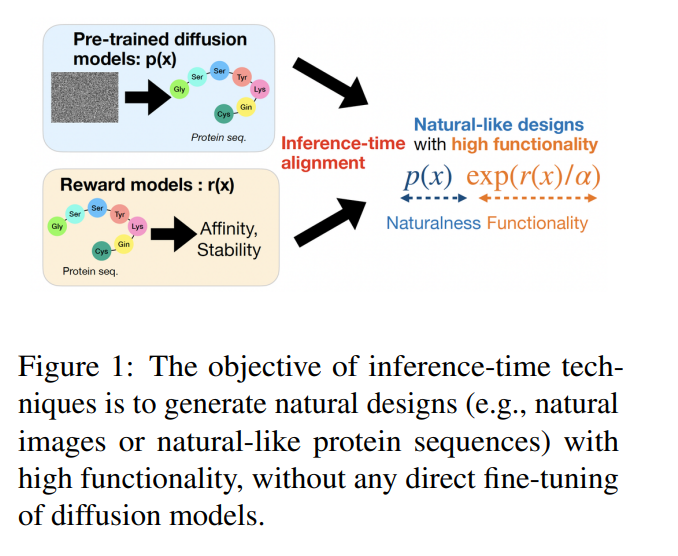
扩散模型(Sohl-Dickstein et al., 2015;Ho et al., 2020;Song et al., 2020)在计算机视觉领域取得了显著成功,特别是在生成连续领域(如图像)(Rombach et al., 2022)的生成模型方面。这一成功进一步扩展到科学领域,如蛋白质三维结构生成(Yim et al., 2023;Watson et al., 2023;Chu et al., 2024;Abramson et al., 2024)和小分子三维结构生成(Xu et al., 2022;Jing et al., 2022;Corso et al., 2022)。此外,近期的研究(Shi et al., 2024;Sahoo et al., 2024;Lou et al., 2023)表明,在离散领域中,扩散模型相较于传统自回归模型也取得了有希望的结果。基于自然语言处理(NLP)领域的进展,扩散模型的使用也被探索用于生成生物序列(如蛋白质、RNA 和 DNA),这些序列本质上是非因果的,因为它们折叠成复杂的三级(3D)结构(Campbell et al., 2024;Sarkar et al., 2024;Winnifrith et al., 2024;Wang et al., 2024)。 控制生成是扩散模型研究中的一个关键主题。在“基础模型”的背景下,过程通常从在大规模数据集上训练条件扩散模型开始,以生成基于基本功能的自然设计(例如,生物学上合理的蛋白质序列)。在预训练阶段之后,重点通常转向优化特定的下游奖励函数,这通常被称为 AI 中的“对齐”问题。通过在推理时引导生成以最大化给定的奖励(例如,蛋白质序列中的结合亲和力或稳定性),扩散模型可以有效地作为强大的计算设计框架。同样,在推理时根据目标属性进行条件化被视为一个奖励最大化任务,其中奖励通常通过分类器定义。 在本教程中,我们旨在探索扩散模型中的推理时控制生成技术及其基础特性。这些技术旨在无缝地将基于大规模数据集训练的预训练生成模型与奖励模型结合,如图1所示。具体而言,在预训练的扩散模型中的每个生成步骤中,引入某些修改以优化下游奖励函数,如图2所总结。此类方法的一个显著优势是,它们不需要对扩散模型进行后训练,这通常会消耗大量计算资源。最简单的这种方法是图2a中的“最佳-N采样”,该方法涉及从预训练的扩散模型生成多个设计(N个样本),并根据奖励函数(例如,Nakano et al. (2021))选择最佳样本。然而,当奖励函数难以优化时,这种方法可能效率较低。更高效的复杂策略包括图2b中的分类器引导及其变种(Dhariwal and Nichol, 2021;Song et al., 2021),图2c中的基于序贯蒙特卡洛的方法(Wu et al., 2024;Dou and Song, 2024;Cardoso et al., 2023;Phillips et al., 2024),以及图2d中的基于价值的采样方法(Li et al., 2024)。 在深入探讨推理时技术的细节之前,我们首先在介绍部分提供本教程的简要概述。我们首先强调推理时方法相较于后训练方法的优势,后者也能实现控制生成。接下来,我们概述了推理时控制生成所需的关键组件。最后,我们对本工作中涵盖的推理时技术提供了全面的概述。

推理时技术与后训练方法
在预训练之后,控制生成有两种主要方法:推理时技术(即,不需要微调扩散模型)和后训练方法,如基于强化学习(RL)的微调(Black et al., 2023;Fan et al., 2023;Clark et al., 2023;Uehara et al., 2024)或基于无分类器引导的微调(Ho 和 Salimans, 2022;Zhang et al., 2023)。在本文中,我们主要聚焦于回顾推理时技术。对于后一种方法的全面概述,我们建议读者参考 Uehara et al. (2024)。尽管这两种方法都很重要,推理时技术通常具有以下几个优势:
- 推理时技术实现起来特别简便,因为许多这些方法不仅不需要微调,而且在获得奖励函数的情况下也不需要训练。尽管它们简单,但与基于强化学习的微调方法相比,它们仍能提供具有竞争力的表现。
- 推理时技术能够支持后训练。例如,它们可以作为数据增强方法应用于无分类器引导中,或作为策略蒸馏后训练中的教师策略。更多细节请参见第9.4节。
- 即使通过后训练技术获得了微调模型,应用推理时方法进行微调也可以有利于进一步改善生成输出的功能。当下游奖励反馈非常准确时,这尤其相关。后训练可能无法充分利用奖励反馈所提供的信息,因为它涉及将这些反馈转换为数据,这个过程可能会导致信息丢失。相比之下,推理时技术可以直接利用奖励反馈,而无需进行此类转换,从而实现更有效的优化。
选择推理时技术的关键考虑因素
在本文中,我们根据以下特征对当前的推理时技术进行了分类:
- 计算和内存效率:通常,即使使用相同的算法,推理过程中增加的计算或内存资源也能产生更高质量的设计。因此,为了公平比较,在推理时应在相同的计算或内存预算内评估生成样本的性能。此外,平行计算的便捷性是一个重要的实践考虑因素。
- 我们希望优化的奖励是什么:考虑我们要优化的属性(在本草稿中称为奖励模型)是否充当分类器是非常相关的,就像在标准引导文献中看到的那样,还是充当回归模型,后者在对齐文献中较为常见。在本草稿中,前者任务通常称为条件化,后者则称为对齐。
- 奖励反馈的可微性:在计算机视觉和自然语言处理(NLP)中,许多有用的奖励反馈是可微的。然而,在分子设计等科学领域,许多有用的奖励反馈,如基于物理的模拟(Salomon-Ferrer et al., 2013;Chaudhury et al., 2010;Trott 和 Olson, 2010),是不可微的。此外,当使用学习到的奖励模型作为反馈时,由于它们依赖于非可微特征(如分子指纹或生物物理描述符)(Stanton 和 Jurs, 1990;Yap, 2011;Li et al., 2015),这些反馈通常是不可微的。
总结
考虑到这些方面,我们提供了对当前扩散模型推理时技术的统一分类,同时也突出了新的视角。本教程的核心信息总结如下。

此外,我们还探讨了推理时方法在扩散模型中的更高级应用,包括与微调、搜索算法、编辑以及在超出扩散框架的掩蔽语言模型中的应用的集成。教程的其余部分组织如下:
- 第2节:我们首先概述推理时技术的基础原理。具体而言,我们介绍了在(1)中定义的软最优策略,该策略代表了推理过程中目标的去噪过程。本教程中讨论的所有方法都旨在逼近这一最优策略。
- 第3节:我们回顾了不需要可微奖励反馈的推理时技术,特别是在分子设计中非常有用。这些方法大致分为两大类:基于SMC的方法(Wu et al., 2024;Dou and Song, 2024;Cardoso et al., 2023;Phillips et al., 2024)和基于价值的重加权采样方法(Li et al., 2024)。此外,我们还解释了如何将这两种方法进行集成。
- 第4、5节:我们回顾了需要可微奖励或价值函数模型的方法。当能够构建有效的可微奖励模型时,这些方法很有用,例如计算机视觉中的修复任务或蛋白质设计中的基序支架。我们首先在第4节讨论这些方法如何应用于连续领域中的扩散模型,这也被称为分类器引导(Dhariwal 和 Nichol, 2021;Song et al., 2021),并通过 Doob 变换进行形式化。然后,在第5节中,我们为离散扩散模型提供了类似的解释。
- 第6节:如第3节所提到的,基于价值函数的束搜索是对齐任务的自然解决方案。接下来的自然步骤是集成更先进的搜索算法。我们简要讨论了如何将基于搜索的算法(例如MCTS)应用于扩散模型。
- 第7节:第3节至第5节中描述的推理时技术主要集中在从完全噪声状态中生成设计。然而,在蛋白质设计中,目标通常涉及编辑满足严格约束条件的内源性设计。我们考察了如何通过顺序优化调整第3节至第5节中介绍的推理时技术来实现这些目标。
- 第8节:我们简要回顾了语言模型中的推理时技术,重点关注自回归模型(如GPT(Brown, 2020))和掩蔽语言模型(如BERT(Kenton 和 Toutanova, 2019)),并比较了自回归模型、掩蔽语言模型和扩散模型之间的相似性和差异。
- 第9节:我们描述了如何通过蒸馏应用推理时技术来微调扩散模型。这一点尤其重要,因为纯粹的推理时技术可能导致更高的推理成本。我们还建立了这些方法与基于强化学习的微调方法之间的联系。
- 第10节:我们简要概述了蛋白质设计中相关的算法方法,包括步进跳跃采样(Frey et al., 2023)和幻觉方法(即遗传算法、基于MCMC的方法)(Anishchenko et al., 2021;Jendrusch et al., 2021)。