
基于机器学习科学发现综述,不可错过!

大规模科学装置与重大科学实验使得科学发现进入了数据密集型的第四范式,借助蓬勃发展的人工智能技术促进 智能科学发现势在必行.机器学习作为人工智能中一项重要技术,已广泛应用于各个科学领域. 然而,现有工作仅研究特定任 务下的机器学习方法,没能抽象出一个通用的智能科学发现研究框架. 本文首先总结了科学发现任务中常用的机器学习方 法,并将科学任务归类为五大机器学习问题. 其次,提出了基于机器学习的智能科学发现研究框架,作为“AI for Science” 的典型范例,阐述一种高效的智能科学发现模式. 再次,本文以时域天文学中发现瞬变事件这一科学任务为例,通过实验证 明了唯有恰当地结合领域知识后,机器学习算法才能更好地服务于智能科学发现,验证了该框架的有效性.最后进行总结与 展望,以期对各领域进行智能科学发现形成参考意义. 1.引言
大规模科学装置的建设与重大科学实验的开 展,使得科学发现研究无法完全依赖专家经验从海 量数据中捕捉并研究稀有的科学现象.近年来,人工 智能技术(Artificial Intelligence, AI)蓬勃发展,机器 学习(Machine Learning, ML)作为其重要的研究领 域之一,被科学家广泛应用于科学发现任务,促成 “AI for Science”的重大发展机遇. 从生物学、化学到天文学,机器学习在科学发 现任务中日益盛行,利用机器学习技术从海量科学 数据中发现稀有科学现象、研究复杂难题成为了科 学领域的首选方案. AlphaFold2[1]人工智能算法可 以预测人类 98.5%的蛋白质结构,准确度达到原子 级别.同样发表于《Nature》的研究成果[2]利用机器 学习技术以前所未有的速率进行逆向合成反应,具 有化学界的“AlphaGo”之称. 2019 年首张黑洞照片 的合成同样离不开机器学习算法的巨大贡献[3,4] .此 外,利用机器学习探测引力波,相较传统的模板匹 配,速度提升多个数量级[5]„„诸如此类的成功案 例不胜枚举,机器学习凭借在预测精度、时间效率 等方面的优异表现,在科学发现任务中发挥重要作 用. 2020 年美国能源部高级科学计算咨询委员会 (ASCAC)讨论了科学数据急剧增加带来的挑战和 机遇,批准了关于机器学习应用于科学的报告①, 并呼吁制定一个为期十年的 AI 计划② .可见,科学发 现已经进入“科学大数据+人工智能”的新范式.
在作者已发表的论文中[6],我们从数据管理的 角度提出了大规模科学数据的智能发现与管理框 架,分为智能分析、知识融合、数据存储三个方面解决智能科学发现问题.本文主要选取第一个方面, 探讨机器学习方法应用于科学数据智能分析、实现 智能科学发现的挑战与机遇. 科学大数据的特点.科学大数据是指以海量科 学证据形式存在的事实,包括观测与监测数据、实 验与模拟数据等原始及衍生数据[7],数据类型包括 栅格点云等空间数据、时序数据、时空数据以及图 像数据等[8] .相比于互联网大数据,科学大数据不仅 拥有 4V 特点,而且还具备独特的科学特征.主要体 现在如下三个方面:
1)生命周期长.相比于互联网大数据“重分析、 轻存储”的短暂生命周期,科学大数据的生命周期 包含“采集与实时分析—存储与处理—发布与共享 —再分析与重用—归档与长期保存”的全过程[7] .科 学大数据的生命周期更为完整且长久,价值具有长 效性,因此注重对科学大数据进行实时处理的同 时,离线分析同样具有重要的科学意义.
2)不确定性强.科学大数据是对客观世界的描 述,但由于观测条件以及设备的限制,其中普遍存 在环境噪声与系统观测误差,甚至数据缺失,导致 数据在质量和产生速率等方面存在较高的不确定 性[7] .另外科学数据通常来源于非人工系统[9],如海 洋、大气、天体,人类不能完全确定并控制其运作 机理,自然系统本身的高度不确定性加剧了科学大 数据的不确定性.
**3)不可重复与随意更改.**对科学事件的观测通 常是不可重复的[10],尤其是具有时间属性的科学对 象.例如 2019 年 1 月 29 日美国国家航空航天局通过 凌日系外行星勘测卫星捕捉到了罕见的“潮汐干 扰”,黑洞撕碎恒星,该观测数据是无法重复获得 的.另外,科学数据是对真理的客观描述,用于探索 科学问题,对科学数据的每一处理步骤都会对科学 发现的结果产生影响,因此对科学数据的预处理需 严格遵循科学原理,不可随意更改与变换.
科学发现任务的特点.随着科学数据演化成为 科学大数据,基础科学与应用科学领域中的科学发 现任务也形成了新的特点.基础科学是探索自然界 最普遍规律的科学,包括物理学、天文学等分支, 其以自然界中某种物质的形态及运动形式为研究 对象,以揭示自然界的基本规律为科学发现任务, 从而使人类更好地“认识世界”.应用科学是运用基础科学的理论成果从而创造性地解决人类在生产 实践中具体问题的科学领域,包括新药研发、材料 设计等分支,其科学发现任务为在特定领域内发现 新技术、新产品,从而使人类更好地“改造世界”. 本文将科学发现任务的特点总结为如下三个方面:
**1) 数据密集型科学发现.**早在 2007 年,图灵奖 得主吉姆格雷(Jim Gray)指出,科学研究的范式经历 了经验科学(实验归纳)、理论科学(模型推演)、计算 科学(模拟仿真)三阶段的演化过程,当代已经进入 了数据密集型科学发现(Data-intensive Scientific Discovery)的第四范式[11],从以计算为中心转化为 以数据处理为中心.随着科学数据的大规模采集和 积累,科学数据不再仅仅作为科学研究的成果,而 成为科学研究的对象和工具,基于数据来设计和实 施科学研究成为科学发现的一般方法.
2) 依赖先进的技术手段. 新技术手段拓展科学 发现的途径,而科学发现又可以促进新技术手段的 诞生,二者呈现出相互依赖、交替发展的关系.例如 计算机模拟和仿真技术开辟了新的科学实验和研 究方式,半导体材料科学的进步又提升了计算机芯 片的性能.当今蓬勃发展的机器学习技术将会对科 学研究产生重大影响,成为科学发现的有力工具.
3)兼具创新性与严谨性. 科学发现的目标为发 现新现象、新物质、新原理或创造新技术,因此创 新是科学发现的生命. 同时,科学创新还须具备严 谨性,包括可解释性和可复现性两方面.科学家不仅 要有新的发现,还要用严谨的逻辑解释其背后的原 因,从而实现干预世界的目标.可复现性是科学研究 的基本属性,这意味着其他研究人员可以重复同样 的过程,一个不可重复的偶然科学发现无法作为其 他科学研究的基础,因而失去价值.
机器学习应用于科学发现的挑战. 由于上述特 殊性,将机器学习应用于科学发现时面临很多挑 战,本文将其总结为任务、数据、模型三个方面:
1) 科学任务转化困难.将科学发现任务转化为 机器学习问题具有挑战性①,例如:如何将物理定 律参数化从而使用机器学习发现新的定律?目前 很多科学任务仍停留在本领域而未被转化为适合 机器学习解决的问题,这限制了机器学习相关学者 研究这些科学问题.将蛋白质结构预测这一科学任 务 转 化 为 从 序 列 到 三 维 结 构 的 映 射 问 题 是 AlphaFold2 成功的重要因素之一.因此巧妙地将科 学任务转化为能够被机器学习所解决的问题和场景是首要挑战.
2) 数据集成与预处理困难.科学数据分散在不 同国家的科研机构,经过集成并共享给其他研究人 员才能发挥更大的价值.然而目前科学数据面临着 缺乏有效融合、大型标准数据集建设不足以及质量 参差不齐等问题[12,13] . 另外科学数据通常是多源、 异构、高维、低信噪比且不均衡的[9],需要进行复 杂的预处理来保证数据质量.并且数据的科学属性 对处理过程产生更多的限制,使流程更为复杂[14] . 因此通过集成与共享获取高质量的科学数据、进而 结合领域知识对数据进行合适的预处理是应用机 器学习的基础.
3) 模型科学性验证困难.科学发现具有严谨性,因此需要验证机器学习模型的可解释性和可复现性,从而保证模型的科学性.但深度神经网络具有高度的非线性和复杂度,人们很难解释模型原理及在相应领域的科学意义,一些保守的科学家对其持观望态度,称其为“黑盒”模型[12].另外,目前深度学习方法的可复现性受到争议,利用机器学习所形成的科研成果在很多情况下是不可复现的[15].面对一个严谨的科学领域,提高机器学习模型的可解释性和可复现性、让科学家确认科学产出的真正价值,具有重要意义. 为了深入探究机器学习在科学发现任务中的优缺点,为各科学领域学者使用机器学习解决问题提供参考方案,本文第2节梳理科学发现中常用的机器学习方法,分析其适用场景,并阐述机器学习擅长处理的科学发现任务,将其归类为五大机器学习问题.第3节提出基于机器学习的智能科学发现研究框架,阐述一种高效的智能科学发现模式.第4节通过实验验证框架的有效性,即以时域天文学这一典型的“大数据+AI”的科学领域为例,使用7种机器学习方法和科学领域的传统方法完成发现天体瞬变事件的科学任务.第5节对机器学习应用于科学发现任务的经验教训和发展方向进行总结与展望.本文与其他相关综述性文章[12,16-20]的主要区别为:本文综合分析了机器学习在各个科学领域的研究现状,探讨其中的共性问题;并提出一个通用的研究框架,用以指导各科学领域学者使用机器学习进行高效的科学发现研究,同时促进机器学习相关学者快速了解科学发现任务;最后通过案例验证该框架的有效性。
2 研究现状
科学发现正在被机器学习所改变,从天文学、 物理学、化学等基础科学,到生物制药、材料科学、 气象科学等应用科学,越来越多的科学家利用机器 学习进行科学发现、解决复杂难题.在科学发现任务 中常用的机器学习方法有很多,根据模型复杂度可 分为基于统计的传统机器学习和基于神经网络的 深度学习两大类,根据任务目标又可分为分类、回 归、聚类、异常检测、数据生成等.相对于传统机器 学习,深度学习方法被越来越多地应用于科学发现 研究,辅助科学家实现了更加重大的科学突破. 本节首先根据第一种分类方式讨论在科学发 现任务中常用的机器学习方法,分析传统机器学习 与深度学习方法在科学发现任务中的优缺点与适 用场景.其次以基础科学和应用科学领域中的部分 学科为例,阐明机器学习所擅长处理的科学发现任 务,并根据第二种分类方式,将不同的科学发现任 务归类为五大机器学习问题.
2.1 传统机器学习方法
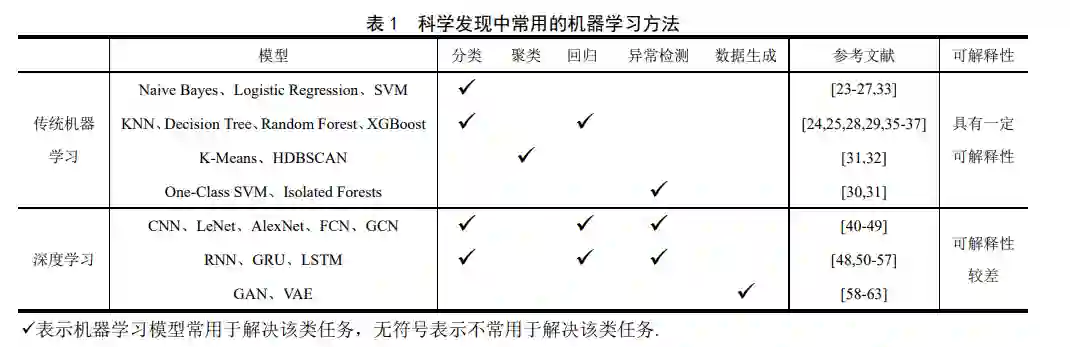
在机器学习应用于科学发现的初期,由于数据 量以及计算能力的限制,科学家普遍使用传统机器 学习方法[21],并在经典模型的基础上,根据具体问 题对模型的输入、超参数、结构等做出适当调整, 从而在实际科学任务中达到最好的效果.
其中,分类与回归是两种应用最为普遍的方法. 二者均属于预测方法,区别在于预测数据的类型不 同,因此很多分类算法同时可以担任回归任务[22] . 朴素贝叶斯 (Naive Bayes) 、逻辑回归 (Logistic Regression, LR)、K 近邻(K-Nearest Neighbor, KNN)、 决策树(Decision Tree)是较为简单的方法,具有模型 直观、容易实现的特点[23-25] .支持向量机(Support Vector Machines, SVM)、随机森林(Random Forest) 与 极 度 梯 度 提 升 (eXtreme Gradient Boosting, XGBoost)是更为复杂同时更为有效的方法[24-29],其 中 Random Forest 与 XGBoost 是两种典型的基于 Bagging 与 Boosting 的集成方法,通常准确率更高, 因此在科学发现任务中的应用也更为普遍.
当数据无标签时,科学发现任务中还常用聚类 和异常检测两种无监督方法来解决科学问题. 例如 在天文领域,瞬变科学事件具有偶发性和不可预知 性,因此可通过孤立森林(Isolated Forests)、一类支 持向量机(One-Class SVM)等异常检测算法发现瞬变源[30,31] .当需要挖掘未知类别与属性时,还可以利 用聚类算法进行分析[31,32],例如时域天文学家对光 变曲线提取特征后,通过 HDBSCAN(Hierarchical Density-Based Spatial Clustering of Applications with Noise)等聚类算法分析类之间的异质性,并进一步 分析其中的异常[31] .
**由于传统机器学习依赖人工提取特征,因此在 科学发现中的相关研究侧重于根据领域知识提取 更为有效的特征表示,进而利用相应模型完成科学 发现任务,特征质量对最终的结果具有决定性作用.**例如在时域天文学领域,天文学家根据领域知识从 光变曲线中提取偏度峰度等标准统计量、以及峰的 宽度等领域特征,进而对天体进行分类[33,34] .在化学 领域,科学家将非数值类型的化学式转化为机器学 习可以识别的形式,如通过物理化学描述符、分子 指纹、分子简写式等方式对分子进行表示,进而通 过分类或回归模型对化合物性质进行建模与预测 [35] .在高能物理领域,将探测器响应的时间、位置和 幅度信息作为输入,利用回归模型可以重建物理事 件的主要产物在探测器中的运动轨迹[36] .在新药研 发领域,通过对已知药物与靶点的对应数据进行建 模,可以预测其他药物与靶点之间的复杂关系[37] . 随着研究的深入,提取的特征数目越来越多, 例如从光变曲线中可以提取出数百种特征,但并非 所有特征都同等重要.因此科学家利用主成分分析、 t 分布随机近邻嵌入(t-SNE)等方法对高维数据进行 降维,从中筛选出更有效的特征子集,并可视化数 据间的聚簇关系,提升后续模型的效果[38,39]。
小结:传统机器学习方法的输入特征表示由科 学家结合领域知识人工提取,具有较强的物理意 义;模型具有较强的理论支撑、相对简单,因此通 常认为具有较好的可解释性.但上述特点具有两面 性.人工提取特征容易引入偏见,特征具有局限性. 更多的特征并未带来效果的显著提升;并且模型相 对简单,导致其拟合能力受限.因此传统机器学习适 用于人工提取特征已十分充分、对可解释性要求 高、数据和计算资源受限的情况下使用.本文对科学 发现中常用的传统机器学习方法与相应科学文献 的总结见表 1.
2.2 深度学习方法
深度学习可以从原始数据中逐层自动提取特 征,是一种重要的表示学习方法. 其网络结构复杂, 对大数据具有更好的拟合能力,适用于解决图像、 序列、图等数据中的复杂难题.相对于传统机器学习 方法,近年来越来越多的研究使用深度学习进行科 学发现,实现了一些重大的科学突破. (1)卷积神经网络 卷积神经网络(Convolutional Neural Network, CNN)是一种含有卷积层的前馈神经网络,以擅长 处理图像数据著称,经典网络包括 LeNet[64]、 AlexNet[65]、ResNet[66]等.由于图像数据是一种重要 的科学数据类型,因此 CNN 在科学领域得到广泛 应用. CNN 不仅适用于图像数据,其在时序数据上 也具有良好的效果,避免了循环神经网络不可并行 的缺点.全卷积网络(Fully Convolutional Network, FCN) 和 时 域 卷 积 网 络 (Temporal Convolutional Network, TCN)是两种典型的用于处理序列数据的 CNN 模型. FCN 起初用于对图像进行像素级的分类 [67],Wang 等人[68]将其应用于时间序列分类任务中, 并取得了良好效果.时域卷积网络 TCN[69]相较于 FCN 加入了因果卷积,从而使得每个时间点的输出 只与更早的输入有关,防止了信息泄露. 在科学发现任务中,CNN 模型主要用于对图像 数据或可以转化为图像数据的信号进行分类与回 归,但也不乏用其处理序列数据的研究[40] .在天文领域,CNN 模型被广泛用于处理观测图像和光谱,从 而完成天体分类[41]、红移估计[42]等任务.在高能物 理领域,科学家将探测器的输出映射为图片中的像 素值,进而使用 CNN 实现粒子喷注的分类[43] .超过 90%的医学数据为影像数据[20],因此在医学领域广 泛使用 CNN 模型进行辅助诊断,例如皮肤癌分类 [44]、COVID-19 肺炎的诊断和预测[45]等.
除分类与回归问题以外,CNN 模型也可用于异 常检测.在时域天文学中,通过对连续两帧观测图像 相减,可以检测到短暂出现的科学事件[46],完成暂 现源检测任务.另外,图卷积神经网络作为卷积神经 网络在图领域的推广,在化学、材料等具有图结构 数据的领域实现新的突破.例如科学家可以将原子 和化学键分别表示为分子图中的节点和边,利用图 卷积神经网络预测反应物到产物的每个原子对之 间的化学键变化[47]。
(2)循环神经网络
循 环 神 经 网 络 (Recurrent Neural Network, RNN)是另一种重要的深度学习模型,与善于处理 图像数据的 CNN 不同,RNN 是为了更好地处理序 列数据而设计的.其通过引入状态变量存储过去时 间信息,让网络具有记忆.在科学发现任务中,长短 期记忆网络(Long Short-term Memory, LSTM)[70]和 门控循环神经单元(Gated Recurrent Unit, GRU)[71] 是两种常用的循环神经网络,二者均解决了在时间 步数过大时 RNN 的梯度衰减问题,可以更好地捕 捉时间序列中的长期依赖关系[72]. GRU 相对于 LSTM 更为简单,参数量更少,加快了训练速度. 在科学发现任务中,RNN 主要用于序列数据的 分类与预测问题.在时域天文学领域,RNN 常用于 对光变曲线等序列进行建模分析,如基于光变曲线 的星系分类[50]、引力透镜参数估计[48]等.在高能物 理领域,基于 RNN 的 Jet 分类模型解决了因探测器 大小不同而导致 CNN 模型中部分信息丢失的问题 [51] .在有机化学领域,通过分子简写式对 RNN 进行 训练可以生成新型分子结构[52,53] .在生物领域,RNN 可用于处理基因和蛋白序列数据,例如预测转录因 子识别位点[54]、利用氨基酸序列预测酶的生化功能 [55]、预测非编码基因的功能[56]等.另外在时域天文 学中,可利用 RNN 完成暂现源检测任务,根据实 时预测的光变曲线与真实接收的光变曲线的差距, 判断是否检测到暂现源候选体[57] . (3)深度生成模型 CNN 和 RNN 均为判别模型,另一种重要模型 为生成模型,在科学领域也存在普遍应用.判别模型 根据观察变量 X 直接学习条件概率分布 P(Y|X)或决 策函数 F(X),用于直接推断,学习准确率高. 而生 成模型对输入与输出数据的联合概率分布 P(X,Y)进 行建模,相比于判别模型,其训练难度更大、模型 结构更复杂[73],但因其出色的生成能力得到广泛研 究.变分自编码器(Variational Auto-Encoder, VAE)[74] 和生成式对抗网络(Generative Adversarial Network, GAN)[75]是两类常用于科学发现的深度生成模型.与 传统的自编码器通过数值描述潜在空间不同,VAE 以概率的方式描述潜在空间,在数据生成方面具有 优势. GAN 由生成器和判别器组成,生成器通过调 节参数试图生成判别器无法辨别真假的伪样本,在 二者博弈的过程中,生成器可以生成更为接近真实 样本的数据,从而实现数据的自动生成与信息补全. 在科学发现任务中,生成模型主要用于生成新 数据或重建旧数据.在天文领域,可以利用 VAE 生 成高质量星系图像进而对暗物质进行研究[58]、利用 CosmoGAN 生成引力透镜[59]、利用 GalaxyGAN 重 建星系图像[60]等. 在高能物理领域,利用 GAN 模 拟粒子经过每层探测器后形成的“物理照片”,可 以实现样本的快速生成[61] .在化学领域,利用 VAE 将离散的分子简写式编码为隐空间的连续变量,进 而通过随机解码、扰乱或插入的方式可以产生新的 分子结构[62] . 在新药研发领域,结合 VAE 与 GAN 可以生成具有特定抗癌活性的分子[63] .
**小结:**深度学习方法直接对原始数据进行挖 掘,擅长探索高维数据的隐含结构与相关性,可以 学习出科学家暂时所无法明确提取的复杂特征与 规律、突破人工提取特征的局限性、避免偏差、减 少计算特征的时间开销,相比于传统的机器学习实 现了更加卓越的效果.但与此同时,其消耗的数据资 源与计算资源更多,在资源敏感的科学场景下受到 了限制.并且由于模型结构复杂、不可解释,一些保 守的科学家对其持怀疑态度,这在一定程度上限制 了深度学习在科学领域的应用[12,76] .因此深度学习 模型适用于计算与数据资源充足、问题复杂、人工 特征提取困难或者效果不佳、对可解释性要求不高 的场景.本文对科学发现中常用的深度学习算法与 相应科学文献的总结见表 1.
2.3 科学发现的任务分类
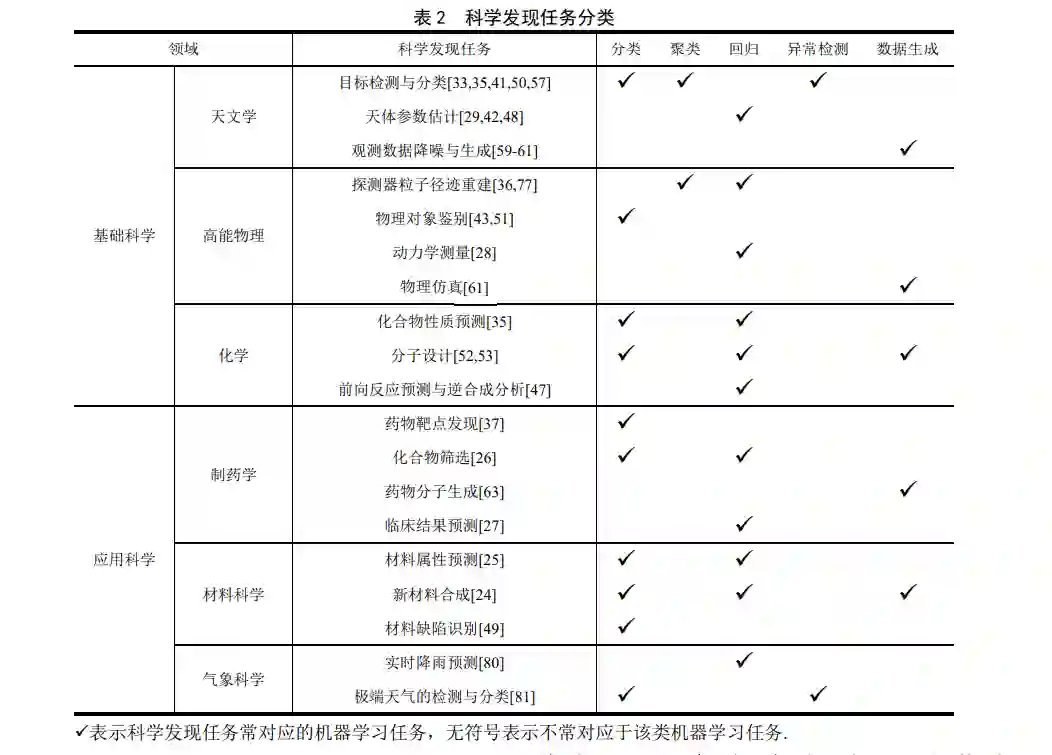
机器学习与科学发现的交叉研究主要集中在 数据积累充足、数字化程度高的学科中,而在基础 物理等基础理论研究中,由于缺乏大量样本而难以应用.本小节以天文学、高能物理、化学、新药研发、 材料设计、气象科学 6 个应用程度较高的领域为例, 梳理机器学习在各领域所擅长处理的科学发现任 务,并将不同的科学发现任务总结为分类、聚类、 回归、异常检测和数据生成 5 种机器学习问题.
(1)基础科学领域
随着大型观测设备的发展,飞速增长的数据促 进了机器学习在天文学中的应用,主要包括以下几 种任务[12]:1)目标检测与分类[33,35,41,50,57],如暂现源 检测和星系分类,可转化为机器学习异常检测、分 类或聚类问题,其中暂现源检测在离线分析的基础 上,还要求实时捕捉短暂的异常现象;2)天体参数 估计[29,42,48],如根据光谱与测光数据估计天体的质 量、元素丰度等物理量,属于机器学习的回归问题;3)观测数据的降噪与重建[59-61],如对观测图像进行 超分辨率重建,从而在硬件成本一定的情况下获得 更高的数据精度,可对应于数据生成问题.机器学习 减轻了天文学家的负担,提升数据处理的效率,尤 其在处理图像与光变曲线等特征复杂的数据类型 时,深度学习成为了天文学家的首选方案. 在高能物理领域,以对撞机为代表的一系列大 型科学装置产生了海量的科学数据,使得该领域具 有应用机器学习的数据基础.由于传统算法的开发 难度大、优化困难、难以并行,无法胜任处理海量 数据的科学任务,因此促使了物理学家使用机器学 习进行科学发现研究[16] .主要任务包括[77]:1)探测器 粒子径迹重建[36],涉及回归与聚类问题;2) 物理 对象鉴别[43,51],如粒子种类鉴别和粒子喷注(Jet)标 记,可对应于机器学习的分类问题;3) 动力学测量 [28],如簇射动力学参数估计、重离子碰撞喷注横动 量估计,属于回归问题;4) 物理仿真[61],如生成 喷注图像、电磁簇射,对应于机器学习的数据生成 问题. 随着化学信息学的发展,机器学习在化学领域 同样展现出显著优势,来自柏林自由大学的科学家 利用深度学习计算薛定谔方程的基态解,实现了准 确度和计算效率的突破[78] .当传统的化学研究理论 面对复杂体系时,预测能力有限,大部分新发现依 靠大量的实验“试错”,偶然性与不确定性强、效 率低、成本高[17] .而机器学习凭借其强大的学习能力 和计算能力,提升了研究效率.主要任务包括:1)化 合物性质预测[35],如活性、毒性、溶解度等,根据 预测数据类型不同可分为分类与回归问题;2) 分子 设计[52,53],如设计具有特定性质的分子,涉及机器 学习的预测与生成问题;3) 前向反应预测与逆合成 分析[47],如根据反应物预测生成物,或从产物出发 预测可能的前体,可对应于机器学习回归问题.
(2)应用科学领域
近年来利用机器学习进行药物研发成为一种 行业新趋势.传统的新药研发方式面临着费用高、成 功率低、耗时长的困境,因此全球多家制药企业与 人工智能企业开展了深度合作.机器学习在新药发 现和临床前研究两个阶段实现了重大突破[18,79],具 体任务包括:1) 药物靶点发现[37],确定药物靶点 是药物研究的基础,主要对应于机器学习的分类问 题;2) 化合物筛选[26],即选择对某一特定靶点活 性较高的化合物,属于分类或回归问题;3) 分子生 成[63],即根据已知化合物分子的结构和成药性等规 律,合成新的化合物作为候选药物分子,对应于数 据生成问题;4) 临床结果预测[27],如预测新靶点 和候选药物的性质和作用,属于机器学习回归问题. 事实证明,利用机器学习技术辅助新药研发,可以 大幅缩短研发周期、降低研发成本、提高研发效率. 随着材料数据的积累,机器学习被用于有机材 料、光伏、半导体等材料设计的各个领域.面对巨大 的设计空间,基于理论研究、实验分析、计算仿真 的传统方法无法高效研发出新材料,大量试错实验 导致研发效率很低[19],这一问题与传统新药研发所 面临的困境具有相似之处.因此材料科学家将数据 驱动的机器学习应用于新材料开发的过程中,主要 任务包括:1) 材料属性预测[25],即从成分、能量 特征等参数出发,研究材料性质的变化规律,属于 机器学习的分类或回归任务;2) 新材料合成[24], 涉及机器学习的分类、回归与数据生成问题;3) 缺 陷识别[49],如根据材料薄板裂纹图像识别缺陷,可 对应于图像分类问题.机器学习的应用避免了成本 昂贵的实验和大量计算,极大地提高了新材料的研 发效率. 在气象科学领域,DeepMind 与气象科学家合 作利用机器学习实时预测降雨量[80],开辟了实时降 雨量预报的新途径,该任务可对应于机器学习回归 问题.类似的,还可以进行飓风、风暴等极端天气的 检测与分类[81],可对应于异常检测与分类问题. 如 此的研究不胜枚举,机器学习方法已经广泛应用于 各个科学领域,并在科学探索与发现任务中发挥着 重大作用. 小结: 综上所述,本文将科学发现任务与对应 的机器学习问题总结为表 2. 大部分科学发现任务都可以转化为机器学习领域的分类与回归问题,依 据不同科学数据类型,可进一步分为图像分类或序 列分类问题等.聚类、数据生成与异常检测问题相对 较少. 此外,一些科学任务通过离线挖掘实现,如 天体参数估计,对实时性没有要求;而另一些科学 发现任务,由于科学现象稀有且短暂,例如天文暂 现源检测,不仅需要离线分析,实时检测更有意义. 当然以上的划分边界并不总是清晰明确,需要 根据具体的科学问题与场景具体分析,才能将科学 任务转化为合适的机器学习问题.综上,机器学习突 破了传统方法的瓶颈,被广泛用于获得新的科学视 角,成为智能科学发现的有效途径.
3 智能科学发现
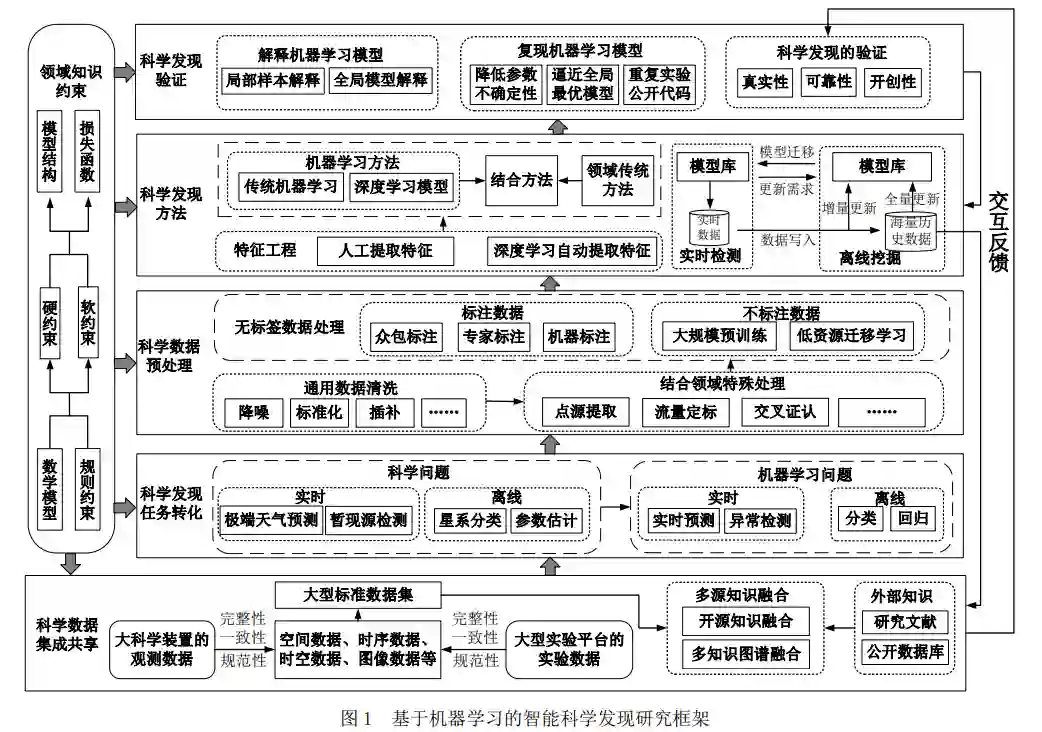
综合分析机器学习在各科学领域的研究现状, 本文认为,当前大部分研究聚焦于特定的科学任 务、着力解决具体科学问题,而机器学习在各科学 领域面临着诸多共性的困难与挑战,亟需一个通用 的智能科学发现框架用以指导科学家进行高效的 科学发现研究. 因此,本文提出了基于机器学习的智能科学发 现研究框架,作为“AI for Science”的典型范例, 阐述一种高效的智能科学发现模式,为各领域科学 家使用机器学习进行科学发现提供解决方案. 框架 分为科学数据集成共享、科学发现任务转化、科学 数据预处理、科学发现方法、科学发现验证以及领域 知 识 约 束 六 个 部 分 , 具 体 如图 1 所示.各部分之间并非独立,而是相互反馈, 提高了框架的智能性.本节按照框架组成的顺序,依 次分析机器学习在科学发现任务中面临的共性问 题,并提出解决方案.
3.1 科学数据集成共享
大规模的科学数据是应用机器学习的基础,然 而科学数据分散在各国科研机构,因此将科学数据 进行集成与共享为智能科学发现框架保证了数据 基础. 当前,国内外有诸多科学数据中心,如国际 科学联合会世界数据中心①、中国科学院科学数据 中心、美国国家航空航天局空间科学数据中心等. 但目前,科学数据集成与共享普遍面临着缺乏 有效融合、标准数据集建设不足以及质量参差不齐 三个方面的问题,阻碍了机器学习发挥更大潜能. 第一,虽然有多种集成的数据库供科学家使用,但 其对数据间关联挖掘不足,缺乏有效的知识融合机 制[13],如天文学家需手动查找多种波段的数据库才 能获取一个天体的完整信息,不利于科学家高效检 索与使用;第二,目前科学领域侧重于将分散的科 学数据集中起来,但缺乏针对共性问题而建立的统一大型标准数据集[12],不利于对解决同一问题的各 种方法进行比较;第三,科学数据具有不确定性强、 多源异构等特点[13],目前公开发布的科学数据存在 着精度不同、格式不同、处理方法不同等数据质量 参差不齐的问题. 因此,为了提高数据检索和使用的效率,需对 多源异构数据进行知识融合,利用知识图谱构建与 补全技术,构建并完善科学领域知识图谱.具体可通 过两个层面实现:①从开源科学数据库、历史文献 中上获取大量结构化/非结构化信息,挖掘多种科学 数据类型在时空范围、内容属性、主题分类、类型 格式等方面的关联,自动抽取三元组,从而在各学 科构建领域知识图谱;②融合多个已有领域知识图 谱,不断丰富和完善语义信息,扩大知识图谱的应 用范围. 通过知识图谱技术促进物理目标之间、物 理目标及其文献描述之间、文献描述之间的数据与 知识融合,有助于科学家快速检索,并服务于对科 学发现结果的高效验证. 此外,各个科学领域内需针对共性问题建立高 质量的统一大型标准数据集,从而便于对不同方法 进行统一测评;数据集成方需提升对数据内容的完 整性、一致性、规范性的检查力度,发布数据的精 度、不确定度和适用范围,从而提升数据质量
3.2 科学发现任务转化
在获取科学数据后,将科学发现任务转化为合 适的机器学习问题是实现智能科学发现的重要环 节.在 2.2 节本文已经较为详细地讨论了各种科学 发现任务与分类、回归、聚类、异常检测、数据生 成 5 种机器学习问题的对应关系. 除此以外,科学 发现任务还包括离线挖掘和实时检测两大类:一些 科学发现任务通过分析历史数据完成,如天文学的 星系分类与参数估计,大量的历史数据中包含着全 面的信息,无需随新数据的产生而实时分析;而另 一些研究短暂科学现象的任务,通过实时的方式完 成更有意义. 如天文学的暂现源检测,实时进行异 常检测可以及时调用精度更高的观测设备,从而更 为清晰地观测稍纵即逝却稀有的科学现象. 实时的科学发现任务需要将离线和实时两种 机器学习问题结合考虑:离线训练的数据量大,可 以涵盖全局特征,模型精度高,但训练时间长;而 实时收集的数据代表了最新的数据特征,当数据分 布发生变化时,已有模型难以发挥作用. 因此,实 时的科学发现任务不仅需要利用离线挖掘的模式, 还需要根据实时收集的数据对已挖掘的模式进行 补充和更新. 确定了机器学习的研究问题,可以有针对性地 指导后续的数据预处理.如分类问题通常需要均衡 的数据集,而异常检测问题则不需要,因此二者所 需的数据预处理方法不尽相同.另外不同的机器学 习问题也对应着不同的机器学习方法. 将科学发现 任务转化为机器学习问题是承接科学大数据集成 共享与科学大数据预处理及后续流程的关键步骤.
3.3 科学数据预处理
科学大数据通常采集于大规模科学装置或大 型实验设备,由于观测条件以及设备的限制,科学 数据具有不确定性强、信噪比低等特点,因此在科 学数据飞速增长的同时,其中的噪声和冗余信息也 会随之增加. 为了使机器学习方法不受数据噪声和冗余信 息的干扰,需要根据不同的研究问题,对数据进行 有针对性的预处理.另外由于科学数据具有不可重 复、不可随意更改等特性,因此相比于互联网大数 据,对科学大数据的预处理过程具有更多的限制, 流程更为复杂. 首先,对科学数据的预处理包含基本操作,如格式转换、数据降噪、数据插补等常规清理.其次, 在每一个科学领域还具有其独特的预处理方法,不 恰当的预处理方法容易引入误差,影响机器学习算 法的性能,进而阻碍科学发现的进程.例如在时域天 文学领域,光学观测设备采集的原始数据为图像数 据,在进行基本清洗处理后,还需要经过点源提取、 交叉证认、流量定标等预处理步骤才能形成最终的 光变曲线数据[7,82,83] . 另外,科学大数据的标签非常有限[12],可在预 处理阶段增加标注量,也可采取相反的方式,即仅 利用标签有限的数据.对于第一种方式,科学领域普 遍通过生成模拟数据实现,或众包标注、专家标注. 星明天文台公众超新星搜寻项目是一个典型的众 包标注项目,自 2010 年开始运行已发现 30 颗超新 星① .然而,对科学数据进行标注相对于常识标注更 为困难,如干旱现象比动物类别更难界定,因此有 很多科学项目是业余爱好者难以完成的,从而需要 科学家亲自标注. 但人工标注的成本较高,另一方 面,模拟数据不能完全反映数据的真实情况,因此 使用机器自动标注是一种值得探索的方式,可以更 为经济高效地扩充科学数据的标签. 直接利用标签有限的数据是另一种解决思路, 如迁移学习和预训练方法. 在低资源情境下利用迁 移学习方法可以把开放领域中的研究模型迁移到 科学领域中来,从而降低对科学数据的标注需求. 基于自监督的大规模预训练模型使用大量未标注 的样本学习数据中的共性,不针对特定的下游任 务,预训练完成后再将其应用到特定任务上,利用 有限的标注数据进行微调. 其优点在于可以降低对 标注数据的需求,帮助下游任务模型更好地初始 化、加速收敛、避免过拟合,缺点在于大规模的预 训练往往需要大量的训练样本以及庞大的计算资 源,这对于普通学者而言具有难度. 而近年逐渐发 展的科学计算平台能够带来解决方案,其整合了世 界上各科学项目的数据资源,同时拥有很强的计算 基础设施,如虚拟天文台[84] .利用科学计算平台可以 实现科学大数据的大规模预训练,从而解决科学大 数据标注样本稀少的问题,为普通学者利用机器学 习方法进行智能科学发现助力.
3.4 科学发现方法
经过数据预处理后,采用合适的方法是科学发 现任务的核心,包括领域传统方法与机器学习方法两大类.领域传统方法通常为科学模型,具有极强的 理论保证,并经过了大量实践的验证,具有较强的 外推能力,但通常具有效率较低、建模困难等缺点;机器学习方法包括传统机器学习和深度学习方法 两大类,极大地提高了科学研究的效率,但缺乏严 谨的理论证明和可解释性. 领域传统方法和机器学习方法各有优缺点,有 效的手段是通过一定的方式将二者进行结合,相互 补充,扬长避短. 例如,很多科学模型需要参数, 但这些参数难以根据基本原理获得[85],因此可以利 用机器学习方法从一个候选集合中学习最优参数, 从而实现动态智能地参数化科学模型;当一个理论 模型的子模型具有半经验性质,同时拥有足够数量 的观察样本时,可利用机器学习模型替代该子模 型;或通过“并行”与“串行”的方式将机器学习 方法与领域传统方法“级联”使用,从而纠正传统 方法的建模残差. 对于实时科学发现任务,可通过机器学习的在 线学习或增量学习完成:在线学习模型[86]以数据流 为输入,并立即更新模型,但不注重对旧知识的保 持能力;增量学习[87]也能够不断处理连续的信息 流,并在学习新知识的同时保持旧知识,任务增量 学习和类增量学习是研究较为广泛的两种类型.但 由于仅利用增量样本进行学习,因此逼近“原样本 +增量样本”的全局最优点成为研究难点. 本文提出实时-离线交互反馈机制来应对实时 科学发现任务.该机制在离线层利用全部历史数据 进行训练进而形成模型库,能够涵盖更全面的特 征;实时层收集的科学数据以批量的形式合并到离 线数据库,并定时对离线模型库进行增量更新.当实 时层模型库难以应对最新数据时,实时层提出更新 需求,将离线学习的模型库迁移至实时层.由于增量 更新难以逼近全局最优模型,因此离线层会定期进 行全量更新,并将模型同步至实时层进行科学发现. 实时-离线交互反馈机制提高了实时科学发现的智 能性.
3.5 科学发现验证
当前大部分研究聚焦于利用机器学习算法提 高科学发现的效率和准确性,但对机器学习模型的 验证不足,这关乎结论是否严谨且符合科学意义. 本框架提出从模型可解释性、模型可重复性,结果 真实性三方面对科学发现进行验证.
**可解释性:**科学家所熟知的基于概率统计的建 模方法能够根据数据分布的假设求出预测偏差与置信区间,模型可解释性强[12] .而众多机器学习方法 仅从结果上说明其有效性而缺乏严格的理论证明, 系统误差较难估计,牺牲了部分可解释性和科学严 谨性,受到部分科学家的质疑. 因此,可使用机器学习的解释技术对模型进行 解释,包括对样本的局部解释和对模型的全局解释 两大类:对样本的局部解释可以清晰地呈现模型对 每一个样本的决策依据,全局解释可以呈现模型对 整体的评估而降低样本间差异的影响.通过对模型 进行解释,可以揭示成功的原因,或分析失败的教 训用以改进模型,甚至有可能帮助发现新的科学规 律.近年来有科学家尝试对机器学习模型进行初步 解释,判断其是否符合科学意义.例如在天文学领 域,通常利用基于梯度、灵敏度分析的可解释方法 找出对模型重要的特征,进而判断其是否符合领域 知识[88-90] .
可复现性:可复现性是科学方法的基本属性, 要求其他研究人员可以重复同样的过程,一个不可 重复的科学发现无法作为其他科学研究的基础,因 而失去价值.但目前机器学习方法的可复现性受到 争议[15],这其中的原因包括代码和数据未公开、模 型结果对训练条件敏感(算力、数据划分、初始化和 超参数不同)等. 因此提高机器学习模型的可复现性的具体做 法包括:减少模型在参数初始化过程中的不确定 性、通过设置周期学习率等方法避免局部最优参数 从而逼近全局最优模型[91,92]、多次重复实验过程以 验证结果的可复现性,并公开代码、数据和训练参 数设置等信息以供他人验证和使用. 真实性:最后,还需要结合历史文献和公开数 据库等开源数据验证科学发现的真实性、可靠性、 开创性.以时域天文学为例,当机器学习算法对光变 曲线进行处理产生疑似事件后,科学家需要通过天 文数据库、历史文献等多种数据源,综合分析天体 位置、历史观测信息、光变曲线质量等多方面信息, 才能发现异常信号背后的真相、确定疑似事件的真 伪、确定是否首次发现该天体发生耀发现象等.而利 用“数据集成共享”阶段构建的领域知识图谱,可 以帮助科学家进行更为高效的后期验证.
3.6 领域知识约束
在机器学习过程中整合科学领域知识是实现 智能科学发现的必备手段,也是与其他机器学习应 用的本质区别.领域知识有多种形式,通常为数学方 程的形式,如解析表达式和微分方程,或者以规则 约束的形式表示实例或类之间的关系,如对称性、 不变性、时空相关性、渐进极值、守恒定律等. 领 域知识可通过硬约束和软约束的形式与机器学习 模型整合:硬约束为不可违背的约束,用约束问题 替代无约束优化问题,在训练过程中强制执行;软 约束的执行程度可变,如损失函数. 领域知识可以通过模型结构和损失函数两方 面与机器学习模型进行结合[93] .其一,通过修改模型 结构,引入强归纳偏置,使模型遵守领域约束,从 而产生更具一般性和可解释性的模型,如在模型中 增加物理变量[94]、编码对称性约束[95]、基于物理信 息进行模型结构搜索[96]等.其二,通过修改损失函 数,使其包含领域知识,鼓励模型与先验知识保持 一致,这是一种软约束,可以提高模型的收敛性、 泛化性,并减少所需的训练数据量. 领域知识贯穿整个智能科学发现框架,在科学 发现任务转化、科学数据预处理、科学发现方法、 科学发现验证等方面都起到至关重要的作用:在任 务转化时结合领域知识才能保证等价性;在数据预 处理时结合领域知识,可以生成模拟数据、减少对 数据量或数据标签的需求,也可以在特征工程中提 取或选择具有物理意义的特征,提高可解释性;在 科学发现的方法中结合领域知识,可以加快机器学 习模型的训练速度、纠正模型的优化目标、提高准 确性;在验证过程中结合领域知识,可以判断模型 结果是否与已知的科学原理相一致,验证模型的可 解释性和结果的可靠性. 唯有紧密围绕科学属性与领域知识约束,才能 保证模型产出的科学价值,抛开领域知识、盲目使 用通用算法的方式在科学发现任务中是行不通的.
4 实验分析
时域天文学是一个典型的“大数据+AI”的科 学领域,大视场短时标巡天设备是该领域的观测利 器, 该设备具有超大视场覆盖和高时间分辨率的数 据采样特性,奠定了该领域的大数据基础. 地基广 角 相 机 阵 (Ground-based Wide Angle Cameras, GWAC)[47,83,88]是我国自主研发的大视场短时标时 域天文观测设备.本节以 GWAC 实际产生的光变曲 线(星等 Mag 序列)数据为研究对象,以恒星耀发 (Stellar Flare)[97]这种典型的瞬变事件为科学发现目 标(如图 3 所示),以本文提出的“基于机器学习的 智能科学发现研究框架”为指导,通过实验分析各种科学发现方法优劣,验证框架的有效性.本文的代 码和数据公开于 GitHub 开源社区①和阿里天池实验 室② . 首先,本案例将发现瞬变事件这一科学任务转 化为机器学习的时间序列分类问题.其次,为了应对 数据存在“间断性”和“类别不均衡性”两方面的 挑战,本文通过数据截断和数据增强两种方式进行 预处理.具体地,本文根据文献[98]所揭示的类太阳 恒星耀发活动的特征时间,对间隔过大的序列进行 截断处理;在文献[99]提出的耀发模型的基础上, 通过更改模型参数实现对耀发幅度、持续时间、耀 发位置的多种变换来生成耀发信号,并与已有负样 本进行叠加实现数据增强,使训练集的正负样本比 例达到1:4. 测试集仍保持实际数据分布. 经过上述 预处理,最终的实验数据集包含 152635 条光变曲 线子序列,其中训练集、验证集与测试集的比例约 为 6:2:2. 接下来我们在 4.1 节介绍科学发现方法, 4.2 节分析各方法的优劣,4.3 节进行科学发现验证。
5 总结与展望
综上所述,机器学习已经在科学发现任务中发 挥了重大作用. 尽管本文提出了基于机器学习的智 能科学发现框架,并通过实验验证了其有效性,但 仍有一些挑战问题值得探讨,具体包括: 虚假关联问题.在一般情况下,通过绘制热力图 等方式对机器学习模型进行解释,可以判断模型的 决策依据是否为虚假关联,如文献[102]通过 LIME 分析机器学习模型将雪地上的哈士奇错误地分类 为冰原狼的原因,结果表明模型关注的是雪地而非 犬类特征,由此可知模型利用了“雪-冰原狼”的虚 假关联.然而,科学数据中蕴含着未知知识,因此当 模型的决策依据与已有先验知识不符时,科学家难 以判断模型的决策依据为虚假关联还是未知的科 学知识,从而难以判断科学发现的可靠性. **高效验证问题.**目前科学领域对模型进行解释 的研究工作大部分面向单一样本,即利用可视化的 方法对样本逐个绘制热力图,科学家需要依次检查 模型的关注点是否与科学意义相符.当面对海量数 据时,此种方式会耗费科学家大量的时间和精力, 带来巨大的负担.因此未来需要结合领域特点,基于 概率统计理论模型,设计统计层面上的高效解释方 法,让科学家对数据和模型的整体情况有更加直观 的了解,节省科学家的时间与精力. 模型易用性问题. 在科学发现过程中利用机器 学习方法可以提高科学发现的效率.但实际应用时, 机器学习尤其是深度学习对于科学家仍然存在较 高的门槛.尽管 TensorFlow[103]、PyTorch[104]等机器 学习框架提高了机器学习的易用性,但其面向通用 任务,尚未考虑科学领域的需求. 在这一方面,生物领域已经领先迈出一步. Paddle Helix⑨是基于百度飞桨深度学习框架开发的 生物计算平台,用于新药研发、疫苗设计、精准医 疗等多种任务,成为学术界与工业界结合的典范. 未来学界与业界需要秉持更加开放的精神,共同建 设新的科研基础设施,打造智能科学发现的科研共 同体,帮助科学家使用强大的工具实现重大的科学 突破. 最后,在应用机器学习完成科学发现任务的过 程中,
本文总结以下三点经验教训: **机器学习方法并非万能. **在机器学习的过程中 整合科学领域知识是实现智能科学发现的必备手 段,也是与其他机器学习应用的本质区别.虽然机器 学习方法愈加流行,但基于专家知识的领域传统方 法仍具有较强的优势,不可摒弃,需要通过合适的 方式将领域传统方法与机器学习相结合,才能更好 地完成科学发现任务.
机器学习需要扬长避短. 基于统计的传统机器 学习与基于神经网络的深度学习各有优缺点,适用 于不同的应用场景.领域科学家需要根据不同的场 景选择合适的机器学习方法,扬长避短,合理利用 机器学习技术突破传统方法的局限性,实现高效的 科学发现.
领域与方法具有倾向性. 在不同的学科领域 中,机器学习技术的研究与应用程度相差甚远.在拥 有海量科学数据同时面临维度灾难问题的科学领 域中,机器学习得到更为广泛和充分的研究.同时, 深度学习方法相较于传统机器学习方法,也得到越来越多的关注与研究,实现了更为重大的科学突破. 机器学习能够以自动化或半自动化的模式帮 助科学家产出科学成果,提高科学发现的效率.但面 对最前沿、最复杂的问题时,仍需要人工智能学者 与各领域的科学家汇聚在一起,形成统一的计算思 维,同时恰到好处地利用机器学习工具,才能形成 重大的科学发现与研究成果.
