
源自:自动化学报 作者:马宁, 曹云峰 摘要
自主着陆技术是制约无人机 (Unmanned aerial vehicle, UAV) 自主性等级提升中极具挑战性的一项技术. 立足于未来基于视觉的无人机自主着陆技术的发展需求, 围绕其中的核心问题——着陆场检测与位姿估计, 对近十年来国内外无人机自主着陆领域中基于视觉的着陆场检测与位姿估计方法研究进展进行总结. 首先, 在分析无人机自主着陆应用需求的基础上, 指出机器视觉在无人机自主着陆领域的应用优势, 并凝练出存在的科学问题; 其次, 按不同应用场景划分对着陆场检测算法进行梳理; 然后, 分别对纯视觉、多源信息融合的位姿估计技术研究成果进行归纳; 最后, 总结该领域有待进一步解决的难点, 并对未来的技术发展趋势进行展望. 关键词
自主着陆 / 无人机 / 机器视觉 / 着陆场检测 / 位姿估计 / 信息融合
近年来, 由于具备成本低、可避免人员伤亡等优势及优越的ISR (Intelligence, surveillance, and reconnaissance) 能力, 无人机作为一种灵活、高效、低风险、全天候的态势感知平台, 在军民领域都得到了广泛的关注和应用. 在科索沃战争、纳卡战争、俄乌冲突等现代战争中, 无人机执行了大量的侦察监视、火力导引、目标指示和战斗毁损评估等重要军事任务, 对提高现代化作战能力、丰富作战手段有着重要意义. 1. 应用需求分析
尽管无人机的相关核心技术自问世以来在不断发展和进步, 目前各类无人机的着陆阶段仍是飞行中风险最高、最具技术挑战性的阶段之一. 据美国国防部技术报告统计, RQ-2“猎人”和RQ-5“先锋”无人机在自主降落过程中发生事故的概率约为50%; 2019 年8 月, 英军装备的“守望者”无人机在着陆时复飞失败, 于越过着陆点约900 m处坠毁; 同年8 月, 瑞士邮政无人机在配送包裹测试中, 由于GPS 通信受阻, 连续发生了两起紧急着陆坠毁事故[1−2]. 据悉, 三成以上的无人机飞行事故发生在着陆阶段, 其中海基着陆比陆基着陆的事故率还要高6 倍左右[3].
无人机的自主控制等级 (Autonomous control level, ACL) 是由美国空军研究实验室 (AFRL) 提出的对无人机自主能力进行通用量化评估的指标[4]. 如图1所示, 目前全球鹰、捕食者等国际最先进的无人机的自主性水平仅为2∼3 级, 而自主着陆技术恰是制约无人机自主性等级提升的关键技术, 它不仅是实现无人机回收和重复使用的前提, 也是实现空域安全的重要保障[5]. 美国国防部高级研究计划局 (DARPA) 在2013 年启动的“战术侦察节点” (TERN) 项目中就提出了具备自主起降能力无人机的设想[6]. 欧洲航空安全局 (EASA) 在2020 年发布的人工智能路线图中明确指出, 机器学习是未来提升无人机自主飞行与着陆的自主性和可靠性的重要方法[7].
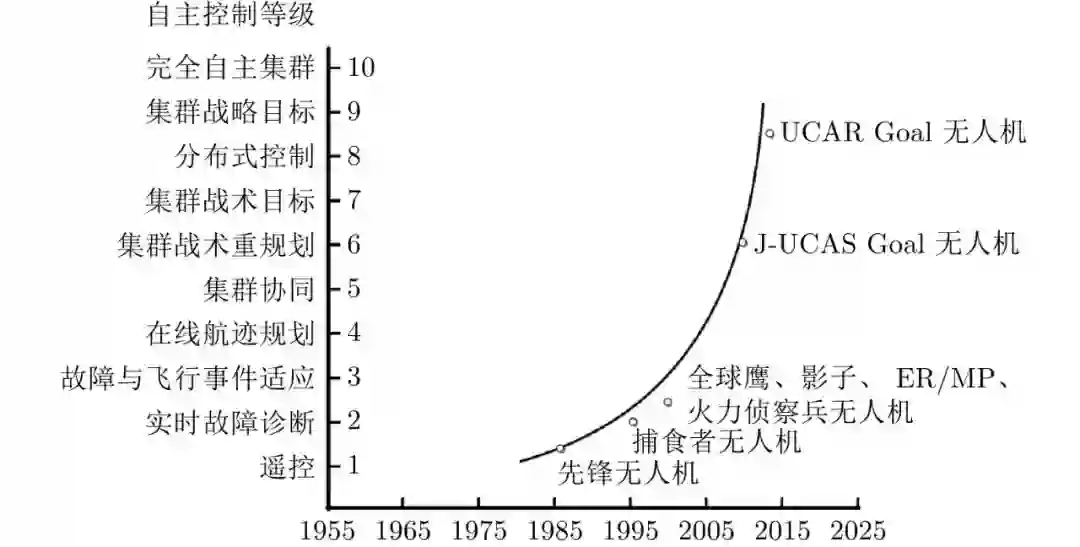
图 1 无人机自主控制等级规划 对于无人机的自主着陆而言, 能否获取可靠的、鲁棒的、高精度的位姿参数是影响着陆任务成败的关键. 如表1所示, 美国联邦航空局 (FAA) 给出了明确的精密进近与着陆标准[8]: I 类标准为在60 m 的决断高度下, 水平误差标准为9.1 m, 高度误差标准为3.0 m, 角度容差为7.5%; II 类标准为在30 m的决断高度下, 水平误差标准为4.6 m, 高度误差标准为1.4 m, 角度容差为4.0%; III类标准为在15 m的决断高度下, 水平误差标准为4.1 m, 高度误差标准为0.5 m, 角度容差为4.0%. 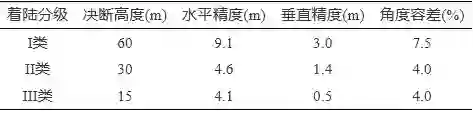
美国 DARPA 在2016 年公开的CODE (Collaborative operations in denied environments) 项目中就提出了拒止(Anti access, AA) 环境下作战的需求[16]. 在拒止环境下, 卫星信号将受到干扰、遮挡、欺骗等攻击, 机载GNSS 等设备将无法通过通信数据链路顺利获取可信的导航参数. 而机器视觉具备自主性及抗干扰能力强等优势, 也随着计算机视觉技术的快速发展与不断创新, 成为了近年来补充或取代传统方法的最主要解决方案。
基于视觉的自主着陆是指利用机载视觉传感器实时获得图像, 采用图像处理技术实时解算出无人机的位姿等着陆导引参数. 早期的研究中, 基于景象或地形的匹配技术是主要采用的方案, 而由于严重依赖于离线地理数据的完备性, 并受到地图大小、搜索范围、匹配算法以及时间、季节、光照变化等方面的制约, 难以为无人机提供高精度、高实时的着陆导引参数[17]. 近年来, 随着边缘设备算力的提升与图像处理算法的不断创新, 国内外许多研究者致力于将机器学习等方法应用在着陆场检测、相对位姿估计等方面, 基于视觉的自主着陆研究更针对于开放场景, 并逐渐走上了智能化发展道路. 葡萄牙海军研究中心 (CINAV) 于 2019 年公开的AUTOLAND 项目[18]及空中客车公司于2020 年公开的ATTOL (Autonomous taxi, take-off and landing) 项目[19]均发起了机器视觉在无人机自主着陆应用上的尝试. 德国慕尼黑工业大学 (TUM) 于2022 年公开的C2LAND 项目[20]进展报告中指出, 仅依赖光学等机载设备实现无人机的自主进近与着陆具备可行性. 毋庸置疑, 基于视觉的着陆导引方式是未来无人机着陆的重要发展方向。
依据传感器的工作原理, 机器视觉可以通过主动视觉和被动视觉的方式实现地面目标的位姿估计[21]. 如图2所示, 主动视觉如结构光、ToF (Time of flight) 等通过主动发射投影光源及接收被测物体表面反射的光波信息[22−24], 能够直接获取目标的位置和深度信息, 但受限于投影光源, 其测量范围极其有限, 仅适用于小规模场景(10 m内)或室内应用. 被动视觉包括单目视觉和立体(双目等) 视觉, 其中双目视觉无需主动对外发射光源, 通过解算视差即可获取目标的位置和深度信息[25−26]. 需要指出的是, 当与目标的距离远大于基线距离时, 双目视觉就退化成了单目视觉, 因此测量范围也十分有限[27]. 上述机器视觉传感器的测量原理及特点归纳如表2所示. 这几种能够直接测量出距离和深度信息的视觉传感器又被称为深度相机, 尽管具备直接测量距离和深度信息的巨大优势, 受限于其有效测量范围, 一般只适用于室内等小范围场景下的定位, 而对于中型、重型无人机着陆/着舰等大范围场景不适用。
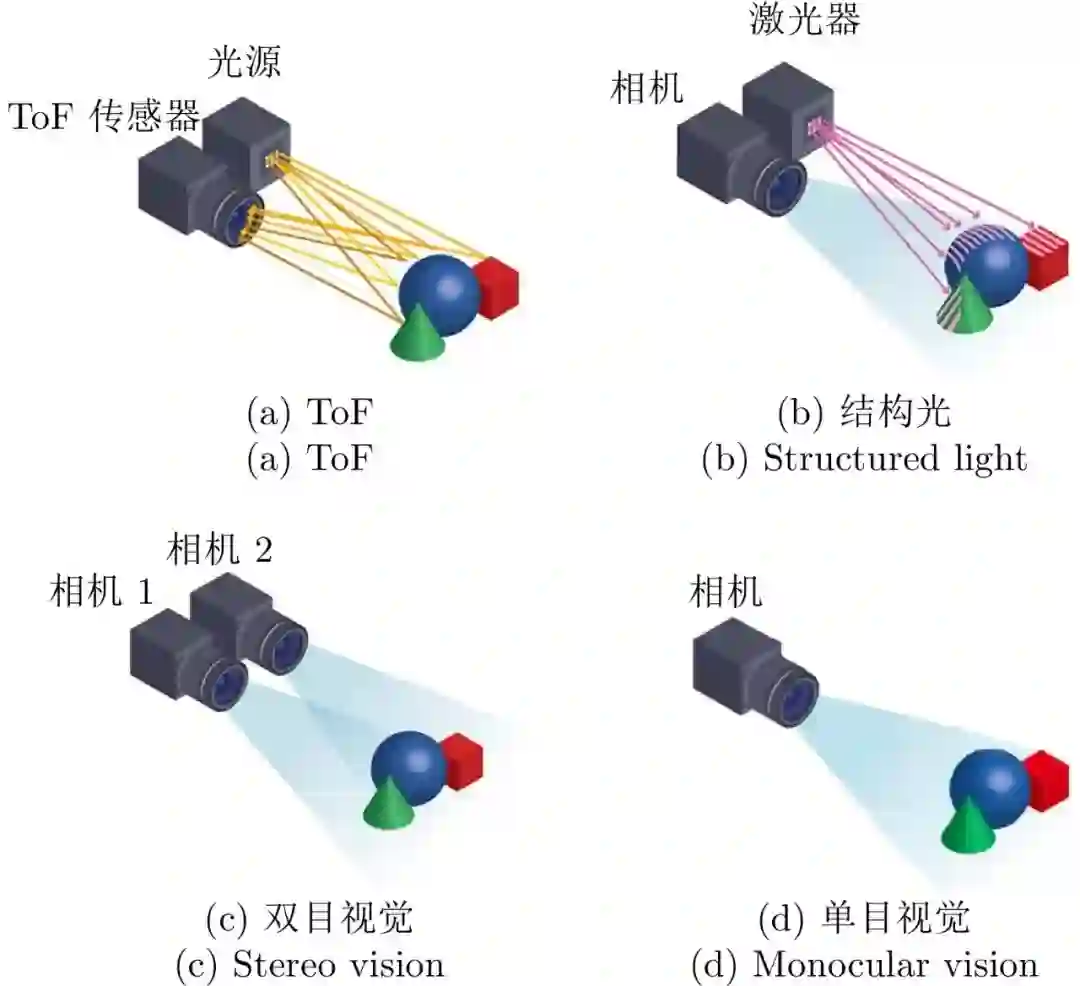
图 2 几种机器视觉传感器的测量原理示意图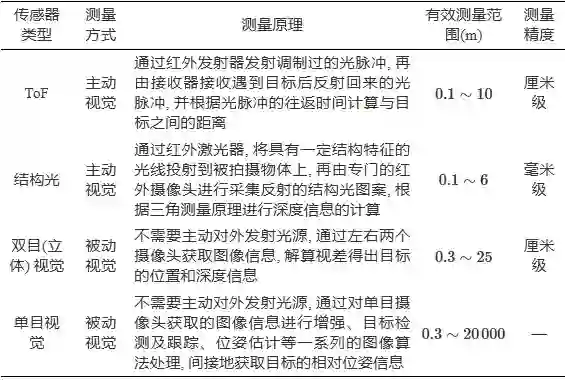
综上可知, 机器视觉是未来无人机自主着陆的潜在重要手段, 发展基于视觉的无人机自主着陆技术的需求愈发重大. 而如何利用观测信息最少、设备最简易的单目视觉实现高精度位姿估计, 则是其中亟待解决的核心问题. 然而, 在目前已公开发表的学术论文中, 系统性综述面向无人机自主着陆中基于视觉的位姿估计方法的文章还不多. 为进一步支撑我国未来无人机自主化、智能化研究与发展, 有必要对该领域的研究进展进行梳理. 为此, 本文立足于近十年来国内外基于视觉的相对位姿估计相关研究, 归纳和总结出代表性的研究方法及成果. 同时, 结合具体应用场景, 对该领域当前仍存在的共性科学问题及未来发展趋势进行展望. 2. 基于视觉的自主着陆问题描述
尽管国内外各研究团队研究的侧重点不同, 但基于视觉的自主着陆技术研究在框架上大致相同. 如图3所示, 基于视觉的自主着陆系统的主要模块与工作流程如下: 在无人机到达着陆进近点后, 首先, 机载视觉导引系统中的图像预处理模块对视觉传感器获取到的视觉信息进行图像信息增强, 以满足后续算法对图像质量和信息量的要求; 其次, 基于预处理后的图像信息, 同时参考着陆场跟踪模块给出的运动信息作为参考输入, 着陆场识别模块基于图像处理算法完成对图像中着陆场的定位, 作为位姿估计模块的输入; 然后, 相对位姿估计模块实时计算出无人机与着陆场之间的相对位姿; 最后, 无人机的导航、制导与控制系统根据相对位姿参数输出控制指令, 执行机构再基于动力学模型产生偏转, 如此循环, 直至引导无人机着陆. 由于视觉位姿测量原理的特殊性, 能否准确检测并稳定跟随着陆场是解算无人机相对位姿的前提, 而能否获取可靠的、鲁棒的、高精度的位姿参数是影响着陆任务成败的关键. 由此, 面向自主着陆的视觉位姿估计中的两项关键问题分析如下:
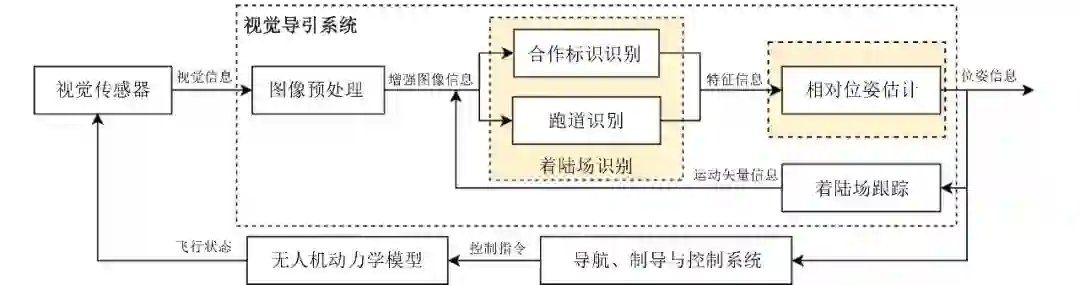
图 3 基于视觉的自主着陆系统结构图
-
着陆场检测: 着陆场检测是目标检测技术在无人机自主着陆这一特殊任务上的应用, 指从机载序列图像中检测出着陆场的位置并准确识别其类别的过程. 而区别于一般的目标检测问题, 着陆场检测具有一定的特殊性: 无人机自主着陆一般是一个由远及近的过程, 存在目标特征差异大和着陆场的边缘、角点等特征信息易受噪声干扰的问题.
-
相对位姿估计: 相对位姿估计是指从图像中提取出的特征信息并结合先验知识实现无人机自身相对于着陆场的位置和姿态估计的过程. 从图像处理层面来看, 视觉位姿估计可以抽象为一个透视映射的求解问题. 区别于一般的透视变换求解问题, 直接采用单目视觉进行测量的结果是不具备尺度的, 因此基于单目视觉实现有效位姿估计的前提为着陆场是合作的, 即视觉观测点对应的三维信息已知, 而视觉观测信息的提取依赖于着陆场检测, 则会带来误差传递、观测信息较少的问题. 3. 着陆场检测方法研究现状
在基于视觉的无人机自主着陆研究中, 国内外学者主要针对两种应用场景下的着陆场检测展开研究: 一种是面向合作标识着陆的应用场景, 通过设计特殊几何形状的着陆合作标识, 如“T”形、“H”形、圆形、矩形以及复合图形等, 进一步地可以增加颜色、温度等辅助信息, 或者采用类似于二维码的视觉基准标识系统(Fiducial marker systems, FMS), 如AprilTag、ArUco、ARTag 等[32]; 另一种则是面向跑道着陆的应用场景, 以跑道及其标志线为主要参照信息. 前者适用于大多数的无人机自主着陆场景, 是目前该领域中最常用的研究策略, 而后者则一般是面向需要借助跑道滑跑着陆的固定翼无人机或航母上着舰的应用场景. 因此, 针对不同的应用场景, 采取的着陆场检测算法也有所不同. 3.1 合作标识检测
目前, 在基于视觉的无人机自主着陆相关研究领域, 设计着陆合作标识是国内外学者最常用的策略, 对于不同机型、着陆方式、应用场景均具备适用性和可行性. 目前, 面向合作标识检测的研究主要包括三类检测方案: 第一类方案主要参照通用目标检测算法的流程, 针对所设计的着陆标识, 基于典型的点、线、矩等手工特征或卷积神经网络模型, 设计特定的检测算法来实现合作标识的检测识别; 第二类方案是将基准标识系统应用于着陆合作标识检测, 与第一类方案的区别在于其合作标识来源于基准标识库, 合作标识与预定义的检测算法配合使用从而实现着陆合作标识的检测; 第三类方案则是针对合作标识与背景具有显著的颜色、边缘等特征差异的着陆场景, 采用图像分割技术能够高效地从背景中分离出着陆合作标识.
3.1.1 基于典型特征的检测方法
在早期的研究中, 主流研究思路是将合作标识检测看作一个目标匹配问题. 由于无人机与着陆场的相对位置、视角不断发生变化时, 着陆合作标识在图像中的变化可近似于仿射变换, 因此基于仿射不变矩理论的合作标志检测算法是一种可行的思路. 为了弥补矩特征对噪声敏感的缺陷, 史阳阳[33]提出一种改进的仿射不变矩的着舰合作标识检测算法, 该算法将基于序列最小优化的向量机与仿射不变矩相结合, 并根据轮廓链码提出一种仿射不变矩的计算方式, 运算效率较高, 并且当光照、距离等变化时也能保证较高的识别精度。
进一步地, 为了更精确地描述合作标识的结构、纹理等特征, 边缘、角点、轮廓等局部特征相比于矩特征在运动场景下具有更强的鲁棒性. 由于环境因素, 舰基合作标识呈现出小幅度运动、轻微旋转及小程度缩放的特点, 考虑到边缘检测算子具有平滑去噪、加强边缘信息的优点, 史琳婕[34]提出一种结合Canny 算子与Hu 矩的“T”形合作标识检测方法, 并采用光流法对观测点持续跟踪, 在稳定性和实时性上均取得了较好的效果. 面向复杂城市环境中的着陆问题, 魏祥灰[35]设计一种三维合作标识, 先采用Canny 算子提取二值图像中的边缘信息, 再利用最小二乘法实现椭圆参数的拟合, 考虑到算法的效率, 采用快速性和鲁棒性较好的SURF 特征作为跟踪点, 采用KLT (Kanade-Lucas-Tomasi) 光流法估计当前帧的光流矢量, 利用前后帧之间的运动关系来预测特征点在当前帧的位置. 针对着陆近距阶段标识成像不完全及图像畸变的问题, Jung 等[36]提出一种基于 DLS (Direct least square) 的近距离目标识别方法, 设计含颜色特征的圆环和“H”形合作标识, 采用颜色特征进行分割并通过DLS 方法实现椭圆拟合, 有效解决了在标识不完全成像情况下的着陆问题。
近年来卷积神经网络 (Convolutional neural network, CNN) 在目标检测领域取得了重大进展, 由于深度特征具备多层级多维度的目标表观描述能力, 无论是在识别精度还是速度上都远远超过了传统方法. 丁沙[37]针对无人飞艇自主着陆中的“H”形地面小尺寸标识的检测问题, 设计一种基于特征金字塔的改进YOLO (You only look once) 网络模型的检测方法, 首先在原始YOLOv3-tiny 网络靠近输入、靠近输出和网络两端部分分别增加不同规格的卷积层, 以重点提取浅层网络的细粒度信息和深层网络的语义信息, 从而有效地提升检测精度, 再结合特征金字塔的思想, 将浅层的特征和深层的特征进行融合, 使得特征图具有较小的感受野, 能提升对小尺寸目标的检测效果, 从而提升飞行器的自主避障能力和飞行安全性. 针对舰基合作标识在远距下滑导引阶段存在视野占比小、尺度变化大、成像模糊等问题, Li 等[38]提出一种基于改进SSD (Single shot multibox detecter) 网络的“H”形舰基合作标识检测方法, 该方法通过融合高低层特征以增强网络对小目标的识别能力, 并基于互补滤波融合SSD 和KCF (Kernel correlation filters) 算法以提升检测速度, 实现了对合作目标的连续检测与跟踪. 针对上下坡等复杂场景下, 因移动着陆平台的不规则运动而出现遮挡、消失、尺度变化等导致无法稳定跟踪着陆平台的问题, 蔡炳锋[39]提出一种融合YOLOv3-tiny 网络模型和改进TLD (Tracking learning detection) 跟踪方法的合作标识实时检测方法, YOLOv3-tiny 生成候选框以替代检测模块的扫描窗口操作, 再利用TLD 算法中的在线学习模块, 其中正样本选取跟踪成功的目标框附近200 个图像元, 负样本以误判的候选框作为输入对分类器进行训练, 并采用卡尔曼滤波来预估目标的轨迹, 提升了算法的检测速度及鲁棒性. 面向移动车辆上的自主降落问题, 袁俊[40]提出一种Cascade R-CNN 网络模型与SIFT (Scale invariant feature transform) 特征相结合的方法, 将预检测的结果作为先验信息, 再结合SIFT 特征匹配得到车辆目标, 从而实现跟踪, 在目标遮挡的情况下也具有较好的效果. 吴鹏飞等[41]针对复杂着舰环境下的着舰合作标志识别鲁棒性问题, 提出一种改进的SSD 网络模型着舰标志识别方法, 该方法针对SSD 网络小目标识别率低的缺点, 基于深度残差网络和特征金字塔网络结构对SSD 网络进行改进, 采用ResNet101 代替原有的VGG-16 网络, 并采用特征金字塔网络结构改进传统的上采样结构, 然后将检测网络的高层语义信息融入低层特征信息中, 当合作标志在图像中是小目标时也能够准确检测, 并降低了误判的概率. 针对无人机着陆合作标识被遮挡和暂时离开视野后重新返回视野时无法再次定位的问题, 王欣然[42]将主动学习与强化学习结合, 提出一种基于主动强化学习的着陆地面标识识别ALLNet (Active landmark localization network) 网络模型, 其结构借鉴了小型网络VGG-M 模型, 包含三个卷积层和两个全连接层, 相比于深层网络在视觉追踪定位上具有更好的表现, 该模型在训练阶段引入强化学习思想, 首先利用马尔科夫决策过程 (Markov decision process, MDP) 对着陆标识识别问题进行建模, 将支持向量机 (Support vector machine, SVM) 的分数作为MDP 的奖励函数, 判断是否成功定位着陆地标, 并引入主动学习策略实现了小样本下着陆地标精确定位, 但缺点是该方法的计算效率较低。
3.1.2 基于基准标识系统的检测方法
AprilTag、ArUco、ARTag 等视觉基准标识系统是由一组预定义的标识及其检测识别算法组成, 利用类似于二维码的图标实现快速识别标签及解算相机与标识间的相对位置和姿态, 给无人机自主着陆技术的模块化发展带来了新的思潮. 为了使四旋翼无人机在着陆过程中在不同高度阶段都能采集到有效的视觉引导信息, 杨建业[43]基于AprilTag 设计了复合着陆图标, 并基于 MobileNet 网络模型设计两级级联的检测网络来对着陆图标进行检测, 其中第一级网络进行粗检测, 负责剔除掉大部分非目标标志区域, 第二级网络则对第一级网络筛选出的目标区域进行精细的关键点检测. 针对AprilTag 识别算法中的全局梯度计算量大的问题, 为提高目标识别的实时性, 王兆哲[44]提出一种基于ROI (Region of interest) 的改进AprilTag 识别算法, 通过设定 ROI 参数采用选择区域的方法以缩小目标识别算法需要处理的图像范围, 并结合CMT (Consensus-based matching and tracking) 算法进行目标跟踪, 可以在一定程度上减少运算量, 增加处理速度. 考虑到无人机很难在0.1∼7 m的高度之间都能看清楚靶标, 许哲成[45]设计一种三层嵌套的AprilTag 靶标, 能够有效避免在较低飞行高度下目标的丢失, 并且提出一种基于 ROI 区域的加速检测方法, 大大提升了识别的速度, 使得无人机可以持续定位到靶标. 由于嵌套类的降落标识缺乏编码信息, 难以实现无人机的多场景选择性自主降落, 陈菲雨[46]对常规ArUco 标识利用HOG 特征和SVM 分类器进行检测识别, 该方法具有不易受光照变化影响的优势, 又考虑到降落过程中需要对降落目标进行长时间的跟踪, 将TLD 框架与KCF 的跟踪算法融合, 并从多特征融合、尺度自适应方面进行改进, 有效提高了复杂背景下对着陆合作标识准确识别、稳定跟踪能力. 针对无人机撞网回收中的目标丢失、短暂遮蔽及实时性差等问题, 张航[47]提出一种结合分辨率调整和局部搜索策略的改进检测算法, 采用卡尔曼滤波预估二维码的中心点位置, 并以此划分出感兴趣区域以缩小搜索空间, 从而提升了算法效率, 并且在一定程度上减小了环境噪声的干扰. 为提高无人机距移动平台较近时的降落精准度, 郭佳倩[48]设计一种具有嵌套特征的无人机着陆标志, 根据AprilTag 编码原理采用阈值法实现着陆标识的检测识别, 在微抖动、强光和干扰的场景下也能达到较高的识别率。
3.1.3 基于图像分割的检测方法
目标检测算法占用着巨大的计算资源, 对于实时性要求极高的自主着陆技术研究来说并不乐观. 由此诞生了另一种思路, 对于一些颜色、边缘等特征与背景具有较为明显差异的着陆标识, 采用图像分割技术将图像中的着陆场与背景等不感兴趣的区域分离以降低算法的复杂度, 如最为经典的阈值化分割方法, 根据某一确定的亮度常量即阈值来分割图像中的物体和背景, 具有计算速度快的优点. 郭通情[49]设计一种紫色与黄色相间的圆环型辅助降落标志, 根据辅助降落标志颜色的独特性, 采用自动阈值分割算法从图像中分离出辅助降落标志和不感兴趣的背景, 再基于颜色直方图进行匹配来判断目标的相关性. 颜色特征是能够描述图像中色彩空间分布的全局特征. 充分利用颜色特征设计合作标识能够与环境背景进行区分, 易于定位及提高合作标识识别的准确率. 由于HSV 模型对于复杂背景、光照下的颜色的提取能力较强, 席志鹏[50]采用红蓝色调设计一种复合圆形标识, 首先基于HSV 空间的取值分别对红色和蓝色进行分割, 再进行形态学处理以去除孤立的噪点, 最后采用Canny 算子提取目标的边缘信息, 能够有效防止边缘噪声的进一步放大. 为了解决无人机在无人艇自主降落过程中传统算法处理水面低照度图像适应性较差的问题, 郭砚辉[51]将MSR 理论与小波变换融合, 提出一种低照度条件下的图像增强网络LLIE-Net, 再基于视觉显著性分析理论, 提出一种基于FastMBD的图像分割方法, 该方法能够高效地计算目标的显著图, 并通过自适应阈值分割和区域生长算法对无人艇进行目标识别. 为增强无人机对着舰环境的感知理解, 刘健等[52]提出一种改进的ERFNet 网络模型着舰场景语义分割方法, 采用图像分割的手段从图像中分离出辅助降落标志和不感兴趣的背景, 进而提取出视觉观测点。 3.2 跑道检测
对于固定翼无人机来说, 一方面由于无法悬停, 并且质量一般要远远大于轻小型的旋翼无人机, 撞网等回收方式一般不适用, 必须借助跑道滑跑着陆, 而跑道相比于合作标识在图像特征上更为复杂, 且在机载图像视角中多呈现为不规则的几何形状; 另一方面, 中大型固定翼无人机着陆过程下滑阶段速度很快, 在着陆出现失误时可供修正的操纵权限非常小, 其容错性要远远低于旋翼型无人机, 跑道检测对于实时性和准确性需求远高于合作标识检测. 目前, 面向跑道检测的研究主要包括两类检测方案: 一类是聚焦于跑道的几何特性, 通过构建直线、边缘等几何特征的检测算子来实现跑道检测; 另一类方法则是参考一些通用的深度学习目标检测框架, 在其基础上进行改进, 以满足对跑道检测的特殊要求。
3.2.1 基于几何特征的检测方法
传统跑道检测方法通常采用直线特征来描述其外观特性, 如Hough 变换就是跑道直线检测中应用最为广泛的方法, 但由于易发生检测出较多冗余直线的问题, 算法的计算量较大. 为满足机载实时性需求, Wang 等[53]提出一种基于改进FDCM (Fast directional chamfer matching) 的跑道检测方法, 由于原始FDCM 中采用的直线拟合算法RANSAC (Random sample consensus) 计算十分耗时, 该方法通过引入线段检测器LSD (Line segment detector), 在不影响算法精度的前提下大大提升了计算效率, 能够满足机载算法的实时性需求. 考虑到固定翼无人机飞行速度快的特点以及在巡航过程中因光照或者障碍物造成目标遮挡的情况, 李灿[54]提出一种基于视觉辅助的自主着陆算法, 首先使用通道级剪枝方法对YOLOv3 网络模型以40% 比例进行剪枝, 以满足着陆场检测的实时性需求, 再引入DeepSort 目标追踪算法来应对目标遮挡的情况, 旨在提高整体算法的鲁棒性, 并采用概率Hough 变换及冗余线段筛选实现跑道检测, 该方法仅在跑道存在概率较大的范围内进行Hough 变换, 从而缩短了计算时间。
然而, Hough、LSD 等传统的线特征检测方法在低照度、弱对比度、模糊、遮挡或杂波等情况下检测能力较差. 因此, Zhang 等[55]提出一种由粗到精的分段式跑道检测方法, 该方法采用EDlines (Edge drawing lines) 线特征检测方法从目标区域中快速提取出直线段, 再根据投影模型推算跑道的方向和跑道两条边线之间的夹角, 将线段碎片调整拟合从而实现跑道的边缘检测, 有效弥补了传统线特征检测方法的缺点. 面向固定翼无人机自主着舰的应用需求, Zhang 等[56]提出一种多特征融合的着舰区域识别方法, 该方法利用基于频域残差的显著性分析方法实现了着舰候选区域的快速提取, 在此基础上提取图像中的SIFT 特征描述子, 并计算SIFT 描述子在过完备字典上的稀疏投影, 进而在空间金字塔框架下完成全局特征与局部特征的融合, 最大程度保留了特征在图像上的空间分布关系, 最后利用线性SVM 分类器完成对航母候选区域的识别, 大大提升了航母着舰区域识别算法的处理速度和鲁棒性. 针对低照度条件下的着陆跑道检测问题, Nagarani 等[57]提出一种融入形态学特征的跑道轮廓预测方法, 在特征提取中引入自适应灰度共生矩阵, 以提升纹理特征的表达能力, 并通过数字高程图 (Digital elevation map, DEM) 数据融入跑道区域的形态学特征, 提升了跑道边缘检测的准确性, 有效改善了不良天气情况下的视觉感知能力. 为提升跑道检测算法应对复杂背景、光照变化、噪声干扰的性能, Abu-Jbara 等[58]提出一种基于区域竞争分割的跑道检测方法, 该方法仅采用了简单的跑道局部几何模型, 即, 除跑道相对于周围环境的不相似性和跑道边缘的直线特性外, 没有对跑道的外观做任何假设, 并结合特定能量函数的最小化策略来检测和识别跑道边缘, 能够满足大多数跑道着陆场景的实时性和鲁棒性需求. 考虑到SIFT 等手工特征的计算量较大, 若对每一帧图像都采用SIFT 算法检测, 会导致算法实时性较差, 因此Tsapparellas 等[59]提出一种结合SIFT 和CSRT (Channel and spatial reliability tracker) 的跑道检测算法, 该算法对关键图像帧使用SIFT 算法进行跑道形状检测, 然后基于检测到的感兴趣区域采用CSRT 算法跟踪连续视频帧中的边界框, 跟踪一定数量的非关键图像帧后, 再对下一个关键图像帧采用SIFT 进行精确检测, 由此减少整个流程的计算时间. 该算法在复杂天气条件下的仿真测试中具有较高的准确率和实时性。
3.2.2 基于深度特征的检测方法
通用的深度学习网络框架具有优越的目标检测性能, 但应用于自主着陆任务中的着陆场检测还面临以下局限性[60]: 对目标区域的回归能力有限, 只能以矩形框给出跑道的粗略位置, 检测结果包含一定的背景区域; 对类内目标的泛化能力有限, 如难以同时满足停机坪着陆及跑道着陆等不同场景下的着陆场检测问题. 为实现精确的跑道轮廓检测, 梁杰等[61]提出一种基于典型几何形状精确回归的机场跑道检测方法, 该方法综合利用典型四边形角点回归策略、四边形锚框机制、四边形的非极大值抑制模块以及目标几何拓扑关系, 实现了对目标在仿射畸变下成像特征的学习, 并在 YOLOv3 网络模型基础上进行轻量化设计和模型压缩, 提升了跑道角点预测的准确性和高效性. Shang 等[62]和尚克军等[63]设计一种面向固定翼无人机着陆的跑道语义分割网络RunwayNet, 其编码–解码结果实现了浅层网络中丰富的细节特征与深层网络中抽象的语义信息的融合, 主干网络采用轻量级的ShuffleNet V2, 并引入注意力模块以提高网络的感受野和全局特征提取能力, 具有较好的分割效果, 作用范围可达3 km。 3.3 小结
着陆场检测典型方法及实验结果等梳理如表3所示. 分析可知, 基于传统手工特征的检测方案在检测精度和实时性的综合表现上仍具有较大优势; 基于深度学习的方法虽具有较高的检测精度且能够有效应对非理想着陆场景, 但实时性有所欠缺, 检测速度一般不超过20 Hz. 对于合作标识的检测, 基于图像分割的检测方案虽一定程度上降低了算法的复杂度, 提升了着陆场的检测速度, 但检测精度略逊于其他方案; FMS 的应用为着陆标识检测效果带来了显著提升, 其检测精度一般不低于95%, 而未来面向复杂背景、光照变化等非理想着陆场景仍有发展空间。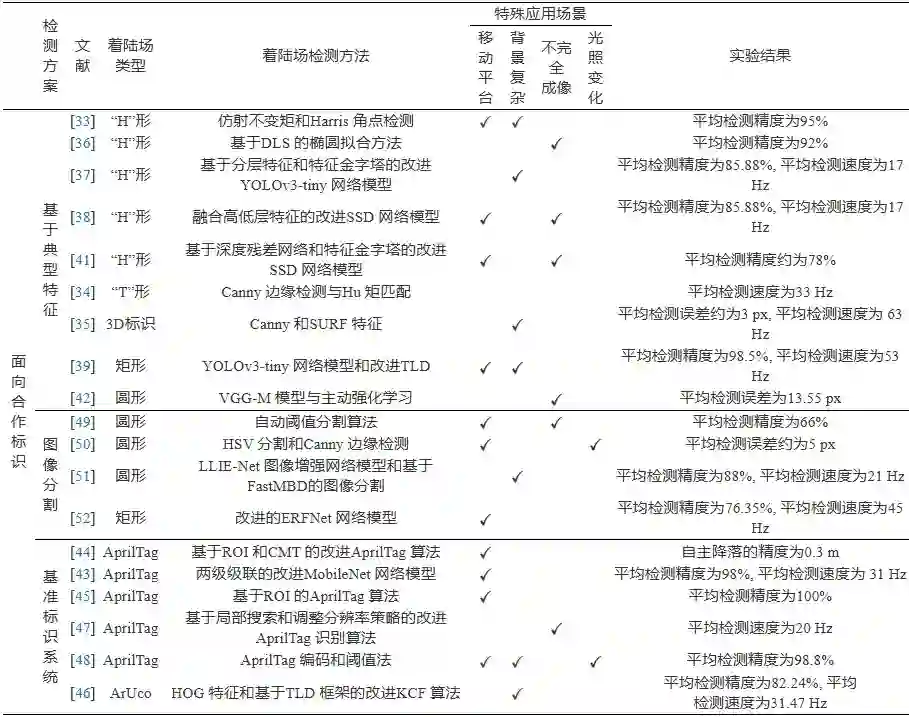

表 3 典型的着陆场检测方法总结 综上可知, 基于视觉的着陆场检测经历了从传统手工特征检测发展到基于深度学习方法的过程. 然而, 着陆场检测的研究未来仍面临着如计算资源受限、场景规模较大、先验知识不足等问题. 对于计算资源受限的问题, 目前的一些研究中采用了网络剪枝、级联检测、数值加速等方法, 但同时也带来检测精度降低等问题. 大规模场景下的着陆场检测始终具有挑战性, 从数据增强、多尺度特征融合、超分辨率等技术进行突破可能是有效的手段. 对于未来一些非合作场景着陆的应用需求, 域外泛化、增量检测等技术是潜在的解决方案。 4. 基于单目视觉的位姿估计方法研究现状
基于单目视觉的相对位姿估计本质上是一个二维视觉观测信息与三维空间之间变换关系的求解过程. 一般地, 这个变换可以用一个六自由度的透视投影来描述, 即需要求解一个平移向量和一个旋转矩阵. 而无人机自主着陆过程中的位姿估计又是一个与时间变量有关的状态估计问题, 因此本节按照是否利用帧间约束, 从独立帧和连续帧两方面来递进地分析基于单目视觉的位姿估计方法的研究现状。 4.1 基于独立帧的位姿估计方法
基于独立帧的相对位姿估计是指, 利用单帧图像的视觉观测信息, 根据相机模型建立其在像方坐标系与对应物方空间坐标系之间的对应关系, 再求解出透视变换关系. 其中, 若无特殊情况, 一般的相关研究通常采用的是针孔相机模型. 区别于一般的透视变换求解问题, 单目视觉的测量结果是不具备尺度的, 因此要基于单目视觉实现有尺度的位姿估计的前提是着陆场是合作的, 即着陆场的三维信息已知. 另外, 由于视觉观测信息的提取依赖于着陆场检测, 不同的着陆场检测策略得出的观测信息不同, 其问题描述及求解方法也有所不同。
4.1.1 基于点特征的求解方法
基于点特征的位姿估计可以抽象为一个PnP (Perspective-n-point) 问题的求解. 如图4所示, 定义Pi∈R3 为世界坐标系{W} 下的三维观测点, 点 pi∈R2 为点Pi 在像平面上的投影. 根据针孔成像模型及投影变换可得
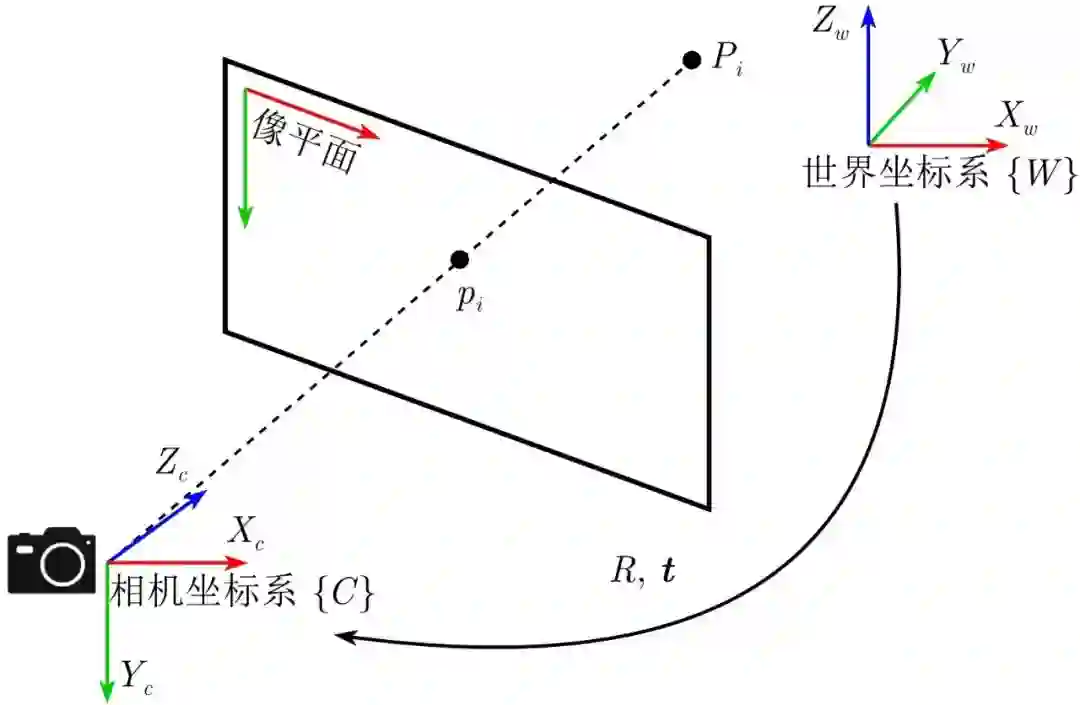
图 4 PnP问题的数学描述
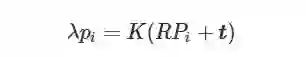
(1) 式中, λ为尺度因子, K为相机内参矩阵, R∈SO(3) 表示世界坐标系到相机坐标系的旋转矩阵, t∈R3 表示世界坐标系到相机坐标系的平移向量, RPi+t 表示点Pi 在相机坐标系{C} 下的表达。
当相机内参K 已知时, 利用观测点Pi 及其在图像坐标系上的投影pi 解算相机坐标系与世界坐标系之间的旋转矩阵R和平移向量t即可求解PnP问题[64]. 一般地, 当观测点数目n>3 时, PnP 问题可求得闭式解, 其求解方法可分为线性法和迭代法. 典型的线性方法如直接线性变换 (Direct linear transform, DLT) 等具有计算过程简单的优点, 但由于解算过程中无法保证旋转矩阵的正交性且对噪声较为敏感, 线性方法的计算精度较低; 而迭代法一般需要先由线性法求出初始解, 通过构建目标函数使其收敛到期望的结果, 计算过程更为复杂, 其代表性算法包括最小二乘法、高斯–牛顿 (Gauss-Newton) 法、L-M (Levenberg-Marquardt) 法、正交迭代 (Orthogonal iteration, OI) 等。
张洲宇[65]根据跑道检测算法提取到的观测点, 提出一种基于正交迭代法的位姿估计方法, 该方法利用物方空间误差构造目标函数, 求解出基于三维空间点的定位误差最小约束, 再采用迭代法求解出无人机与航母甲板之间的相对位姿, 该方法能够避免陷入局部最优, 但对噪声较为敏感. 姜腾[66]提出一种基于Powell's-Dogleg 的位姿估计方法, 该方法把线性解作为 Powell's-Dogleg 算法迭代的初值, 并将 Gauss-Newton 法与梯度下降法结合, 在一个信赖域中选择迭代的方向和步长, 最终收敛到局部极小值点, 能够一定程度上降低线性初始解的误差. Meng 等[67]提出一种基于比例正交投影迭代 (Pose from orthography and scaling with iterations, POSIT) 的无人机着舰位姿估计方法, 首先利用比例正投影逼近透视投影, 从线性方程组中得到旋转矩阵和平移向量, 再利用新的观测点迭代计算新的比例因子直至满足设定的阈值, 其优点是只需利用少数观测点就能求解位姿且计算效率高。
对于理想的平面合作标识, 其观测点具有共面的特性, 位姿估计又可以转化为单应性变换 (Homography) 求解问题, 即PPE (Plane-based pose estimation) 问题. Patruno 等[68]提出一种基于单应阵分解的位姿估计方法, 先基于轮廓曲率提取出“H”合作标识的点线, 然后根据角点信息的共面特性计算其单应性矩阵, 从而求解得到位姿信息, 该方法在背景杂乱、标识部分遮挡及光照变化等情况下具有较强的鲁棒性。
多数的无人机姿态角测量方法采用的是固定焦距镜头, 而由于随着着陆过程中距离缩短, 固定焦距在一定程度上影响无人机姿态角的解算精度. 任丽君[69]提出一种适用于变焦距系统的姿态估计方法, 该方法将Ma.Y.B 编码方法与L-M 非线性优化方法结合, 仅从包含任意五个编码标志点的单帧图像中就可以解算出姿态角, 不仅精度高、收敛速度快, 而且还能够避免局部最优. Pieniazek[70]提出一种适用于变焦相机的位姿测量方法, 该方法针对机载图像中跑道的几何特征提取一组特定的点对, 这些点对同时也能构成跑道边缘的线段, 然后采用L-M 迭代法求解相对跑道的位姿, 该项研究采用MP-02 固定翼无人机在EPRJ 机场进行试飞实验, 并且该系统在距离跑道2 km以内均能够实现着陆导引。
随着无人机与着陆场相对距离的增加, 图像每个像素点所表示的面积也增大, 角点坐标提取误差的影响也相对增加. 黄琬婷[71]将传统角点特征与更加鲁棒的圆形特征相结合, 提出一种基于圆和角点特征的相对位姿估计改进算法, 利用圆心投影坐标消除基于单个圆求解的位置坐标和单位法向矢量的解的二义性, 然后通过任一角点辅助确定无人机相对于合作标识的航向, 相比传统的位姿估计方法精度得到了显著提升. 面向在近距降落阶段对合作地标的位姿解算, 李佳欢[72]提出一种基于最小二乘法的位姿估计方法, 首先采用Canny 边缘检测算子和最小二乘法拟合得到椭圆方程, 再利用空间关系推导解算出舰基合作标识在相机坐标系下的二义性位姿, 然后根据目标中心约束进行歧义校正, 同时依据“H”型合作标识的对称性来预测航向角。
针对现有主流PnP 解法存在不能兼顾精度和效率问题, 师嘉辰[73]提出一种基于角参数化的PnP 优化方法, 只需要用两个角参数即可表示旋转矩阵. 在此基础上构建非线性目标函数, 通过一个7 次多项式方程和一个4次多项式方程对旋转矩阵和平移向量分别求解, 并以此结果作为初值, 再利用Gauss-Newton 法进一步迭代优化, 根据重投影误差最小化的理论迭代得到位姿信息, 相比于现有算法, 在保证精度的条件下计算效率提升了7 倍左右. 针对垂直起降无人机在拒止条件下的着舰需求, Lee 等[74]参考有人机着舰的视觉辅助系统, 基于YOLOv3 构建了舰船指示灯检测网络模型, 通过检测矩形指示灯的角点作为观测点, 利用L-M 迭代求解相对位姿. 又考虑到距离着陆场较远时偏航角估计噪声较大, 引入单状态卡尔曼滤波器以优化偏航角的估计, 该算法在多次试飞验证中均实现了成功着陆。
4.1.2 基于线特征的求解方法
弱纹理背景下的点特征提取数量往往受到限制, 相比于点特征, 线特征能够实现三维空间位姿状态的描述, 对于光照变化和图像噪声等具有不变性, 并且对于遮挡具有较强的鲁棒性[75]. 如图5所示, 基于线特征的位姿估计可以抽象为PnL (Perspective-n-line) 问题的求解, 其数学描述如下: 定义L=(P,v) 为世界坐标系{W}下的三维直线, 向量v∈R3 为直线L 的方向向量, 点 P∈R3 为直线L上的任意一点, 线段 l为直线L在图像平面上的投影; 由中心投影可知, L , l 与相机坐标系{C} 下的光心Oc 共面, 令u为共平面 π的法向量, 当相机内参数确定时, 可以表示为
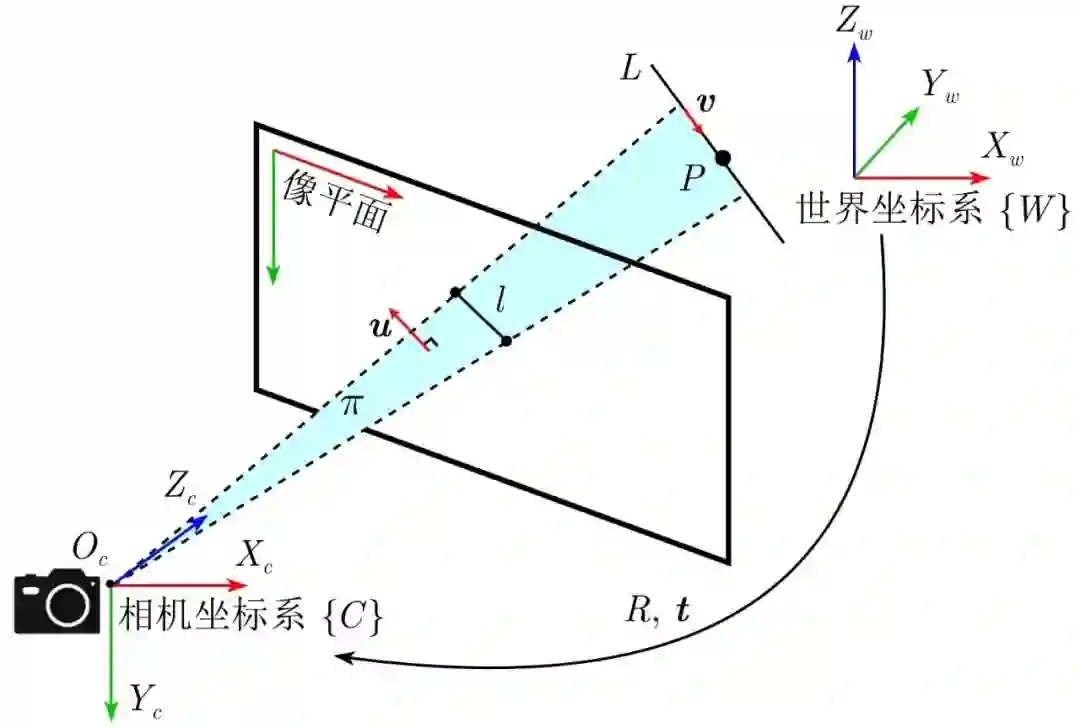
图 5 PnL问题的数学描述
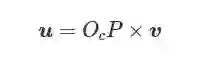
(2) 根据投影变换, 式(2)可以转化为以下形式
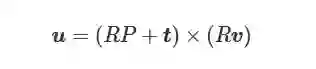
(3) 进一步展开则有
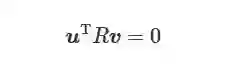
(4)
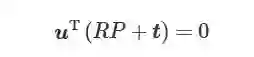
(5)
在直线L 及其投影l已知的情况下, 利用式 (4) 和式 (5) 求解出旋转矩阵R 和平移向量 t 即可实现对 PnL 问题的求解[76−77]. 与PnP 问题的求解方法类似, PnL 问题的求解法也分为线性法和迭代法, 如DLT 等线性方法效率高, 但精度一般较低, 并且无法求解直线数量小于6 的情况; 而最小二乘法、POSIT 等迭代法求解精度更高, 但是求解过程复杂, 效率十分低下. 另一方面, 线特征的匹配相比于点特征也更为复杂, 而在匹配直线较少时远不如PnP 求解精度, 目前在无人机自主着陆位姿估计中较少单独基于线特征实现位姿估计, 而更多的是采用直线约束与点特征相结合的策略. 贾宁[78]面向无人机自主着舰的应用需求, 提出一种基于点、线特征的相对位姿估计方法, 基于甲板跑道区域的跑道线、标识点等点线分布提取点线特征作为视觉观测点, 再利用点线特征的共线方程最小二乘求解出三个位置参数, 然后根据海天线求解相机滚转角和俯仰角. 但在不理想的天气及甲板晃动剧烈的情况下, 该方法的位置和姿态角估计难以保证较高的精度。 4.2 基于连续帧的位姿估计方法
基于连续帧的位姿估计方法则是将位姿估计构建为一个非线性优化问题, 通过深入挖掘目标在序列图像中的时、空域依赖关系, 利用图像帧间的约束来优化观测点, 如图6所示, 基于连续帧的位姿估计方法构建状态方程如下
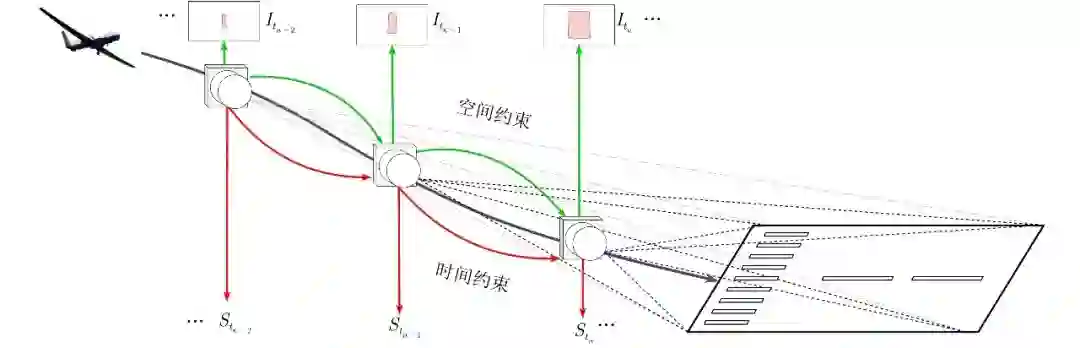
图 6 基于连续帧的位姿估计方法示意图
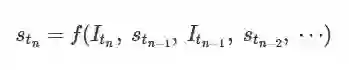
(6)
式中, 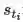
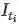
针对现有的位姿估计方法存在姿态角、高程测量误差较大的问题, 房东飞[79]提出一种基于多点观测的位姿估计方法, 在预设航迹下对目标在多点进行跟踪和图像采集, 并根据成像原理计算出目标与无人机的相对高低角和方位角, 然后建立系统状态方程和观测方程, 利用无迹卡尔曼滤波 (Unscented Kalman filter, UKF) 求出目标位置的最优估计值, 该方法还适用于特殊地形区域中的位姿估计. 针对室内环境下GNSS 信号易受遮挡的问题, Brockers 等[80]提出一种基于单目视觉的微型无人机室内自主着陆方法, 该方法利用SURF 实现高效的特征检测与匹配, 并建立帧间观测点的对应关系, 再采用单应性分解的方法估计每两帧之间的相对运动关系. 需要指出的是, 该方法仅适用于地面特征较多的着陆环境。
传统位姿估计方法依赖于图像中的点线等特征, 对光照变化和遮挡较为敏感, 并且涉及的环节和参数较多, 不利于工程实现. 为了增强算法对不同应用场景的适应性, 提高算法效率, 唐邓清[81]提出一种深度特征驱动的目标位姿端到端估计网络SPoseNet. 该网络以序列图像为输入, 先利用Mask R-CNN 的目标检测和分割网络实现目标检测分割, 然后在该网络框架中嵌入长短期记忆 (Long short-term memory, LSTM) 网络, 利用其选择性记忆功能实现当前时刻与历史时刻目标状态的有效融合, 最后构建位姿回归网络对目标位姿进行回归估计. 与经典的目标位姿端到端估计网络LieNet 相比, 在保持相同水平实时性的前提下, 分别实现23.64% 和21.19% 位置和姿态估计精度的提升. 为了提高运动场景下的位姿估计精度, 李朋娜[82]提出一种基于运动点剔除的位姿估计算法, 减少部分运动点所带来的误差, 该算法首先对前后帧图像生成的视差图采用基于形态学算法进行优化, 然后采用K-means 聚类算法对优化后的视差图进行聚类分割, 再根据几何约束条件判断每个聚类区域内点的运动状态, 最后基于聚类区域内点的分布与占比建立区域判断模型, 将运动的区域去除, 从而求解得到位姿. 该算法可以有效避免运动点对位姿估计的影响, 提高了位姿估计算法的稳定性和准确性, 相比传统算法标准差减小5 倍左右. 面向移动车辆上的无人机自主降落需求, 刘传鸽[83]提出一种多标识融合的位置估计方法, 先根据针孔相机模型与坐标系变换矩阵求解P4P 问题, 获得无人机与复合ArUco 每一个子标识之间的5 组位置关系, 再将多个标识物解算的位姿估计值进行加权融合, 然后根据二阶车辆运动模型, 采用UKF 预测目标在未来有限时间内的运动速度及方向, 使得无人机降落过程中视觉定位的精度提高了2.6%. 面向大场景下的视觉测量问题, 景江[84]提出一种基于多向交汇的视觉测量方法, 首先以线性解为初值, 采用L-M 迭代优化求解位姿, 然后根据单目多位置交汇测量原理, 以目标在不同时刻的成像建立光束平差模型, 由光束平差法 (Bundle adjustment, BA) 进一步优化目标的精确位姿。
4.3 小结
以上基于独立帧及基于连续帧的单目视觉位姿估计典型方法及实验结果等梳理如表4所示. 分析表4可知, 对于100 m以上的着陆测量范围, 两类方法均具有较好的位姿估计效果, 位置估计误差不超过2%, 姿态估计误差不超过2∘ ; 对于100 m以内的着陆情况, 两类方法的平均位姿估计误差相当, 位置估计误差在2%∼15% 内, 姿态估计误差在0.08∘∼10∘ 内, 而基于连续帧的位姿估计方法的类内差异较小. 此外, 一些能够有效利用着陆场特征或相对运动约束的方法具有更优的位姿估计效果, 如文献[69, 71−72, 81], 其位置估计误差不超过3%, 姿态估计误差不超过1∘ . 总体来看, 基于独立帧的位姿估计方法对于姿态估计仍具有一定优势, 而基于连续帧的位姿估计方法能够在一定程度上提升位置估计的效果, 并且适用于动平台、特殊地形等复杂的着陆场景。
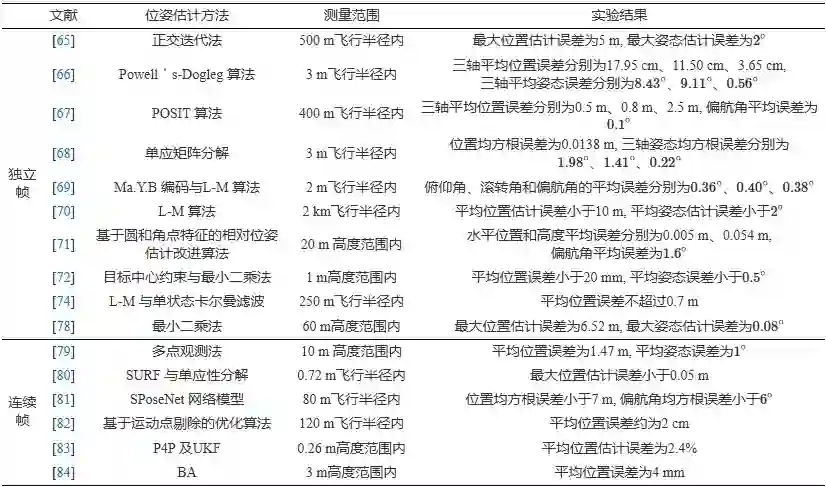
表 4 典型的单目视觉位姿估计方法梳理 综上所述, 在基于单目视觉的位姿估计研究中, 基于独立帧的位姿估计方法避免了多帧图像之间特征匹配的复杂运算, 运算效率较高, 但由此也带来了观测结果连续性较差、鲁棒性较弱等弊端, 并且无法表达相对运动的趋势. 由于能够利用序列帧所蕴含的时空相关性信息, 基于连续帧的位姿估计方法是未来基于视觉的相对位姿估计研究的主要方向, 但对于图像帧缺失、目标不规则运动、非合作场景着陆等问题, 目前仍没有非常成熟的解决方案。 5. 视觉与惯性融合的位姿估计研究现状
然而, 在先验条件缺失的情况下, 仅采用单目视觉实现1 km以上距离的自主着陆具有较大的挑战性. 为了保证着陆的自主性, 现有的解决方案是至少需要惯性信息来获取初始的估计[85]. 基于单目视觉的位姿估计还无法满足无人机自主着陆的精度需求, 究其原因是还面临着以下瓶颈:
-
一般的中大型无人机着陆场景具有高程、视距、景深变化较大的特点, 由此易导致图像特征平面化、绝对尺度信息丢失等问题;
-
对于无人机着舰等移动平台着陆场景, 一方面移动目标的绝对地理信息无法获取, 另一方面海面背景具有弱纹理的特点, 此时重投影误差包含较大噪声, 导致视觉测量会产生漂移、歧义等问题, 还需要引入额外的约束来校正视觉测量的尺度信息;
-
视觉传感器因其空域分辨率(即数据更新频率) 和时域分辨率(即图像分辨率) 十分有限, 难以有效应对较高动态性下的着陆场景, 如高超声速无人机的着陆等;
-
在复杂气象条件下, 如天气、光照等因素的变化都会带来图像质量下降等问题, 难以保证对着陆场的稳定跟随。
事实上, 现有的着陆导航系统如GNSS 等已经能够引导无人机完成一般情况下的着陆. 然而, 在信号拒止、恶劣气象、电磁干扰等极端条件下, 单一的信息源难以提供自主着陆所需的位置、姿态信息. 自主着陆系统从单一信息源类型发展到多源信息融合是必然趋势[86]。
5.1 视觉与异源信息融合的方式
国内外很多学者采用多源信息融合的方案来提升视觉测量效果, 利用机载传感器之间的互补性, 引入异源异质传感器的观测信息作为视觉观测信息的约束, 提高位姿估计的精度和鲁棒性。
区别于其他传感器信息, 视觉信息具有多层级、多维度的特点, 如表5所示, 从信息融合中视觉信息源的角度出发, 其参与融合的方式可以分为三个层级: 1) 像素级. 像素级融合对于多源信息的配准精度具有较高要求, 因此各个融合的传感器所提供的信息之间具有精确到一个像素的配准精度, 其最大的优点是可以提供位姿级和特征级融合所不具备的细节信息, 而缺点则是由于像素级融合要求各传感器提供的信息之间具有像素级的配准精度, 因此一般只适用于同质传感器之间的融合, 具有较大的局限性. 2) 位姿级. 位姿级融合的优缺点与像素级融合恰好相反, 由于其传感器可以是异质传感器, 因此对信息预处理的要求往往较高, 而正因如此, 该融合方式下各传感器所提供的信息更趋于同质化, 能够采用相似的度量标准, 相比于像素级和特征级方式还需进行信息匹配与连接交互等处理, 该融合方式下的算法复杂度一般更低. 3) 特征级. 特征级融合是以上两种融合的折中方式, 兼具两者的优缺点。

惯性导航设备具有和机器视觉同样无源、自主及抗干扰能力强等优势. 在保证自主性前提下, 尤其针对信号拒止、恶劣气象、电磁干扰等极端着陆条件, 基于视觉与惯性融合是目前实现无人机自主着陆最有效的信息融合手段: 一方面, 视觉与惯性融合利用惯性信息采样频率高的特点, 可以提高系统的输出频率, 并且能够有效应对高速运动场景; 另一方面, 视觉和惯性信息融合可以提高视觉的鲁棒性, 能够有效解决单目视觉尺度不可观测的问题. 此外, 视觉信息也能有效抑制惯性导航设备的积分漂移等问题. 按照融合框架划分, 目前主流的视觉与惯性信息融合方法主要包括基于滤波、基于优化以及基于深度学习的视觉与惯性融合方法。
5.2.1 基于滤波的融合方法
基于滤波的融合方法中最为典型的是卡尔曼滤波, 它是一种从噪声测量中估计系统误差状态的最优估计器, 在视觉与惯性融合中具备以下优势: 其一, 在现实系统应用中, 卡尔曼滤波更新过程的执行速度低于预测速度, 因此适用于输出数据频率不同的多传感器信息融合; 其二, 卡尔曼滤波适用于互补配置, 能够将其中具有不同噪声特性的相同信号的冗余测量结合起来, 以作为最小化误差的手段; 其三, 惯性传感器的累积误差通常出现在传感器输出的低频部分, 而机器视觉等传感器能够提供良好的低频特性但容易产生高频噪声, 卡尔曼滤波能够有效利用外部源准确的低频数据从中受益, 从而使惯导的长期累积误差得到抑制. 针对GNSS 拒止条件下无人机自主着陆的需求, Deng等[87]提出一种基于标准线性卡尔曼滤波器的视觉/惯性融合方法, 该方法利用IMU、下视单目相机和超声波测距仪构成视觉运动约束, 该约束实现了速度矢量与连续帧之间的观测点匹配, 并采用Mean Shift 算法来检测异常值以及选择最佳匹配点, 然后使用标准线性卡尔曼滤波器实现速度估计. 王妮[88]提出基于卡尔曼滤波器的惯导与雷达高度计和视觉传感器的多源信息融合方法, 将更新频率较高的雷达高度计测量得到的高度信息、惯导输出的位姿信息作为卡尔曼滤波器时间更新阶段的测量值进行时间更新, 更新频率较低的视觉测量值作为系统的测量值, 完成系统的测量更新, 同时根据惯导误差模型建立累积误差修正方案, 来提高无人机位姿估计的精度。
然而, 由于卡尔曼滤波建立在线性模型基础上, 为了更好地应用于无人机着陆导航等非线性系统, 国内外学者又引入了扩展卡尔曼滤波(Extended Kalman filter, EKF)、无迹卡尔曼滤波(Unscented Kalman filter, UKF) 等方法. 孔维玮[89]提出一种基于 EKF 的多传感器信息融合位姿估计算法, 该算法基于多传感器信息, 结合舰基无人机着舰导引系统的平台转动信息, 并对舰船甲板受海浪、海风影响的运动进行分析, 实现对目标无人机的位姿估计. 为了提高在低照度、GNSS 信号拒止下的位姿估计精度, Zhang 等[90]提出一种基于平方根无迹卡尔曼滤波 (Square-root unscented Kalman filter, SR_UKF) 的视觉/惯性融合方法, 联合视觉与惯性状态共同构建运动方程和观测方程, 利用惯性的尺度度量信息来辅助单目视觉的尺度估计, 为固定翼无人机提供着陆段无漂移的位姿估计, 然而该方法的视觉位姿估计依靠 LSD 线检测器提取着陆跑道的边缘特征, 难以适用于纹理复杂、跑道信息缺失等场景. 针对高海况下着舰位姿估计的高度非线性过程和观测模型, Nicholson 等[91]提出一种基于 UKF 的视觉/惯性融合甲板状态估计方法, 先把解码AprilTag 得到的旋转矩阵映射到本征旋转矩阵, 再从中构建四元数, 然后通过 UKF 融合视觉和惯导来计算相对位姿, 这减少了由于相机标定误差导致的甲板姿态估计误差. 针对非合作场景下的跑道着陆, 匈牙利计算机科学与控制研究所的Gróf 等[92]提出一种基于时延卡尔曼滤波 (Delayed-error-state Kalman filter, ESKF) 的视觉/惯性/气压计的融合方法, 采用 ESKF 解决图像信息在获取与处理之间因动态传播导致的误差传播延迟问题, 并论证了该着陆系统在非合作场景下的适用性. Meng 等[93]提出一种基于视觉/惯性/雷达的无人机着舰位姿估计方法, 通过引入舰载雷达信号提供舰船的运动信息以提升高海况下着陆点的预测精度, 并采用联邦滤波器实现信息融合, 包括两个局部滤波器(分别用于视觉/惯性、雷达/惯性融合) 及一个主滤波器, 保证了系统的高输出频率. 针对无人机移动平台回收的应用场景, 尚克军等[94]提出一种惯性/视觉位姿估计算法, 首先设计多个二维码构建非共面二维码序列, 使用非共面3D-2D 点对打破位姿解算特征点的共面约束, 然后采用极小平面位姿估计算法 (IPPE) 进行平面二维码位姿估计, 并融合惯性信息引入姿态约束, 最后采用 L-M 算法进行位姿优化, 该算法相较于OpenCV 库中的IPPE 函数消除了位姿解算歧义, 提升了定位精度与鲁棒性。
针对无人机大机动飞行状态时, 受气候、光线及合作标识遮挡等因素影响, 组合导航系统的误差大、状态发散等问题, 黄卫华等[95]提出一种基于灰色模型和改进粒子滤波的无人机视觉与惯性融合定位算法. 首先, 利用灰色预测理论建立基于视觉的位姿解算数据模型, 当机载摄像头受到外界因素干扰时, 用灰色模型预测数据代替其原始位姿解算数据, 消除解算数据的误差及其带来的不利影响; 其次, 将萤火虫算法引入到粒子滤波算法中, 提高粒子滤波的精度并减少计算耗时; 然后, 采用改进的粒子滤波算法将基于视觉的位姿解算数据和惯性数据融合, 避免直接融合视觉解算信息和惯性数据产生额外误差. 算法平均耗时减少了0.06 s, 误差减小了 39%, 保证了无人机飞行过程中位姿估计的精确性和飞行状态的稳定性. 面向拒止环境和低照度条件下的着陆需求, Hecker 等[96]设计一套可见光/红外/惯导组合着陆导引系统, 该系统先利用图像匹配算法进行跑道检测并提取其边界线, 进行位姿的粗略估计, 然后通过时延滤波器引入惯导信息以提高位姿估计精度, 同时提升数据更新频率, 该系统在DA42 型无人机上成功完成了自主着陆验证。
5.2.2 基于优化的融合方法
然而, 滤波方法是基于一阶马尔科夫假设的, 并不能很好地利用过往信息. 处理全局传感器信息时有较大优势, 而处理着陆过程中随着时间变化的局部传感器信息时, 滤波方法是一种次优估计. 相比于滤波方法, 基于优化的融合方法将状态估计问题假设为多阶马尔科夫过程, 通过利用当前及过往的测量值优化当前和过往状态[97]。
针对直升机自主着陆中的状态估计问题, Dinh 等[98]提出一种基于流形优化的视觉/惯性融合方法, 该方法利用因子图描述惯性、视觉和着陆点状态的测量模型, 并将着陆点的状态引入损失函数, 利用基于流形的非线性优化融合惯性测量值和视觉关键帧的重投影误差. 考虑到面向高空、长航时的大型无人机, 惯性设备的累计误差会带来误差过大的问题, 并且惯性设备误差与视觉测量尺度误差之间存在耦合关系, 王大元等[99]提出一种惯性/激光测距/视觉融合的尺度估计方法, 在视觉/惯性系统中引入激光测距以进一步提升测量精度. 该方法分别建立激光测距、视觉/惯性系统误差更新模型, 采用因子图优化的方法对三种传感器测量值进行组合, 并详细分析了尺度误差在无人机平飞运动状态下的可观测性. 然而, 引入激光测距仪会降低原有视觉/惯性融合系统的隐蔽性, 并且激光测距的作用范围也较为有限, 随着测量距离的提升存在精度下降的问题。
5.2.3 基于深度学习的融合方法
基于深度学习的融合方法凭借具有参数学习与非线性模型拟合的能力, 面对低质量的数据预处理和运动建模具备较好的优化作用. 与擅长于从空间数据(如图像信息等) 中提取特征的CNN 不同, 循环神经网络 (Recurrent neural network, RNN) 是一种擅长于处理序列数据(如惯性信息等) 的模型. 自 2017 年 Clark 等[100]首次将 CNN-RNN 结构应用于视觉/惯性融合以来, 该结构因具备从图像序列数据中提取丰富的视觉特征和时序特征的极佳能力, 成为了基于深度学习的融合方法中采用的主流手段。
在处理长序列信息时, RNN 的反向传播训练易产生梯度消失的问题. LSTM 网络[101]是RNN 的一种变体结构, 通过引入门机制和细胞状态, 能够学习到长期依赖信息, 有效解决了RNN 的梯度消失问题. Baldini 等[102]提出一种基于深度学习的视觉/惯性无人机自主导航与着陆的姿态估计方法, 该方法采用ResNet18 对图像数据编码并输出视觉特征向量, 又利用LSTM 网络处理两个连续图像帧之间的批量惯性数据(包括加速度和角速度), 输出惯性特征向量, 然后通过一个全连接层将视觉与惯性数据合并成无人机的运动特征向量, 最后采用一个核心LSTM 网络将视觉与惯性数据融合得到位姿测量结果. 该网络具有鲁棒性及效率高的优势, 并且能够嵌入到控制回路中, 对于提升无人机自主飞行中的安全性和鲁棒性有着重要的意义. 在GNSS 拒止环境下固定翼无人机自主着陆的高度估计研究中, Zhang 等[103]提出一种端到端的视觉/惯性融合高度估计网络VIAE-Net, 该网络首先通过视觉特征编码器CNN 从图像ROI 中提取视觉特征, 采用LSTM 网络提取惯性信息中的时序特征, 再利用注意力机制以相似度为指标对特征进行加权融合, 最后利用BiLSTM 网络从融合特征中解算获得高度估计值, 该网络的高度测量误差不超过1%D, 相比其他深度学习方法精度提高了3∼10 倍. 针对传统视觉/惯性导航在着陆位姿估计中对相机校准和同步要求严苛的问题, 王浩[104]提出一种基于深度学习的视觉/惯性融合网络模型, 首先采用FlowNet 提取得到相邻时刻图像间的光流差异信息, 并将此信息展开铺平得到此阶段的光流特征, 惯性特征则是采用一个小型LSTM 网络提取, 然后将光流特征和惯性特征对齐合并后作为一个大型LSTM 网络的输入, 并采集融合后的时序特征, 最后经过一个全连接层降维和特征压缩后, 计算获得这两帧图像之间的相对位姿, 该网络模型对于大机动飞行的位姿估计具有较好的适应性。
5.3 小结
以上几类基于滤波、基于优化以及基于深度学习的视觉与惯性融合位姿估计典型方法及实验结果等梳理如表6所示. 分析表6可知, 对于50 m以上的着陆测量范围, 三类方法均具有较好的位姿估计效果, 位置估计误差基本不超过1%, 姿态估计误差不超过1∘ ; 对于50 m以内的着陆测量范围, 三类融合方法的位置估计误差不超过10%, 姿态估计误差基本不超过5∘ . 总体来看, 基于滤波的融合方法具有更优的位姿估计效果, 并且类内方法的效果差异较小, 基于优化和基于深度学习的融合方法目前尤其在姿态估计上没有明显优势。
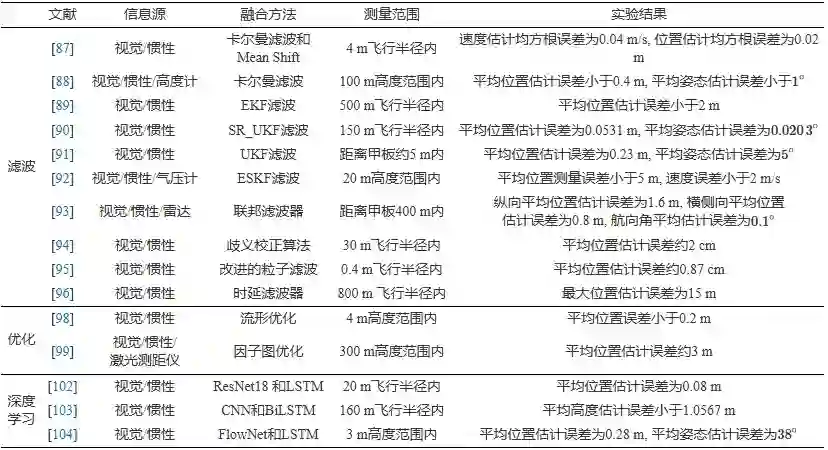
表 6 典型的视觉/惯性融合位姿估计方法梳理 综上可知, 与仅依靠视觉信息的位姿估计方法相比, 基于视觉与惯性融合的位姿估计方法是突破视觉在大规模场景下自主着陆应用难题的有效手段. 遵循奥卡姆剃刀原理, 卡尔曼等滤波方法仍是视觉与惯性融合的主流手段. 相比于滤波方法, 基于优化的融合方法将状态估计问题假设为多阶马尔科夫过程, 能够更好地通过利用历史测量值优化当前状态. 基于深度学习的融合方法具备从图像序列数据中提取丰富的视觉特征和时序特征的极佳能力, 但与基于优化的融合方法一样, 都存在收敛速度慢的弊端. 随着未来边缘设备性能的进步以及对位姿估计精度提升的需求, 基于优化、深度学习的融合方法会有更大的应用前景。 6. 总结与展望
机器视觉是未来无人机实现自主着陆的重要手段, 为了进一步支撑我国未来无人机自主化、智能化研究与发展, 本文立足于近十年来国内外的相关研究, 系统性地梳理了面向无人机自主着陆的视觉感知和位姿估计方法的研究进展, 归纳总结了代表性的研究方法及成果. 然而, 工程应用的复杂性使得目前的研究面临着诸多困难, 国内外的许多研究成果还停留在仿真阶段, 缺乏可靠的飞行验证和实际考证. 因此, 综合分析当前的技术现状, 基于视觉的自主着陆技术在未来的发展中需顺应以下发展趋势:
-
需适应着陆时高空、高速、大视距的特殊应用场景. 在高空、高速、大视场、大视距的着陆场景下, 变尺度目标、弱纹理背景及有限时空分辨率给视觉信息处理带来了许多局限性. 因此, 必须充分考虑着陆场景的特殊性及约束条件, 以适应特殊应用场景为前提发展无人机的自主着陆技术。
-
需满足可靠的、鲁棒的、高精度的位姿估计要求. 参考美国 FAA 给出的着陆误差标准可知, 军用无人机的着陆位姿估计精度要求均在米级, 能否获取准确、鲁棒、可靠的位姿参数是实现自主着陆的关键. 因此, 必须立足于位姿估计的要求来发展自主着陆技术, 即需满足其可靠性、鲁棒性、准确性。
-
需符合无人机自主化、智能化的未来发展方向. 根据美国 DARPA 提出的无人机发展路线, 无人机自主性和智能化是未来的发展趋势, 而自主着陆技术恰是提升无人机自主性等级的一项关键技术. 同时, 充分有效地利用机载多源信息来实现自主着陆, 对于提升无人机的自主性和智能化具有重大意义. 因此, 寻找一条符合无人机未来发展趋势的路线是发展无人机自主着陆技术的正确方向。
立足于以上总结的未来发展需求, 基于本文所聚焦的关键技术, 机器视觉在面向无人机自主着陆的应用上仍面临着诸多挑战, 从提升基于视觉的位姿估计算法的准确性、实时性和鲁棒性出发, 该技术的未来发展方向可归纳如下:
-
提升对高分辨率图像的处理效率. 采用高分辨率图像是扩大无人机自主着陆技术适用范围最直接有效的方法, 采用高分辨率图像能够提升大范围视场下视觉位姿估计的精确性, 但往往面临着计算量巨大、实时性差的问题. 由于机载平台计算资源有限, 视觉算法轻量化是能够实现在边缘设备部署的重要前提, 一方面, 高效的视觉算法能够加快输出频率, 提高系统响应速度; 另一方面, 未来边缘设备算力的提升会进一步拓展高分辨率图像的应用空间。
-
提升非合作场景下的着陆能力. 非合作场景指着陆场的位置不确定或其结构未知, 例如, 无人机需在除通用机场外的高速公路或农田等任何安全的着陆环境下应急着陆等特殊情况. 因此, 在非合作场景下着陆, 可认为基本无任何可利用的先验信息. 而目前的主流方法很大程度上都依赖于先验知识, 很难应对样本量不足或非合作的着陆场景, 不具备良好的泛化能力, 因此后续的研究应着眼于构建适用于多种着陆场景下视觉位姿估计的统一范式。
-
融合多模态信息. 目前, 采用单一的信息源实现无人机自主着陆仍存在一定的局限性, 可见光图像分辨率高但易受光照影响, 被动红外能够在夜间及恶劣气候条件下工作但图像信噪比低, 而惯性器件在着陆阶段存在较大的累积误差. 因此, 有效利用异源异构信息之间的优势互补十分必要, 通过融合多模态间信息以增强着陆场检测、相对位姿估计的可靠性, 对于提高无人机的全包线自主飞行能力也具有重要意义。
-
建立完备的算法基准评价体系. 目前, 基于视觉的无人机自主着陆技术尚未形成完备的评价体系, 本文调研的绝大多数研究采用仿真模拟数据来验证, 极少数研究采用了真实的飞行数据来进行算法验证. 而仿真平台的渲染效果、传感器误差模型、数据存储格式的差异, 飞行测试平台的性能及传感器的精度、实验环境等差异, 都使得各项研究的评价基准不统一, 因此建立一套典型着陆场景下包含机载图像、传感器参数及评价指标等内容的基准测试体系十分必要。
转载丨“人工智能技术与咨询”公众号


