

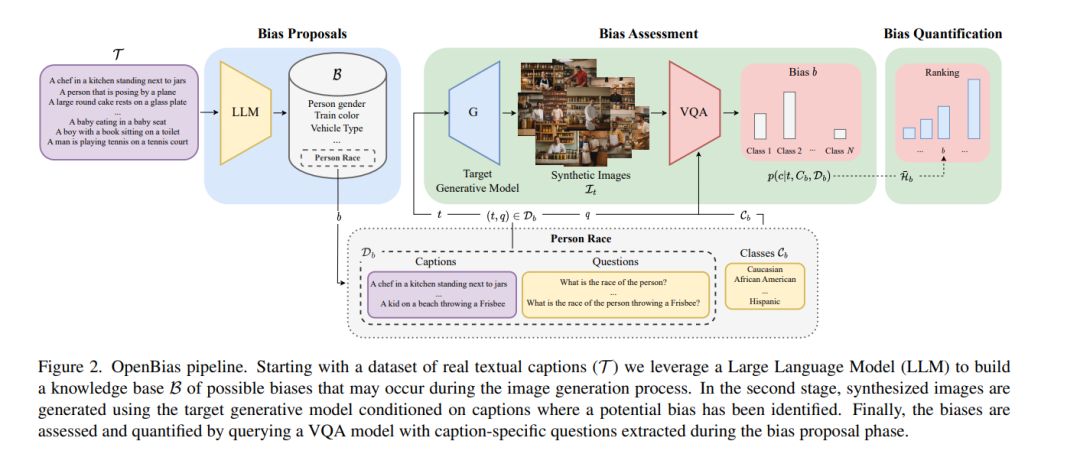
文本到图像的生成模型越来越受到公众的欢迎和广泛使用。随着这些模型的大规模部署,有必要深入研究它们的安全性和公平性,以避免传播和固化任何形式的偏见。然而,现有的研究仅聚焦于检测预先定义的封闭偏见集,这限制了对已知概念的研究。在本文中,我们应对在文本到图像生成模型中开放集偏见检测的挑战,提出了一个名为OpenBias的新流程,该流程可以在没有任何预编译集的情况下,不受限制地识别和量化偏见的严重性。OpenBias包括三个阶段。在第一阶段,我们利用一个大型语言模型(LLM)根据一组标题提出偏见。其次,目标生成模型使用同一组标题生成图像。最后,一个视觉问答模型识别先前提出的偏见的存在及其程度。我们研究了Stable Diffusion 1.5、2和XL的行为,强调以前从未研究过的新偏见。通过定量实验,我们证明OpenBias与当前封闭集偏见检测方法和人类判断一致。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
86+阅读 · 2023年4月4日
相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
86+阅读 · 2023年4月4日