

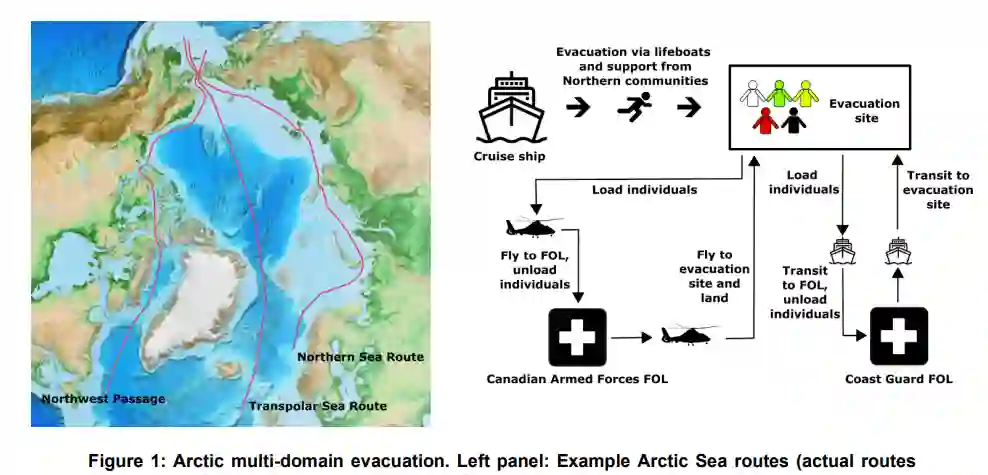
本文研究了这样一种情景:大量处于不同程度医疗困境的人员被困在偏远地区(如北极),必须进行疏散。在此背景下,研究了一种多域行动,即通过直升机或船只两种方式之一进行人员疏散,每种方式都有各自的能力限制。这项研究的目的是确定一种决策策略,其目标是最大限度地增加幸存者人数。为了实现这一目标,我们需要寻求一种策略,在整个行动过程中有效协调直升机撤离和轮船撤离的选择。我们的贡献有两个方面。首先,我们将多领域大规模疏散行动表述为马尔可夫决策过程。其次,由于 "维度诅咒"(curse of dimensionality)使得精确方法不适用,我们采用了人工智能框架,即强化学习(RL),也称为运筹学中的近似动态规划(ADP),来学习近乎最优的策略。利用基于状态聚合的价值函数近似值,我们设计了一种 ADP 算法,以便在具有代表性的规划场景中学习策略。然后,我们在一系列测试场景中应用该策略,并将结果与非协调基准策略进行比较。虽然我们学习到的策略并没有优于所有基准,但我们的结果表明了人工智能可如何用于评估候选策略,并在多领域行动中提供决策支持。
成为VIP会员查看完整内容
相关内容

Arxiv
153+阅读 · 2023年3月29日

相关VIP内容
相关资讯
相关论文
Arxiv
153+阅读 · 2023年3月29日